







利用MPICH2计算矩阵相乘的简单算法
烤鱼片(@eii.dlmu)
cleverysm@163.com
MPICH2是用来进行并行运算的平台,而对矩阵算法的分解应该是并行运算应用中很常见的。今天在这里就用MPICH2写一个矩阵乘法的并行计算程序来学习一下MPICH2的使用。
首先要复习一下矩阵乘法的算法,我们在线性代数里都学过。
假设矩阵A为m行,k列。m=4,k=3。B是k行,n列,k=3,n=2,计算一个矩阵与列数据,或者叫做一个向量vector的乘积,结果矩阵C应当是m行,n列。
A:
1,2,3
4,5,6
7,8,9
8,7,6
B:
5,4
3,2
1,0
A,B,C都按照行主序表示。即A(0,0)=1,A(0,1)=2, A(0,3)=3。
则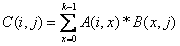
如C(1,0)=A(1,0)×B(0,0)+A(1,1)×B(1,0)+A(1,2)×B(2,0)=4×5+5×3+6×1=41 。
C:
14,8
41,26
68,44
67,46
那如何将这个算法进行分解,分配到参与计算的各进程上去呢?简单的做法是可以将矩阵A进行划分,每个计算进程分配若干行,每次与B的一列数据计算的时候分别计算其进程所分配的行与B的这一列相乘的结果。
比如有两个进程计算,分别为进程1和进程2。1分配A的0,和2行,2
分配A的1和3行,与B的0列计算的时候,1进程将只计算得到C的一列的0和2位置两个数据,而2进程则算得1和3位置的数据。两个进程个子计算完成相应位置的数据后组合起来就是C的一列结果数据。
在此,我使用MPI构建一种主-从(master-slave)模式的程序,也就是有一个进程是主进程,负责分发A矩阵的数据,并收集从进程的计算结果,将这些结果合并为最终的结果数据。这样整个程序需要一个主进程和若干个从进程,也就是至少要两个进程。
主进程的代码如下:
//主进程
int master()
{
int myid; //
int numprocs; //
MPI_Status status;
//获取当前进程的进程编号,保存在myid中
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
//获取当前进程的进程总数,保存在numprocs中
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
int const M(4),K(3),N(2);
//结果矩阵C
int C[M*N];
int V[M];
//将结果矩阵各元素初始化为0
for(int i=0;i<M*N;i++)
{
C[i]=0;
}
//C矩阵共N列数据
for(int i=0;i<N;i++)
{
//从各从进程接受数据
for(int j=1;j<numprocs;j++)
{
MPI_Recv(V, M, MPI_INT, j, i, MPI_COMM_WORLD, &status);
//将各从进程的部分数据整合成完整的一个向量
for(int ij=0;ij<M;ij++)
{
C[ij*N+i]=C[ij*N+i]+V[ij];
}
}
}
//打印结果
for(int i=0;i<M;i++)
{
for(int j=0;j<N;j++)
{
cout<<C[i*N+j]<<"/t";
}
cout<<endl;
}
return 0;
}
从进程代码:
//从进程
int slave()
{
int myid; //
int numprocs; //
MPI_Status status;
//获取当前进程的进程编号,保存在myid中
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
//获取当前进程的进程总数,保存在numprocs中
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
int const M(4),K(3),N(2);
vector<int> indexes;
int V[M];
int A[M*K]={1,2,3,4,5,6,7,8,9,8,7,6};
int B[K*N]={5,4,3,2,1,0};
//计算本进程分配A矩阵中哪些行,保存在indexes中
//比如2个从进程,A是4行数据,id为1的从进程分配的是0和2行
for(int i=myid-1;i<M;i+=numprocs-1)
{
indexes.push_back(i);
}
//依次计算B的N列数据
for(int i=0;i<N;i++)
{
//将保存列数据的向量V各元素初始化为0
for(int j=0;j<M;j++)
{
V[j]=0;
}
if(indexes.size()>0)
{
for(int j=0;j<indexes.size();j++)
{
for(int ij=0;ij<K;ij++)
{
V[indexes[j]]+=A[indexes[j]*K+ij]*B[ij*N+i];
}
}
MPI_Send(V, M, MPI_INT, 0,i,MPI_COMM_WORLD);
}
else
{
//发送全0的V
MPI_Send(V, M, MPI_INT, 0,i,MPI_COMM_WORLD);
}
}
return 0;
}
main函数代码:
#undef SEEK_SET
#undef SEEK_END
#undef SEEK_CUR
#include <mpi.h>
#include <iostream>
#include <vector>
using namespace std;
int master();
int slave();
int main(void) {
int myid; //
int numprocs; //
MPI_Status status;
//MPI程序的初始化
MPI_Init(NULL,NULL);
//获取当前进程的进程编号,保存在myid中
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
//获取当前进程的进程总数,保存在numprocs中
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
//如果进程数小于2个,则退出程序
if(numprocs<2)
{
cout<<"Too Few Processes!"<<endl;
MPI_Abort(MPI_COMM_WORLD,99);
}
if(myid==0)
{
//id是0的进程作为主进程
master();
}
else
{
//id是非0的进程作为从进程
slave();
}
//MPI程序释放资源
MPI_Finalize();
return EXIT_SUCCESS;
}
以上算法是按照行划分A矩阵,也可以按照A的列来分配矩阵。算法如下:
将第一列中的所有元素与向量中的第一个元素相乘,第二列的元素与向量中的第二个元素相乘,依此类推。采用这种方法,就可以得到一个新的矩阵。然后,将每一行中的所有元素相加,得到一个矩阵,这就是最后的结果。
A:
1,2,3
4,5,6
7,8,9
8,7,6
为简化,B只取第一列
B:
5
3
1
--> 1*5+2*3+3*1=14
4*5+5*3+6*1=41
7*5+8*3+9*1=68
8*5+7*3+6*1=67
实现此算法的MPI程序与以上代码类似,在此就不说了。















 3010
3010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









