







高性能计算实验——通用矩阵乘法串行编程的实现及优化
代码见lab1链接:pan.baidu.com/s/1F7hJIh1y88lszomoN160vA?pwd=g2wm
提取码:g2wm
1.实验目的
1.1通用矩阵乘法
熟练掌握通用矩阵乘法的原理以及实现GEMM,为后续实验打下基础,用C 语言实现一个矩阵乘法。
1.2通用矩阵乘法优化
进一步熟悉矩阵乘法的实现,深入学习矩阵乘法的优化算法,学习矩阵乘法的复杂度分析并实现复杂度的优化降低。
1.3大规模矩阵计算优化
学习大规模矩阵乘法的计算优化,从性能或可靠性两个方向考虑
如何让程序支持大规模矩阵乘法,对优化方法及思想进行详细描述。
2.实验过程和核心代码
2.1通用矩阵乘法
2.1.1问题描述
数学上,一个m × n的矩阵是一个由m行n 列元素排列成的矩形阵列。矩阵是高等代数中常见的数学工具,也常见于统计分析等应用数学学科中。矩阵运算是数值分析领域中的重要问题。
通用矩阵乘法(GEMM)通常定义为:
C = AB
请根据定义用C 语言实现一个矩阵乘法:
题目:用C 语言实现通用矩阵乘法
输入:M , N, K 三个整数(512 ~2048)
问题描述:随机生成 MN 和NK 的两个矩阵 A,B,对这两个矩阵做乘法得到矩阵 C.
输出:A,B,C 三个矩阵以及矩阵计算的时间
2.1.2实现过程
这里可以根据GEMM公式进行核心代码矩阵乘法部分的实现,三重循环即可简单的实现。
输入方面根据输入的矩阵信息分配对应的空间并产生随机数。时间方面使用timeb.h库中的timeb结构获得精确时间。
2.1.3核心代码
矩阵生成
void Gen_Matrix(int m,int n,int k){
for(int i=0;i<m;i++){
for(int j=0;j<n;j++){
A[i][j] = rand()%5;
}
}
for(int i=0;i<n;i++){
for(int j=0;j<k;j++){
B[i][j] = rand()%5;
}
}
}
获取时间
long long getSystemTime() {
struct timeb t;
ftime(&t);
return 1000 * t.time + t.millitm;
}
矩阵乘法

2.2通用矩阵乘法优化
2.2.1问题描述
对上述的矩阵乘法进行优化,优化方法可以分为以下两类:
基于算法分析的方法对矩阵乘法进行优化,典型的算法包括 Strassen算法和 Coppersmith–Winograd算法
基于软件优化的方法对矩阵乘法进行优化,如循环拆分向量化和内存重排
实验要求:对优化方法进行详细描述,并提供优化后的源代码,以及与GEMM 的计算时间对比
这里选择Strassen算法进行优化。
实现过程
Strassen算法核心思想:
假设矩阵A和矩阵B都是 N*N的方矩阵(N为2的幂),求C=AB,如下所示:

矩阵C可以通过以下公式求出:
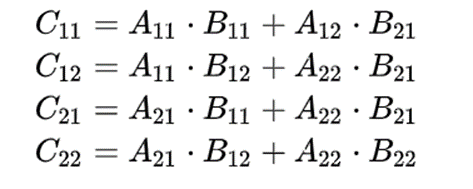
从上述公式我们可以得出,计算2个nn的矩阵相乘需要2个n/2n/2的矩阵8次乘法和4次加法。我们使用T(n)表示n*n矩阵乘法的时间复杂度,那么我们可以根据上面的分解得到下面的递推公式:
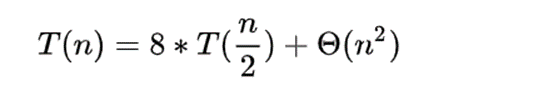
即时间复杂度为n3,这里Strassen优化思想如下:
-
按上述方法将矩阵A,B,C分解
-
如下创建10个 n/2*n/2的矩阵:

-
递归地计算7个矩阵积 P1、P2…P7,每个矩阵Pi都是n/2*n/2的。

-
通过Pi计算C11、C12、C21、C22

综合可得如下递归式:
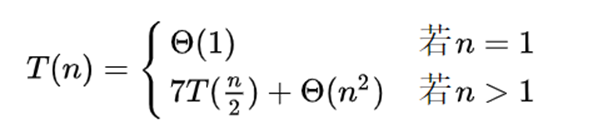
进而时间复杂度为:
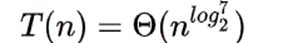
此时矩阵乘法时间复杂度得以优化。
核心代码
①给A、B矩阵赋初值

②矩阵加法

③矩阵减法

④Strassen核心代码
划分:

计算P1-P7,方法相似:

