






Spark核心编程
RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
1、弹性:
存储的弹性: 内存与磁盘的自动切换;
容错的弹性: 数据丢失可以自动恢复;
计算的弹性: 计算出错重试机制;
分片的弹性: 可根据需要重新分片。
2、分布式: 数据存储在大数据集群不同节点上
3、数据集: RDD 封装了计算逻辑,并不保存数据
4、数据抽象: RDD 是一个抽象类,需要子类具体实现
5、不可变: RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
6、可分区、并行计算
基础编程
RDD序列化
闭包检查
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor端执行。
那么在 scala 的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给 Executor端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列化,这个操作我们称之为闭包检测。Scala2.12 版本后闭包编译方式发生了改变
object TestTransformForeach1 {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val user = new User
// SparkException: Task not serializable
// NotSerializableException: com.starnet.spark.core.rdd.action.TestTransformForeach1$User
rdd.foreach(num => println("age is " + (user.age + num)))
// RDD算子中传递的函数是会包含闭包操作的,那么就会进行检测功能
// 闭包检测
sc.stop()
}
// class User extends Serializable {
// var age: Int = 30
// }
// 样例类在编译时,会自动混入序列化的特质(实现可序列化接口)
case class User() {
var age: Int = 30
}
}
序列化方法和属性
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor端执行
object TestTransformSerial {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello spark", "hadoop", "test"))
val search = new Search("h")
search.getMatch1(rdd).collect.foreach(println)
search.getMatch2(rdd).collect.foreach(println)
sc.stop()
}
// 查询对象
// 类的构造参数其实就是类的属性
// 构造参数需要进行闭包检测,其实就等同于类进行闭包检测
class Search(query:String) extends Serializable {
def isMatch(s: String): Boolean = {
s.contains(query)
// s.contains(this.query)
}
// 函数序列化案例
def getMatch1 (rdd: RDD[String]): RDD[String] = {
rdd.filter(isMatch)
}
// 属性序列化案例
def getMatch2(rdd: RDD[String]): RDD[String] = {
rdd.filter(_.contains(query))
// 这样的话是不需要序列化的,因为s与Search没有关系了
// val s = query
// rdd.filter(_.contains(s))
}
}
}
Kryo 序列化框架
参考地址: https://github.com/EsotericSoftware/kryo
Java 的序列化能够序列化任何的类。但是比较重(字节多),序列化后,对象的提交也比较大。Spark 出于性能的考虑,Spark2.0 开始支持另外一种 Kryo 序列化机制。Kryo 速度是 Serializable 的 10 倍。
当 RDD 在 Shuffle 数据的时候,简单数据类型、数组和字符串类型已经在 Spark 内部使用 Kryo 来序列化,其他类型的数据还不能使用Kryo序列化。
想要使用 Kryo 序列化,也要继承 Serializable 接口。
RDD依赖关系
RDD血缘关系
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage(血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
相邻的两个RDD之间的关系称为依赖关系,即新的RDD依赖于旧的RDD
多个连续的RDD的依赖关系,称之为血缘关系
RDD是不会保存数据的,为了提高容错性,需要将每个RDD的关系保存下来(每个
RDD都会保存自己之前的血缘关系),一旦出现错误,可以根据血缘关系将数据源重新读取计算。

val lines: RDD[String] = sc.textFile("datas/spark-core/wordCount/1.txt")
println(lines.toDebugString)
println("11111111111111111")
val words: RDD[String] = lines.flatMap(_.split(" "))
println(words.toDebugString)
println("22222222222222222222")
val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))
println(wordToOne.toDebugString)
println("333333333333333333333")
val wordGroup: RDD[(String, Iterable[(String, Int)])] = wordToOne.groupBy(word => word._1)
println(wordGroup.toDebugString)
println("4444444444444444444")
val wordCount: RDD[(String, Int)] = wordGroup.map {
case (word, list) => {
val tuple = list.reduce((a, b) => {
(word, a._2 + b._2)
})
tuple
}
}
wordCount.collect.foreach(println)
// 结果如下:
(1) datas/spark-core/wordCount/1.txt MapPartitionsRDD[1] at textFile at TestLineAge.scala:13 []
| datas/spark-core/wordCount/1.txt HadoopRDD[0] at textFile at TestLineAge.scala:13 []
