






复制和多路复用

分析:使用Flume-1监控文件变动,Flume-1将变动内容传递给Flume-2,Flume-2负责存储到HDFS,同时FLume-1将变动内容传递给Flume-3,Flume-3负责
1-2:taildir source -> memory channel -> avro sink
2-HDFS:avro source -> memory channel -> hdfs sink
1-3: taildir source -> memory channel -> avro sink
3-Local FileSystem:avro source -> memory channel -> file roll sink

Avro 是由 Hadoop 创始人 Doug Cutting 创建的一种语言无关的数据序列化和 RPC 框架。
RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议
Flume-1的配置文件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# Describe/configure the source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /home/bd/tmp/group1Test/log
a1.sources.r1.positionFile = /home/bd/tmp/group1Position/position.json
# set channel selector
a1.sources.r1.selector.type = replicating
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop113
a1.sinks.k1.port = 4441
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop113
a1.sinks.k2.port = 4442
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
Flume-2配置文件
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = avro
a2.sources.r2.bind = hadoop113
a2.sources.r2.port = 4441
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop113:9000/group1/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次,到了一定时间了也会去flush
a2.sinks.k2.hdfs.batchSize = 500
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件,60s
a2.sinks.k2.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
Flume-3配置文件
# Name the components on this agent
a3.sources = r2
a3.sinks = k2
a3.channels = c2
# Describe/configure the source
a3.sources.r2.type = avro
a3.sources.r2.bind = hadoop113
a3.sources.r2.port = 4442
# Sink
a3.sinks.k2.type = file_roll
# 这个目录要提前创建好,否则会报错
a3.sinks.k2.sink.directory = /home/bd/tmp/group1FileRoll
# Use a channel which buffers events in memory
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r2.channels = c2
a3.sinks.k2.channel = c2
启动时,要先启动下游的Flume,不然如果上游是avro sink的话,先启动上游的话,会出现连接不上avro的错误,因为avro sink相当于客户端,avro source相当于服务端,虽然会有重试的机制,但是最好还是先启动下游Flume,再启动上游Flume。
本案例,先启动Flume-2和Flume-3,最后启动Flume-1。
为log文件依次追加hello和word

查看本地文件内容:
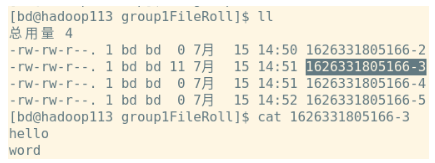
查看HDFS文件内容:

均传输成功了。
备注:本地文件默认30s滚动一次,就算没有内容也会滚动一个空的文件,而HDFS则不会滚动空文件。














 869
869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









