







RDD概念
RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现。RDD是Spark最核心的东西,它表示已被分区,不可变的并能够被并行操作的数据集合,不同的数据集格式对应不同的RDD实现。RDD必须是可序列化的。RDD可以cache到内存中,每次对RDD数据集的操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘IO操作
RDD可以横向多分区,当计算过程中内存不足时,将数据刷到磁盘等外部存储上,从而实现数据在内存和外存的灵活切换。可以说,RDD是有虚拟数据结构组成,并不包含真实数据体。
RDD的内部属性
通过RDD的内部属性,用户可以获取相应的元数据信息。通过这些信息可以支持更复杂的算法或优化。
一组分片(Partition),即数据集的基本组成单位
对于RDD来说,每个分片都会被一个task计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配的CPU Core的数据。
计算每个分片的函数
Spark中RDD的计算是以分片为单位的,通过函数可以对每个数据块进行RDD需要进行的用户自定义函数运算。函数会对迭代器进行复合,不需要保存每次计算的结果。
RDD之间的依赖关系
对父RDD的依赖列表,依赖还具体分为宽依赖和窄依赖,但并不是所有的RDD都有依赖。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
一个Partitioner,即RDD的分片函数
当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
分区列表,存储存取每个Partition的优先位置(preferred location)
对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
可选属性
key-value型的RDD是根据哈希来分区的,类似于mapreduce当中的Paritioner接口,控制key分到哪个reduce。
可选属性
每一个分片的优先计算位置(preferred locations),比如HDFS的block的所在位置应该是优先计算的位置。(存储的是一个表,可以将处理的分区“本地化”)
RDD的特点
- 创建:只能通过转换 ( transformation ,如map/filter/groupBy/join 等,区别于动作 action) 从两种数据源中创建 RDD 1 )稳定存储中的数据; 2 )其他 RDD。
只读:状态不可变,不能修改。
分区:支持使 RDD 中的元素根据那个 key 来分区 ( partitioning ) ,保存到多个结点上。还原时只会重新计算丢失分区的数据,而不会影响整个系统。
路径:在 RDD 中叫世族或血统 ( lineage ) ,即 RDD 有充足的信息关于它是如何从其他 RDD 产生而来的。
持久化:支持将会被重用的 RDD 缓存 ( 如 in-memory 或溢出到磁盘 )。
延迟计算:Spark 也会延迟计算 RDD ,使其能够将转换管道化 (pipeline transformation)。
操作:丰富的转换(transformation)和动作 ( action ) , count/reduce/collect/save 等。
执行了多少次transformation操作,RDD都不会真正执行运算(记录lineage),只有当action操作被执行时,运算才会触发。
RDD的优点
- RDD只能从持久存储或通过Transformations操作产生,相比于分布式共享内存(DSM)可以更高效实现容错,对于丢失部分数据分区只需根据它的lineage就可重新计算出来,而不需要做特定的Checkpoint。
- RDD的不变性,可以实现类Hadoop MapReduce的推测式执行。
- RDD的数据分区特性,可以通过数据的本地性来提高性能,这不Hadoop MapReduce是一样的。