11111111111111111
(1) MapPartitionsRDD[2] at flatMap at TestLineAge.scala:17 []
| datas/spark-core/wordCount/1.txt MapPartitionsRDD[1] at textFile at TestLineAge.scala:13 []
| datas/spark-core/wordCount/1.txt HadoopRDD[0] at textFile at TestLineAge.scala:13 []
22222222222222222222
(1) MapPartitionsRDD[3] at map at TestLineAge.scala:21 []
| MapPartitionsRDD[2] at flatMap at TestLineAge.scala:17 []
| datas/spark-core/wordCount/1.txt MapPartitionsRDD[1] at textFile at TestLineAge.scala:13 []
| datas/spark-core/wordCount/1.txt HadoopRDD[0] at textFile at TestLineAge.scala:13 []
333333333333333333333
(1) ShuffledRDD[5] at groupBy at TestLineAge.scala:25 []
+-(1) MapPartitionsRDD[4] at groupBy at TestLineAge.scala:25 []
| MapPartitionsRDD[3] at map at TestLineAge.scala:21 []
| MapPartitionsRDD[2] at flatMap at TestLineAge.scala:17 []
| datas/spark-core/wordCount/1.txt MapPartitionsRDD[1] at textFile at TestLineAge.scala:13 []
| datas/spark-core/wordCount/1.txt HadoopRDD[0] at textFile at TestLineAge.scala:13 []
4444444444444444444
RDD依赖关系
这里所谓的依赖关系,其实就是两个相邻 RDD 之间的关系
可以通过rdd.dependencies来获取RDD的依赖关系
val lines: RDD[String] = sc.textFile("datas/spark-core/wordCount/1.txt")
println(lines.dependencies)
println("11111111111111111")
val words: RDD[String] = lines.flatMap(_.split(" "))
println(words.dependencies)
println("22222222222222222222")
val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))
println(wordToOne.dependencies)
println("333333333333333333333")
val wordGroup: RDD[(String, Iterable[(String, Int)])] = wordToOne.groupBy(word => word._1)
println(wordGroup.dependencies)
println("4444444444444444444")
// 结果如下:
List(org.apache.spark.OneToOneDependency@4745e9c)
11111111111111111
List(org.apache.spark.OneToOneDependency@1981d861)
22222222222222222222
List(org.apache.spark.OneToOneDependency@6b1dc20f)
333333333333333333333
List(org.apache.spark.ShuffleDependency@507d64aa)
4444444444444444444
新的RDD的一个分区的数据依赖与旧的RDD的一个分区的数据,且各个分区一一对应依赖,称之为OneToOne依赖又称为窄依赖
新的RDD的一个分区的数据依赖与旧的RDD的多个分区的数据,称之为Shuffle依赖又称为宽依赖
RDD窄依赖
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用,窄依赖我们形象的比喻为独生子女。
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd)
RDD宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]]
RDD阶段划分
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。例如,DAG 记录了 RDD 的转换过程和任务的阶段。
OneToOneDependency
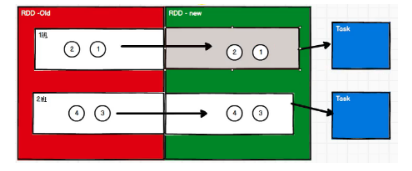
ShuffleDependency

当RDD中存在shuffle依赖时,阶段会自动增加一个,
阶段数量 = shuffle依赖数量 + 1(因为默认就会有一个阶段,ResultStage阶段,它会在最后执行)
RDD任务划分
RDD 任务切分为 :Application、Job、Stage 和 Task
Application:初始化一个 SparkContext 即生成一个 Application;
Job:一个 Action(行动) 算子就会生成一个 Job;
Stage:Stage 等于宽依赖(ShuffleDependency)的个数加 1;
Task:一个 Stage 阶段中,最后一个 RDD 的分区个数就是 Task 的个数,一个Stage阶段中任务的数量 = 当前阶段中最后一个RDD的分区数量。
Application->Job->Stage->Task 每一层都是 1 对 n 的关系。
在ShuffleMapStage中的任务叫做ShuffleMapTask,ResultStage阶段的任务叫做ResultTask
RDD持久化
RDD中不保存数据的,如果一个RDD需要重复使用,那么需要从头再次执行来获取数据,RDD可以重用,但是数据无法重用。
RDD对象的持久化操作,不一定是为了重用,在数据执行较长,或数据比较重要的场合也可以采用持久化操作
object TestPersist {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Persist")
val sc = new SparkContext(sparkConf)
val list = List("Hello Scala", "Hello Spark");
val rdd: RDD[String] = sc.makeRDD(list)
val flatRdd: RDD[String] = rdd.flatMap(_.split(" "))
