






记录使用MPI完成矩阵乘法程序的过程。
一、MPI安装
在linux系统中,输入命令:
sudo apt-get install mpich如果要卸载,则输入:
sudo apt-get --purge remove mpich二、矩阵乘法程序
1.初始化
由于我们要使用MPI传递二维数组,故这里我们创建三个N*N的一维数组A、B、C以便后续数据传输。
double *A = new double [n*n];
double *B = new double [n*n];
double *partA = new double [n*n];
double *partC = new double [n*n];
if(myid==0){
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
if(i<N && j<N){
A[i*n+j] = rand()%10;
B[i*n+j] = rand()%10;
}else{
A[i*n+j] = 0;
B[i*n+j] = 0;
}
}
}
startWtime = MPI_Wtime();
}2.矩阵乘法
普通矩阵乘法只需要3个for循环即可,但考虑到Cache存储,我们可以将一个矩阵转置过来,提高Cache命中率:
void matM(double *A,double *B,double *C,int divideN,int n){//cache
double mid;
for(int i=0;i<divideN;i++)for(int j=0;j<i;j++){
mid=B[i*n+j];
B[i*n+j]=B[j*n+i];
B[j*n+i]=mid;
}
for(int i=0;i<divideN;i++){
for(int j=0;j<n;j++){
C[i*n+j]=0;
for(int k=0;k<n;k++){
C[i*n+j]+=A[i*n+k] * B[j*n+k];
}
}
}
for(int i=0;i<divideN;i++)for(int j=0;j<i;j++){
mid=B[i*n+j];
B[i*n+j]=B[j*n+i];
B[j*n+i]=mid;
}
}3.并行矩阵乘法程序
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <stdbool.h>
#include <iostream>
#include <mpi.h>
#define N 8000
void matM(double *A,double *B,double *C,int divideN,int n){//cache
double mid;
for(int i=0;i<divideN;i++)for(int j=0;j<i;j++){
mid=B[i*n+j];
B[i*n+j]=B[j*n+i];
B[j*n+i]=mid;
}
for(int i=0;i<divideN;i++){
for(int j=0;j<n;j++){
C[i*n+j]=0;
for(int k=0;k<n;k++){
C[i*n+j]+=A[i*n+k] * B[j*n+k];
}
}
}
for(int i=0;i<divideN;i++)for(int j=0;j<i;j++){
mid=B[i*n+j];
