




 本文详细介绍了二叉树的遍历方法、多种排序算法(包括选择排序、插入排序、快速排序等)、图的表示方法(邻接矩阵和邻接表)、时间复杂度计算方法以及线性表的操作等内容。
本文详细介绍了二叉树的遍历方法、多种排序算法(包括选择排序、插入排序、快速排序等)、图的表示方法(邻接矩阵和邻接表)、时间复杂度计算方法以及线性表的操作等内容。
二叉树三种遍历方法
前序遍历:先遍历根结点,然后遍历左子树,最后遍历右子树(中左右)
中序遍历:先遍历左子树,然后遍历根结点,最后遍历右子树(左中右)
后序遍历:先遍历左子树,然后遍历右子树,最后遍历根节点(左右中)
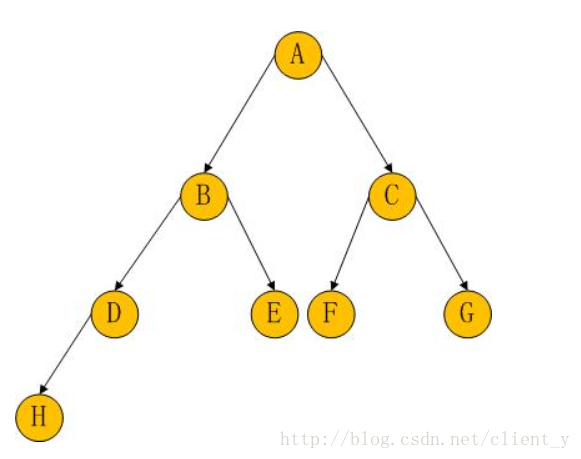
前序遍历:ABDHECFG
中序遍历:HDBEAFCG
后序遍历:HDEBFGCA
递归实现
void _prevOrder(Node* root) //前---根、左、右
{
if(root == NULL)
return ;
Node* cur = root;
if(cur)
{
cout<<cur->_data<<" ";
_prevOrder(cur->_left);
_prevOrder(cur->_right);
}
} void _inOrder(Node* root) //中---左、根、右
{
if(root == NULL)
return ;
Node* cur = root;
if (cur)
{
_inOrder(cur->_left);
cout<<cur->_data<<" ";
_inOrder(cur->_right);
}
} void _postOrder(Node* root) //后---左、右、根
{
if (root == NULL)
return ;
Node* cur = root;
if (cur)
{
_postOrder(cur->_left);
_postOrder(cur->_right);
cout<<cur->_data<<" ";
}
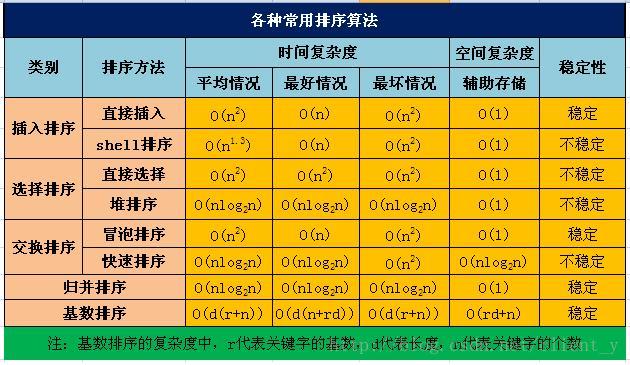
} 排序
方法
时间复杂度
实现原理
代码
选择排序
过程详解
序列:56 12 80 91 20 第1趟:12 56 80 91 20 第2趟:12 20 80 91 56 第3趟:12 20 56 91 80 第4趟:12 20 56 80 91代码实现

//交换data1和data2所指向的整形
void DataSwap(int* data1, int* data2)
{
int temp = *data1;
*data1 = *data2;
*data2 = temp;
}
/********************************************************
*函数名称:SelectionSort
*参数说明:pDataArray 无序数组;
* iDataNum为无序数据个数
*说明: 选择排序
*********************************************************/
void SelectionSort(int* pDataArray, int iDataNum)
{
for (int i = 0; i < iDataNum - 1; i++) //从第一个位置开始
{
int index = i;
for (int j = i + 1; j < iDataNum; j++) //寻找最小的数据索引
if (pDataArray[j] < pDataArray[index])
index = j;
if (index != i) //如果最小数位置变化则交换
DataSwap(&pDataArray[index], &pDataArray[i]);
