






参考:http://blog.csdn.net/xia562653223/article/details/18811661#
公平调度器是由facebook贡献的,适合于多用户共享集群的环境的调度器,其吞吐率高于FIFO,
1、公平调度介绍
公平调度器按资源池(pool)来组织作业,并把资源公平的分到这些资源池里。默认情况下,每一个用户拥有一个独立的资源池,以使每个用户都能获得一份等同的集群资源而不管他们提交了多少作业。按用户的 Unix 群组或作业配置(jobconf)属性来设置作业的资源池也是可以的。在每一个资源池内,会使用公平共享(fair sharing)的方法在运行作业之间共享容量(capacity)。用户也可以给予资源池相应的权重,以不按比例的方式共享集群。
除了提供公平共享方法外,公平调度器允许赋给资源池保证(guaranteed)最小共享资源,这个用在确保特定用户、群组或生产应用程序总能获取到足够的资源时是很有用的。当一个资源池包含作业时,它至少能获取到它的最小共享资源,但是当资源池不完全需要它所拥有的保证共享资源时,额外的部分会在其它资源池间进行切分。
主要特点如下:
Ø 支持多用户多队列
Ø 资源公平共享(公平共享量由优先级决定)
Ø 保证最小共享量
Ø 支持时间片抢占
Ø 限制作业并发量,以防止中间数据塞满磁盘
2、配置公平调度器
配置 yarn-site.xml
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/soft/hadoop/etc/hadoop/fair-allocation.xml</value>
</property>
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.fair.sizebasedweight</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.fair.assignmultiple</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.fair.max.assign</name>
<value>-1</value>
</property>
<property>
<name>yarn.scheduler.fair.locality.threshold.node</name>
<value>0.1</value>
</property>
<property>
<name>yarn.scheduler.fair.locality.threshold.rack</name>
<value>0.1</value>
</property>
配置 fair-allocation.xml
<?xml version="1.0"?>
<allocations>
<queue name="root">
<minResources>10000mb,10vcores</minResources>
<maxResources>90000mb,100vcores</maxResources>
<maxRunningApps>50</maxRunningApps>