B[i*n+j]=B[j*n+i];
B[j*n+i]=mid;
}
}
int main(int argc,char *argv[])
{
double startWtime=0.0,endWtime=0.0;
int myid,numProcs,jud=0;
MPI_Init(&argc, &argv );
MPI_Comm_rank(MPI_COMM_WORLD, &myid );
MPI_Comm_size(MPI_COMM_WORLD, &numProcs );
int n=0;
if (N % numProcs!=0){
n=N-N%numProcs+numProcs;
}else{
n=N;
}
int divideN = n/numProcs;
srand(1);//保持一致性
double *A = new double [n*n];
double *B = new double [n*n];
double *partA = new double [n*n];
double *partC = new double [n*n];
if(myid==0){
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
if(i<N && j<N){
A[i*n+j] = rand()%10;
B[i*n+j] = rand()%10;
}else{
A[i*n+j] = 0;
B[i*n+j] = 0;
}
}
}
startWtime = MPI_Wtime();
}
MPI_Scatter(&A[0*n+0],divideN *n,MPI_DOUBLE,&partA[0*n+0],divideN *n,MPI_DOUBLE,0,MPI_COMM_WORLD);
MPI_Bcast(&B[0*n+0],n*n,MPI_DOUBLE,0,MPI_COMM_WORLD);
matM(partA,B,partC,divideN,n);
double *C = nullptr;
if(myid==0) C = new double [n*n];
MPI_Gather(&partC[0*n+0],divideN *n,MPI_DOUBLE,&C[0*n+0],divideN *n,MPI_DOUBLE,0,MPI_COMM_WORLD);
if(myid==0){
endWtime = MPI_Wtime();
printf("用时: %.3f 秒\n", endWtime-startWtime);
}
delete []A;
delete []B;
delete []C;
delete []partA;
delete []partC;
MPI_Finalize();
return 0;
}三、结果
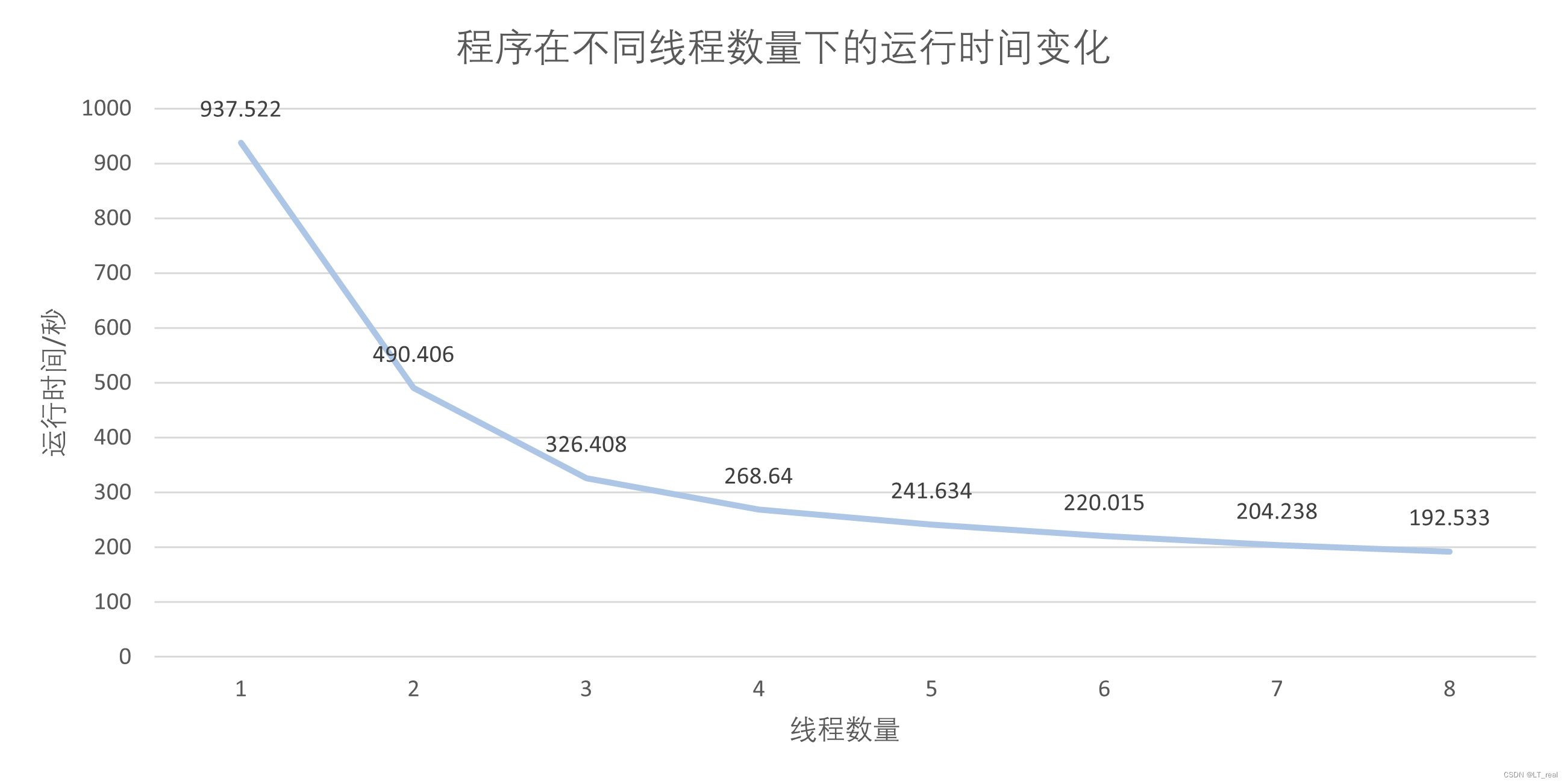
参考:
Linux下的MPI安装(类比linux软件的安装方式)_linux安装mpi-CSDN博客
【MPI学习笔记】1:并行化向量和矩阵的乘积_矩阵和向量乘法并行计算mpi-CSDN博客
并行程序设计实验_编写一个矩阵乘法的gpu并行程序,并且与对应规模的串行程序进行运行时间的比对(n=5-CSDN博客















 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