}
} 插入排序
插入排序:插入即表示将一个新的数据插入到一个有序数组中,并继续保持有序。例如有一个长度为N的无序数组,进行N-1次的插入即能完成排序;第一次,数组第1个数认为是有序的数组,将数组第二个元素插入仅有1个有序的数组中;第二次,数组前两个元素组成有序的数组,将数组第三个元素插入由两个元素构成的有序数组中……第N-1次,数组前N-1个元素组成有序的数组,将数组的第N个元素插入由N-1个元素构成的有序数组中,则完成了整个插入排序。
过程详解
序列:65 27 59 64 58 第1次插入: 27 65 59 64 58 第2次插入: 27 59 65 64 58 第3次插入: 27 59 64 65 58 第4次插入: 27 58 59 64 65代码实现

/********************************************************
*函数名称:InsertSort
*参数说明:pDataArray 无序数组;
* iDataNum为无序数据个数
*说明: 插入排序
*********************************************************/
void InsertSort(int* pDataArray, int iDataNum)
{
for (int i = 1; i < iDataNum; i++) //从第2个数据开始插入
{
int j = 0;
while (j < i && pDataArray[j] <= pDataArray[i]) //寻找插入的位置
j++;
if (j < i) //i位置之前,有比pDataArray[i]大的数,则进行挪动和插入
{
int k = i;
int temp = pDataArray[i];
while (k > j) //挪动位置
{
pDataArray[k] = pDataArray[k-1];
k--;
}
pDataArray[k] = temp; //插入
}
}
} 快速排序
算法复杂度
快速排序的平均时间复杂度O(n×log(n)),最糟糕时复杂度为O(n^2)思想原理
快速排序的基本思想是,通过一轮的排序将序列分割成独立的两部分,其中一部分序列的关键字(这里主要用值来表示)均比另一部分关键字小。继续对长度较短的序列进行同样的分割,最后到达整体有序。在排序过程中,由于已经分开的两部分的元素不需要进行比较,故减少了比较次数,降低了排序时间。过程详解
初始序列: 6 1 2 7 9 3 4 5 10 8
以6为基准值,令i= 1,j = 10,先从右往左找一个比6小的值,找到5(即j = 8);再从左往右找一个比6大的值,找到7(即i = 4),交换两个数字,得到序列6 1 2 5 9 3 4 7 10 8 ;接着再从右往左找一个比6小的值,找到4(即j = 7);再从左往右找一个比6大的值,找到9(即i = 5),交换两个数字,得到序列6 1 2 5 4 3 9 7 10 8;接着再从右往左找到3,再从左往右到3时,此时i = j,交换基准值和3,得到序列3 1 2 5 4 6 9 7 10 8;
接下来分别对6左边的序列3 1 2 5 4和右边的序列9 7 10 8进行上述操作;
最后合并即可;- 代码实现
#include <stdio.h>
int a[101],n;//定义全局变量,这两个变量需要在子函数中使用
void quicksort(int left,int right)
{
int i,j,t,temp;
if(left>right)
return;
temp=a[left]; //temp中存的就是基准数
i=left;
j=right;
while(i!=j)
{
//顺序很重要,要先从右边开始找