<weight>2.0</weight>
<schedulingMode>fair</schedulingMode>
<aclSubmitApps> </aclSubmitApps>
<aclAdministerApps> </aclAdministerApps>
<queue name="queue1">
<minResources>10000mb,10vcores</minResources>
<maxResources>90000mb,100vcores</maxResources>
<maxRunningApps>50</maxRunningApps>
<weight>2.0</weight>
<schedulingMode>fair</schedulingMode>
<aclAdministerApps>ubuntu,ubuntu</aclAdministerApps>
<aclSubmitApps>ubuntu,ubuntu</aclSubmitApps>
</queue>
</queue>
<user name="ubuntu">
<maxRunningApps>30</maxRunningApps>
</user>
<userMaxAppsDefault>5</userMaxAppsDefault>
</allocations>
3、测试
测试脚本test.sh
#!/bin/bash
if [ $# -lt 1 ] ; then
echo 'Usage: test.sh n'
exit -1
fi
n=$1
hadoop fs -rmr /out*
#for i in $(seq 1 $n)
for (( i=1;i<=$n;i++ ))
do
echo "/out/${i}"
nohup hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount -Dmapred.job.queue.name=root.queue1 /profile /out${n} &
done
echo "complete"
上述脚本主要是运行hadoop自带例子wordcount,在运行之前需要就测试数据上传到hdfs上,这里我们为了方便将/etc/profile上传到了hdfs的根目录下: hadoop fs -put /etc/profile /
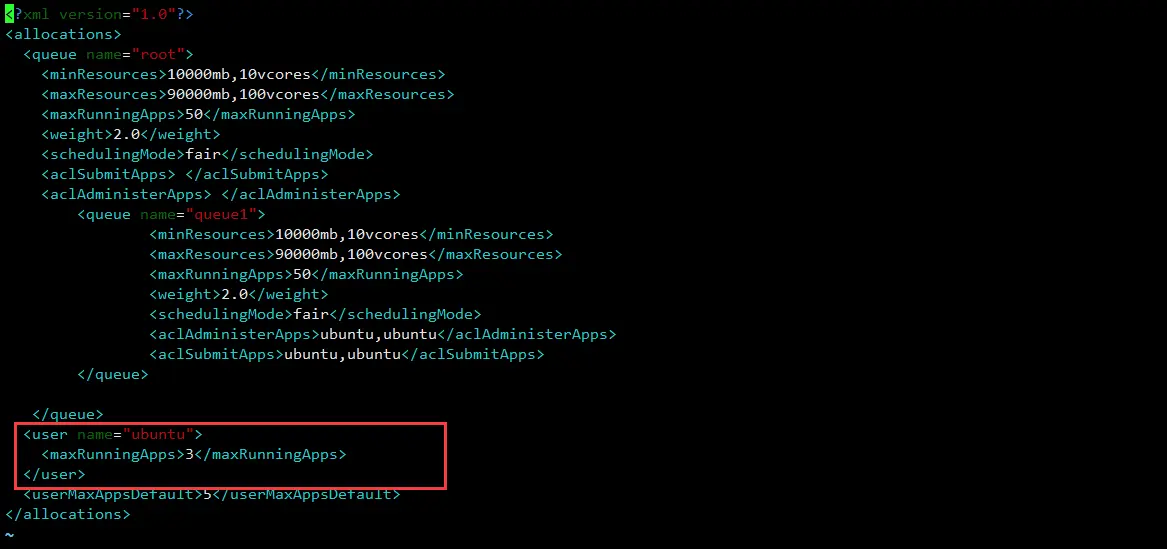
这里为了测试,将ubuntu的最大提交任务数设置为3个,便于测试。
./test.sh 4
手动提交4个任务,得到的结果如下图所示:
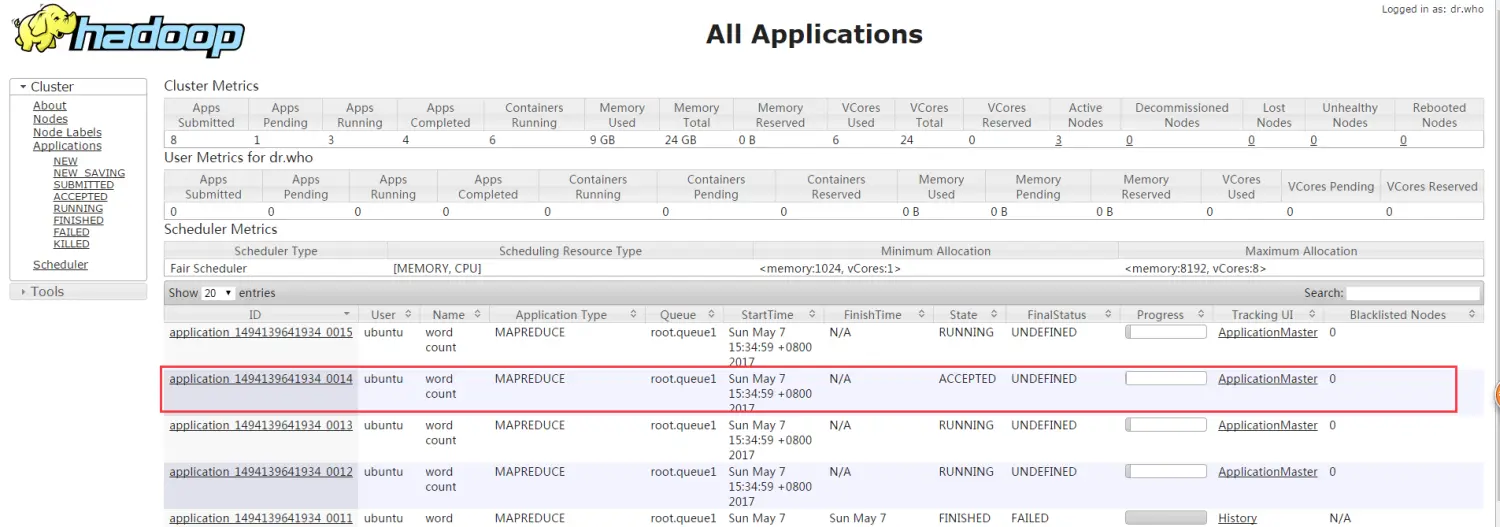

从图二可以看出有三个任务处于激活状态,1个处于等待状态。到此,公平调度器设置成功。
(注:由于集群采用的是默认配置三个slave几点,所以默认只有24个VCores,所能获取的最大资源也是默认的,从而配额文件fair-allocation.xml中配置的最大资源未生效 )














 283
283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