计算C11、C12、C21、C22:

2.3大规模矩阵计算优化
2.3.1问题描述
进阶问题描述:如何让程序支持大规模矩阵乘法? 考虑两个优化方向
(1)性能,提高大规模稀疏矩阵乘法性能;
(2)可靠性,在内存有限的情况下,如何保证大规模矩阵乘法计算完成(M, N, K >>100000),不触发内存溢出异常。
下面对优化方法及思想进行详细描述。
2.3.2优化思想
以行存储优先作为基础进行优化分析,考虑下列两种情况:
(1)当AB矩阵较小时,根据计算机结构可知,当从RAM中读取AB矩阵内存,根据局部性原理可以将AB矩阵放到cache中,因为cpu访问cache比访问主存的快。
(2)当AB矩阵较大时,超过cache大小时,根据矩阵乘的普通方法,由于访问“行优先存储的B矩阵”的时候内存不连续(读取B矩阵的一列),造成缓存cache频繁的换入换出,从RAM读取内存的次数大于AB矩阵的大小。
因此得到优化方法:
①向量化(SIMD)
向量化可以使一条指令并行的使多个相同操作数执行相同的操作,减少每次循环迭代时评估操作类型的开销。
②内存对齐
内存对齐的原则:任何K字节的基本对象的地址必须都是K的倍数。
“假设 cache line 为 32B。待访问数据大小为 64B,地址在 0x80000001,则需要占用 3 条 cache 映射表项;若地址在 0x80000000 则只需要 2 条。内存对齐变相地提高了 cache 命中率。”
③ 分块

图中共有6钟拆分方法,依次分析:
(1) 拆分K,A矩阵拆成多列,B矩阵拆成多行。拆分M,A的一列拆分成三个block。拆分N,B的一行也可以拆分成多个小slice,每个slice放到寄存器中。遍历A的列,A的每个block乘以B的一行,得到矩阵C的一行的部分值。 拆分之后Aip为(mc, kc), Bpj为(kc, nr), Cij为(mc, nr)。
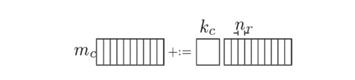
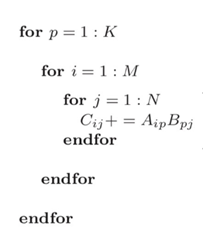

如果kc*mc很小,那么Aip、Bpj、Cij都放入cache中,Aip(A矩阵的一个block)只需要被加载进cache一次,提高了cache命中率。对Ai和Bj进行pack使其内存连续。由于处理B矩阵是按照每个slice依次进行,所以这种划分更适合于列存储优先的矩阵乘。
(2)拆分K,A拆分成多列,B拆成多行。拆分N,B的一行被拆分为三个block。拆分M,A的一列被拆分为多个slice。A的一列乘以B的每个block,得到矩阵C的一列的部分值。


类似于(1), 只是变成A的一行乘以B的一个block。所以这种划分更适合于行存储优先的矩阵乘。
(3)拆分N,B矩阵被拆分为多列。再拆分K,A拆分成多列,B拆成多个block。拆分M,A的一列被拆分为多个小block。A的一列乘以B的每个block,得到矩阵C的一列的部分值。


这种划分与(2)的划分唯一的区别是,访问B矩阵是按列还是按行。很显然(2)的划分方式好于(3)。
(4)类似于普通矩阵乘,A的一行*B的一列。然后在K拆分,将A矩阵的每行划分为多个block, 将B矩阵的每列划分为多个block。

每次执行可以得到C矩阵一个block的值。当MNK非常大时,cache无法存下Cj,所以划分方法没有什么优势。
(5) 类似于(4), 都是每次执行可以得到C矩阵的一个block的值。同样当MNK非常大时,cache无妨存下Cj,所以该方法没有什么优势。

4.实验结果
4.1通用矩阵乘法

可以看到,计算结果正确;

对2048*2048的矩阵来说,时间消耗84054ms;
4.2Strassen算法
算法正确性简单验证通过,主要考虑时间方面与朴素算法的对比,这里为了保证环境一致,直接在算法中实现朴素算法,完成朴素计算后再进行Strassen算法的计算,进行对比。
数据选择为2048*2048;

可以看出计算结果sum相同,但是Strassen算法时间更久一些,这里初步分析是由于一些分配/回收堆内存以及递归调用的操作使得总时间上升。
5.实验感想
本次实验是高性能实验的开始,整个高性能实验都是基于矩阵乘法进行的,因此这里先首先掌握朴素矩阵乘法的运算方法和算法复杂度十分必要,同时矩阵乘法的优化部分进一步学习掌握了普通方法改进矩阵乘法的Strassen算法,可以与后续的MPI、多线程优化进行比较分析。















 710
710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