while(a[j]>=temp && i<j)
j--;
//再找右边的
while(a[i]<=temp && i<j)
i++;
//交换两个数在数组中的位置
if(i<j)
{
t=a[i];
a[i]=a[j];
a[j]=t;
}
}
//最终将基准数归位
a[left]=a[i];
a[i]=temp;
quicksort(left,i-1);//继续处理左边的,这里是一个递归的过程
quicksort(i+1,right);//继续处理右边的 ,这里是一个递归的过程
}
int main()
{
int i,j,t;
//读入数据
scanf("%d",&n);
for(i=1;i<=n;i++)
scanf("%d",&a[i]);
quicksort(1,n); //快速排序调用
//输出排序后的结果
for(i=1;i<=n;i++)
printf("%d ",a[i]);
getchar();getchar();
return 0;
} 希尔排序
- 算法复杂度
时间复杂度为O(n^1.3) ,空间复杂度为O(1) 稳定性
不稳定思想原理
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。过程详解
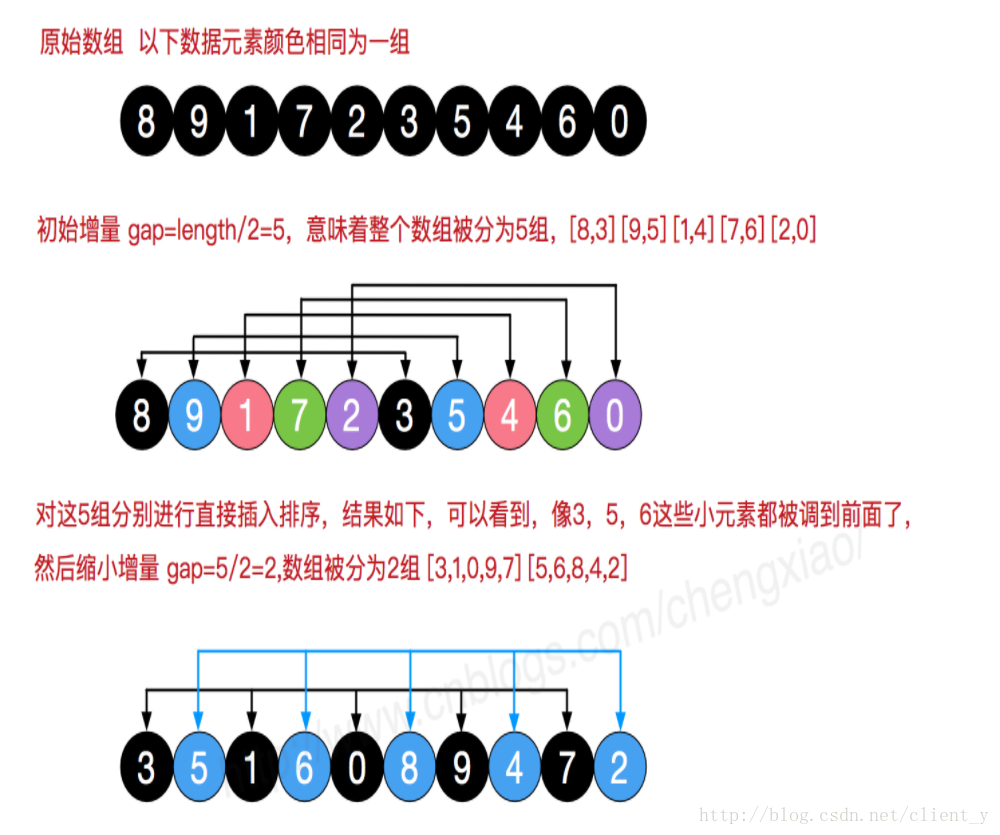
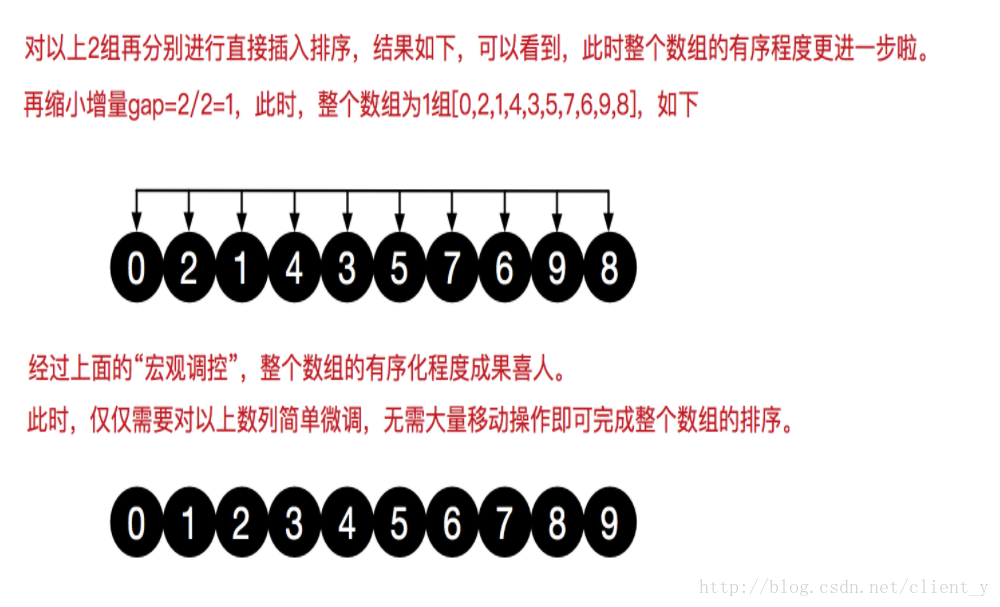
-代码实现
void swapInt(int * a,int*b)
{
int c=*a;
*a=*b;
*b=c;
}
void shell(int*data,unsigned int len)
{
if(len<=1||data==NULL)
return;
for(int div=len/2;div>=1;div=div/2)//定增量div,并不断减小
{
for(int i=0;i<=div;++i)//分组成div组
{
for(int j=i;j<len-div;j+=div)//对每组进行插入排序
for(int k=j;k<len;k+=div)
if(data[j]>data[k])
swapInt(data+j,data+k);//交换两个数的值
}
}
}归并排序
非递归算法:
#include<iostream>
#include<ctime>
#include<cstring>
#include<cstdlib>
using namespace std;
/**将a开头的长为length的数组和b开头长为right的数组合并n为数组长度,用于最后一组*/
void Merge(int* data,int a,int b,int length,int n){
int right;
if(b+length-1 >= n-1) right = n-b;
else right = length;
int* temp = new int[length+right];
int i=0, j=0;
while(i<=length-1 && j<=right-1){
if(data[a+i] <= data[b+j]){
temp[i+j] = data[a+i];i++;
}
else{
temp[i+j] = data[b+j];
j++;
}
}
if(j == right){//a中还有元素,且全都比b中的大,a[i]还未使用
memcpy(temp + i + j, data + a + i, (length - i) * sizeof(int));
}
else if(i == length){
memcpy(temp + i + j, data + b + j, (right - j)*sizeof(int));
}