- RDD都是可序列化的,在内存不足时可自动降级为磁盘存储,把RDD存储于磁盘上,这时性能会有大的下降但不会差于现在的MapReduce。
- 批量操作:任务能够根据数据本地性 (data locality) 被分配,从而提高性能。
RDD的存储与分区
- 用户可以选择不同的存储级别存储RDD以便重用。
- 当前RDD默认是存储于内存,但当内存不足时,RDD会spill到disk。
- RDD在需要进行分区把数据分布于集群中时会根据每条记录Key进行分区(如Hash 分区),以此保证两个数据集在Join时能高效。
- RDD根据useDisk、useMemory、useOffHeap、deserialized、replication参数的组合定义了以下存储级别:
//存储等级定义:
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(false, false, true, false) RDD的容错机制
RDD的容错机制实现分布式数据集容错方法有两种:数据检查点和记录更新
RDD采用记录更新的方式:记录所有更新点的成本很高。所以,RDD只支持粗颗粒变换,即只记录单个块(分区)上执行的单个操作,然后创建某个RDD的变换序列(血统 lineage)存储下来;
变换序列指,每个RDD都包含了它是如何由其他RDD变换过来的以及如何重建某一块数据的信息。因此RDD的容错机制又称“血统”容错。
要实现这种“血统”容错机制,最大的难题就是如何表达父RDD和子RDD之间的依赖关系。实际上依赖关系可以分两种,窄依赖和宽依赖。
窄依赖:子RDD中的每个数据块只依赖于父RDD中对应的有限个固定的数据块
宽依赖:子RDD中的一个数据块可以依赖于父RDD中的所有数据块。例如:map变换,子RDD中的数据块只依赖于父RDD中对应的一个数据块;groupByKey变换,子RDD中的数据块会依赖于多块父RDD中的数据块,因为一个key可能分布于父RDD的任何一个数据块中
将依赖关系分类的两个特性:
1. 窄依赖可以在某个计算节点上直接通过计算父RDD的某块数据计算得到子RDD对应的某块数据;宽依赖则要等到父RDD所有数据都计算完成之后,并且父RDD的计算结果进行hash并传到对应节点上之后才能计算子RDD。
2. 数据丢失时,对于窄依赖只需要重新计算丢失的那一块数据来恢复;对于宽依赖则要将祖先RDD中的所有数据块全部重新计算来恢复。
所以在“血统”链特别是有宽依赖的时候,需要在适当的时机设置数据检查点。也是这两个特性要求对于不同依赖关系要采取不同的任务调度机制和容错恢复机制。
Spark计算工作流
- 输入:在Spark程序运行中,数据从外部数据空间(例如,HDFS、Scala集合或数据)输入到Spark,数据就进入了Spark运行时数据空间,会转化为Spark中的数据块,通过BlockManager进行管理。
- 运行:在Spark数据输入形成RDD后,便可以通过变换算子fliter等,对数据操作并将RDD转化为新的RDD,通过行动(Action)算子,触发Spark提交作业。如果数据需要复用,可以通过Cache算子,将数据缓存到内存。
- 输出:程序运行结束数据会输出Spark运行时空间,存储到分布式存储中(如saveAsTextFile输出到HDFS)或Scala数据或集合中(collect输出到Scala集合,count返回Scala Int型数据)。
Spark的核心数据模型是RDD,但RDD是个抽象类,具体由各子类实现,如MappedRDD、ShuffledRDD等子类。Spark将常用的大数据操作都转化成为RDD的子类。




RDD编程模型
textFile算子从HDFS读取日志文件,返回“file”(RDD);filter算子筛出带“ERROR”的行,赋给 “errors”(新RDD);cache算子把它缓存下来以备未来使用;count算子返回“errors”的行数。RDD看起来与Scala集合类型 没有太大差别,但它们的数据和运行模型大相迥异。
val file = sc.textFile("hdfs://...")