val mapRdd: RDD[(String, Int)] = flatRdd.map(word => {
println("***********")
(word, 1)
})
// 持久化操作
// cache默认持久化的操作,只能将数据保存到内存中
// 如果想要保存到磁盘文件,需要更改存储级别
// 持久化操作必须在行动算子执行时完成的
// persist保存的文件,在作业执行完成之后会自动删除
// mapRdd.cache()
// mapRdd.persist()
// checkpoint需要落盘,需要执行检查点保存路径
// checkpoint保存的文件,当作业执行完毕之后不会被删除
// 一般保存路径都是在分布式存储系统:HDFS
sc.setCheckpointDir("checkpoint") // 设置保存路径,这里是本地,实际使用HDFS
mapRdd.checkpoint()
val reduceRdd: RDD[(String, Int)] = mapRdd.reduceByKey(_ + _)
reduceRdd.collect.foreach(println)
println("=========================")
val groupRDD: RDD[(String, Iterable[Int])] = mapRdd.groupByKey()
groupRDD.collect.foreach(println)
sc.stop()
// 未持久化的结果:
// ***********
// ***********
// ***********
// ***********
// (Hello,2)
// (Spark,1)
// (Scala,1)
// =========================
// ***********
// ***********
// ***********
// ***********
// (Hello,CompactBuffer(1, 1))
// (Spark,CompactBuffer(1))
// (Scala,CompactBuffer(1))
// 持久化的结果
// ***********
// ***********
// ***********
// ***********
// (Hello,2)
// (Spark,1)
// (Scala,1)
// =========================
// (Hello,CompactBuffer(1, 1))
// (Spark,CompactBuffer(1))
// (Scala,CompactBuffer(1))
}
}
RDD Cache 缓存
RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存,默认情况下会把数据以缓存在 JVM 的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算子时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
存储级别
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)

缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD 的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于 RDD 的一系列转换,丢失的数据会被重算,由于 RDD 的各个 Partition 是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部 Partition。
Spark 会自动对一些 Shuffle 操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点 Shuffle 失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用 persist 或 cache。
上面的DISK_2是副本的意思,表示两个副本,如果需要更多的副本,根据new StorageLevel(true, false, false, false, 2)自己去定义
object TestPersist {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Persist")
val sc = new SparkContext(sparkConf)
val list = List("Hello Scala", "Hello Spark");
val rdd: RDD[String] = sc.makeRDD(list)
val flatRdd: RDD[String] = rdd.flatMap(_.split(" "))
val mapRdd: RDD[(String, Int)] = flatRdd.map(word => {
println("***********")
(word, 1)
})
// 持久化操作
// cache默认持久化的操作,只能将数据保存到内存中
// 如果想要保存到磁盘文件,需要更改存储级别
// 持久化操作必须在行动算子执行时完成的
mapRdd.cache()
// mapRdd.persist()
val reduceRdd: RDD[(String, Int)] = mapRdd.reduceByKey(_ + _)
reduceRdd.collect.foreach(println)
println("=========================")
val groupRDD: RDD[(String, Iterable[Int])] = mapRdd.groupByKey()
groupRDD.collect.foreach(println)
sc.stop()
// 未持久化的结果:
// ***********
// ***********
// ***********
// ***********
// (Hello,2)
// (Spark,1)
// (Scala,1)
// =========================
// ***********
// ***********
// ***********
// ***********
// (Hello,CompactBuffer(1, 1))
// (Spark,CompactBuffer(1))
// (Scala,CompactBuffer(1))
// cache、persist以及cache+checkpoint持久化的结果
// ***********
// ***********
// ***********
// ***********
// (Hello,2)
// (Spark,1)
// (Scala,1)
// =========================
// (Hello,CompactBuffer(1, 1))
// (Spark,CompactBuffer(1))
// (Scala,CompactBuffer(1))
// 单独执行checkpoint持久化结果
// ***********
// ***********
// ***********
// ***********