memcpy(data+a, temp, (right + length) * sizeof(int));
delete [] temp;
}
void MergeSort(int* data, int n){
int step = 1;
while(step < n){
for(int i=0; i<=n-step-1; i+=2*step)
Merge(data, i, i+step, step, n);
//将i和i+step这两个有序序列进行合并
//序列长度为step
//当i以后的长度小于或者等于step时,退出
step*=2;//在按某一步长归并序列之后,步长加倍
}
}
int main(){
int n;
cin>>n;
int* data = new int[n];
if(!data) exit(1);
int k = n;
while(k--){
cin>>data[n-k-1];
}
clock_t s = clock();
MergeSort(data, n);
clock_t e = clock();
k=n;
while(k--){
cout<<data[n-k-1]<<' ';
}
cout<<endl;
cout<<"the algorithm used"<<e-s<<"miliseconds."<<endl;
delete data;
return 0;
}
递归算法:
#include<iostream>
using namespace std;
void merge(int *data, int start, int mid, int end, int *result)
{
int i, j, k;
i = start;
j = mid + 1; //避免重复比较data[mid]
k = 0;
while (i <= mid && j <= end) //数组data[start,mid]与数组(mid,end]均没有全部归入数组result中去
{
if (data[i] <= data[j]) //如果data[i]小于等于data[j]
result[k++] = data[i++]; //则将data[i]的值赋给result[k],之后i,k各加一,表示后移一位
else
result[k++] = data[j++]; //否则,将data[j]的值赋给result[k],j,k各加一
}
while (i <= mid) //表示数组data(mid,end]已经全部归入result数组中去了,而数组data[start,mid]还有剩余
result[k++] = data[i++]; //将数组data[start,mid]剩下的值,逐一归入数组result
while (j <= end) //表示数组data[start,mid]已经全部归入到result数组中去了,而数组(mid,high]还有剩余
result[k++] = data[j++]; //将数组a[mid,high]剩下的值,逐一归入数组result
for (i = 0; i < k; i++) //将归并后的数组的值逐一赋给数组data[start,end]
data[start + i] = result[i]; //注意,应从data[start+i]开始赋值
}
void merge_sort(int *data, int start, int end, int *result)
{
if (start < end)
{
int mid = (start + end) / 2;
merge_sort(data, start, mid, result); //对左边进行排序
merge_sort(data, mid + 1, end, result); //对右边进行排序