val errors = file.filter(_.contains("ERROR"))
errors.cache()
errors.count()上面代码给出了RDD数据模型,并将上例中用到的四个算子映射到四种算子类型。Spark程序工作在两个空间中:Spark RDD空间和Scala原生数据空间。在原生数据空间里,数据表现为标量(scalar,即Scala基本类型,用橘色小方块表示)、集合类型(蓝色虚线 框)和持久存储(红色圆柱)。
下图描述了Spark运行过程中通过算子对RDD进行转换, 算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作。
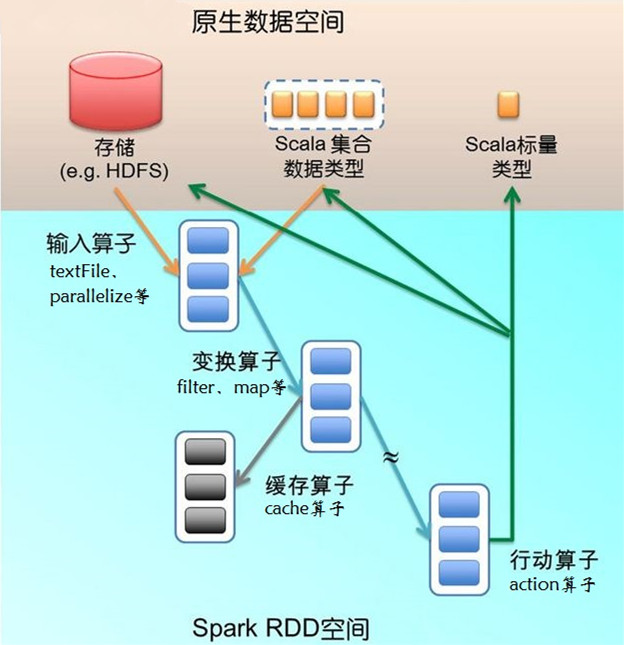
输入算子(橘色箭头)将Scala集合类型或存储中的数据吸入RDD空间,转为RDD(蓝色实线框)。输入算子的输入大致有两类:一类针对 Scala集合类型,如parallelize;另一类针对存储数据,如上例中的textFile。输入算子的输出就是Spark空间的RDD。
因为函数语义,RDD经过变换(transformation)算子(蓝色箭头)生成新的RDD。变换算子的输入和输出都是RDD。RDD会被划分 成很多的分区 (partition)分布到集群的多个节点中,图1用蓝色小方块代表分区。注意,分区是个逻辑概念,变换前后的新旧分区在物理上可能是同一块内存或存 储。这是很重要的优化,以防止函数式不变性导致的内存需求无限扩张。有些RDD是计算的中间结果,其分区并不一定有相应的内存或存储与之对应,如果需要 (如以备未来使用),可以调用缓存算子(例子中的cache算子,灰色箭头表示)将分区物化(materialize)存下来(灰色方块)。
一部分变换算子视RDD的元素为简单元素,分为如下几类:
输入输出一对一(element-wise)的算子,且结果RDD的分区结构不变,主要是map、flatMap(map后展平为一维RDD);
输入输出一对一,但结果RDD的分区结构发生了变化,如union(两个RDD合为一个)、coalesce(分区减少);
从输入中选择部分元素的算子,如filter、distinct(去除冗余元素)、subtract(本RDD有、它RDD无的元素留下来)和sample(采样)。
另一部分变换算子针对Key-Value集合,又分为:
对单个RDD做element-wise运算,如mapValues(保持源RDD的分区方式,这与map不同);
对单个RDD重排,如sort、partitionBy(实现一致性的分区划分,这个对数据本地性优化很重要,后面会讲);
对单个RDD基于key进行重组和reduce,如groupByKey、reduceByKey;
对两个RDD基于key进行join和重组,如join、cogroup。
后三类操作都涉及重排,称为shuffle类操作。
从RDD到RDD的变换算子序列,一直在RDD空间发生。这里很重要的设计是lazy evaluation:计算并不实际发生,只是不断地记录到元数据。元数据的结构是DAG(有向无环图),其中每一个“顶点”是RDD(包括生产该RDD 的算子),从父RDD到子RDD有“边”,表示RDD间的依赖性。Spark给元数据DAG取了个很酷的名字,Lineage(世系)。这个 Lineage也是前面容错设计中所说的日志更新。
Lineage一直增长,直到遇上行动(action)算子(图1中的绿色箭头),这时 就要evaluate了,把刚才累积的所有算子一次性执行。行动算子的输入是RDD(以及该RDD在Lineage上依赖的所有RDD),输出是执行后生 成的原生数据,可能是Scala标量、集合类型的数据或存储。当一个算子的输出是上述类型时,该算子必然是行动算子,其效果则是从RDD空间返回原生数据空间。
RDD的运行逻辑