// ***********
// ***********
// ***********
// ***********
// (Hello,2)
// (Spark,1)
// (Scala,1)
// =========================
// (Hello,CompactBuffer(1, 1))
// (Spark,CompactBuffer(1))
// (Scala,CompactBuffer(1))
}
}
RDD CheckPoint检查点
所谓的检查点其实就是通过将 RDD 中间结果写入磁盘
由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。
对 RDD 进行 checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发。
缓存和检查点区别
1)Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖。
2)Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存储在 HDFS 等容错、高可用的文件系统,可靠性高。
3)建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存中读取数据即可,否则需要再从头计算一次 RDD。
cache:将数据临时存在内存中,进行数据的重用;会在血缘关系中增加新的依赖,一旦出现问题,可以重头读取数据。
persist:将数据临时存储在磁盘文件中,进行数据的重用,涉及到磁盘的IO,性能较低,但是数据安全,如果作业执行完毕,临时保存的数据会丢失;会在血缘关系中增加新的依赖,一旦出现问题,可以重头读取数据。
checkpoint:将数据长久性的保存在磁盘文件中,进行数据的重用,涉及到磁盘的IO,性能较低,但是数据安全;为了保证数据安全,所以一般情况下,会独立再执行一次作业,为了能够提高效率,一般情况下,是需要和cache联合使用;执行过程中会切换血缘关系,并重新建立新的血缘关系,checkpoint相当于改变了数据源。
RDD分区器
Spark 目前支持 Hash 分区和 Range 分区,和用户自定义分区。
Hash 分区为当前的默认分区。
分区器直接决定了 RDD 中分区的个数、RDD 中每条数据经过 Shuffle 后进入哪个分区,进而决定了 Reduce 的个数。
➢ 只有 Key-Value 类型的 RDD 才有分区器,非 Key-Value 类型的 RDD 分区的值是 None
➢ 每个 RDD 的分区 ID 范围:0 ~ (numPartitions - 1),决定这个值是属于那个分区的。
Hash 分区:对于给定的 key,计算其 hashCode,并除以分区个数取余
Range 分区:将一定范围内的数据映射到一个分区中,尽量保证每个分区数据均匀,而且分区间有序
自定义分区
object TestPartition {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(
("wei", "caocao"),
("shu", "liubei"),
("wu", "sunquan"),
("wei", "caopi"),
))
rdd.partitionBy(new MyPartitioner(3)).saveAsTextFile("output")
sc.stop()
}
/**
* 自定义分区器
* 1、继承Partitioner
* 2、重写方法
*/
class MyPartitioner(var num: Int) extends Partitioner{
// 分区的数量
override def numPartitions: Int = num
// 根据数据的key值返回数据的分区索引,从0开始
override def getPartition(key: Any): Int = {
key match {
case "wei" => 0
case "shu" => 1
case _ => 2
}
}
}
}
// 结果如下
part-00000
(wei,caocao)
(wei,caopi)
part-00001
(shu,liubei)
part-00002
(wu,sunquan)
RDD文件读取与保存
Spark 的数据读取及数据保存可以从两个维度来作区分:文件格式以及文件系统。
文件格式分为:text 文件、csv 文件、sequence 文件以及 Object 文件;
文件系统分为:本地文件系统、HDFS、HBASE 以及数据库。
text 文件
// 读取输入文件
val inputRDD: RDD[String] = sc.textFile("input/1.txt")
// 保存数据
inputRDD.saveAsTextFile("output")
sequence 文件
SequenceFile 文件是 Hadoop 用来存储二进制形式的 key-value 对而设计的一种平面文件(FlatFile)。在 SparkContext 中,可以调用 sequenceFile[keyClass, valueClass](path)。
// 保存数据为 SequenceFile
dataRDD.saveAsSequenceFile("output")
// 读取 SequenceFile 文件
sc.sequenceFile[Int,Int]("output").collect().foreach(println)
object 对象文件
对象文件是将对象序列化后保存的文件,采用 Java 的序列化机制。可以通过 objectFile[T:ClassTag](path)函数接收一个路径,读取对象文件,返回对应的 RDD,也可以通过调用saveAsObjectFile()实现对对象文件的输出。因为是序列化所以要指定类型。
// 保存数据
dataRDD.saveAsObjectFile("output")
// 读取数据
sc.objectFile[Int]("output").collect().foreach(println)
// 保存
val rdd: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1),
("b", 2),
("c", 3),
("d", 4)
))
rdd.saveAsTextFile("output1")
rdd.saveAsObjectFile("output2")
rdd.saveAsSequenceFile("output3")
// 读取
println(sc.textFile("output1").collect.mkString(","))
println(sc.objectFile[(String, Int)]("output2").collect.mkString(","))
println(sc.sequenceFile[String, Int]("output3").collect.mkString(","))
// (a,1),(b,2),(c,3),(d,4)
// (a,1),(b,2),(c,3),(d,4)
// (a,1),(b,2),(c,3),(d,4)














 1643
1643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