如图所示,在Spark应用中,整个执行流程在逻辑上运算之间会形成有向无环图。Action算子触发之后会将所有累积的算子形成一个有向无环图,然后由调度器调度该图上的任务进行运算。Spark的调度方式与MapReduce有所不同。Spark根据RDD之间不同的依赖关系切分形成不同的阶段(Stage),一个阶段包含一系列函数进行流水线执行。图中的A、B、C、D、E、F、G,分别代表不同的RDD,RDD内的一个方框代表一个数据块。数据从HDFS输入Spark,形成RDD A和RDD C,RDD C上执行map操作,转换为RDD D,RDD B和RDD F进行join操作转换为G,而在B到G的过程中又会进行Shuffle。最后RDD G通过函数saveAsSequenceFile输出保存到HDFS中。


RDD依赖关系
RDD依赖关系如下图所示:

窄依赖 (narrowdependencies) 和宽依赖 (widedependencies) 。
窄依赖是指 父 RDD 的每个分区都只被子 RDD 的一个分区所使用,例如map、filter。
宽依赖就是指父 RDD 的分区被多个子 RDD 的分区所依赖,例如groupByKey、reduceByKey等操作。如果父RDD的一个Partition被一个子RDD的Partition所使用就是窄依赖,否则的话就是宽依赖。
这种划分有两个用处。首先,窄依赖支持在一个结点上管道化执行。例如基于一对一的关系,可以在 filter 之后执行 map 。其次,窄依赖支持更高效的故障还原。因为对于窄依赖,只有丢失的父 RDD 的分区需要重新计算。而对于宽依赖,一个结点的故障可能导致来自所有父 RDD 的分区丢失,因此就需要完全重新执行。因此对于宽依赖,Spark 会在持有各个父分区的结点上,将中间数据持久化来简化故障还原,就像 MapReduce 会持久化 map 的输出一样。
特别说明:对于join操作有两种情况,如果join操作的使用每个partition仅仅和已知的Partition进行join,此时的join操作就是窄依赖;其他情况的join操作就是宽依赖;因为是确定的Partition数量的依赖关系,所以就是窄依赖,得出一个推论,窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖(也就是说对父RDD的依赖的Partition的数量不会随着RDD数据规模的改变而改变)
Stage的划分:
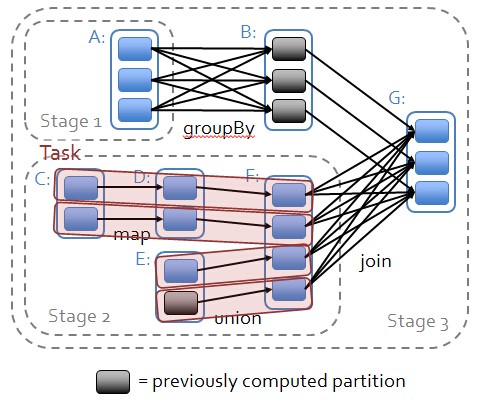
Stage划分的依据就是宽依赖,什么时候产生宽依赖呢?例如reduceByKey,groupByKey等Action。
1. 从后往前推理,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到Stage中;
2. 每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition数量决定的;
3. 最后一个Stage里面的任务的类型是ResultTask,前面所有其他Stage里面的任务类型都是ShuffleMapTask;
4. 代表当前Stage的算子一定是该Stage的最后一个计算步骤。
补充:Hadoop中的MapReduce操作中的Mapper和Reducer在Spark中基本等量算子是:map、reduceByKey;在一个Stage内部,首先是算子合并,也就是所谓的函数式编程的执行的时候最终进行函数的展开从而把一个Stage内部的多个算子合并成为一个大算子(其内部包含了当前Stage中所有算子对数据的计算逻辑);其次是由于Transformation操作的Lazy特性!!在具体算子交给集群的Executor计算之前,首先会通过Spark Framework(DAGScheduler)进行算子的优化。














 1549
1549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