merge(data, start, mid, end, result); //把排序好的数据合并
}
}
void amalgamation(int *data1, int *data2, int *result)
{
for (int i = 0; i < 10; i++)
result[i] = data1[i];
for (int i = 0; i < 10; i++)
result[i + 10] = data2[i];
}
int main()
{
int data1[10] = { 1,7,6,4,9,14,19,100,55,10 };
int data2[10] = { 2,6,8,99,45,63,102,556,10,41 };
int *result = new int[20];
int *result1 = new int[20];
amalgamation(data1, data2, result);
for (int i = 0; i < 20; ++i)
cout << result[i] << " ";
cout << endl;
merge_sort(result, 0, 19, result1);
for (int i = 0; i < 20; ++i)
cout << result[i] << " ";
delete[]result;
delete[]result1;
return 0;
}基数排序
邻接表和邻接矩阵
要表示一个图G=(V,E),有两种标准的表示方法,即邻接表和邻接矩阵。这两种表示法既可用于有向图,也可用于无向图。通常采用邻接表表示法,因为用这种方法表示稀疏图(图中边数远小于点个数)比较紧凑。但当遇到稠密图(
|E|接近于|V|2
)或必须很快判别两个给定顶点是否存在连接边时,通常采用邻接矩阵表示法,例如求最短路径算法中,就采用邻接矩阵表示。
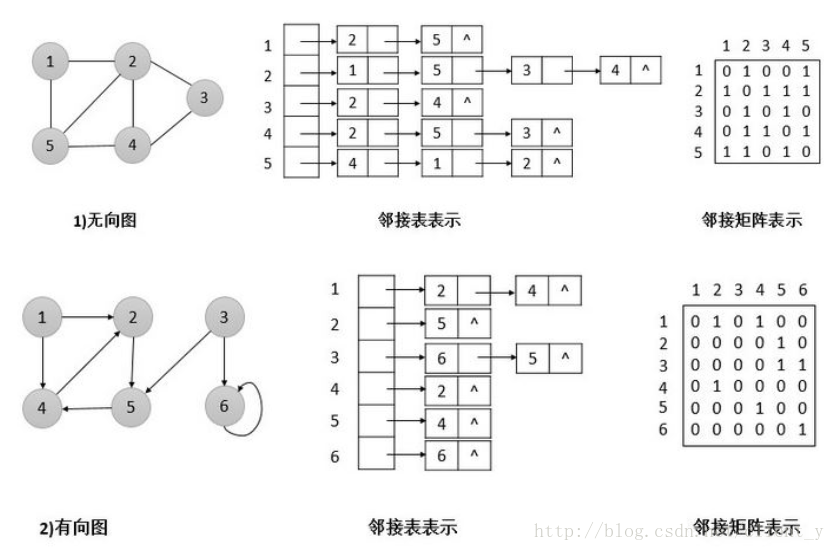
邻接矩阵(Adjacency Matrix)的存储方式是用两个数组来表示图在邻接矩阵中,可以使用一个二维数组表示图中顶点之间的关系,这个二维数组称为邻接矩阵。假设图
A=<V,E>
,包含n个顶点。则A的顶点之间关系可表示为
A.Edge[n][n]
。因此,图的邻接矩阵中元素的定义为:
A.Edge[i][j]=1,若(vi,vj)∈E<vi,vj>∈E
;
A.Edge[i][j]=0,其他.
邻接表(Adjacency List)是顺序存储与链式存储相结合的存储方法。图中的每个顶点与它的邻接点链接成一个单向链表:顶点为头结点,链表中每个结点代表一条边(边结点),链表中结点值(即数据域中值)是与头结点相邻结点在表中的序号,头结点的指针指向第一个邻接点(表结点)。
小结:
- 设图中有n个顶点,e条边,则用邻接表表示无向图时,需要n个顶点结点,2e个表结点;用邻接表表示有向图时,若不考虑逆邻接表,只需n个顶点结点,e个边结点。
- 在无向图的邻接表中,顶点vi的度恰为第i个链表中的结点数。
- 在有向图中,第i个链表中的结点个数只是顶点vi的出度。在逆邻接表中的第i个链表中的结点个数为vi的入度。
- 建立邻接表的时间复杂度为O(n+e)。
时间复杂度
定义
在计算机科学中,算法的时间复杂度是一个函数,它定性描述了该算法的运行时间。这是一个关于代表算法输入值的字符串的长度的函数。时间复杂度常用大O符号表述,不包括这个函数的低阶项和首项系数。时间复杂度是总运算次数表达式中受n的变化影响最大的那一项(不含系数)。
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示。
若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。
记作T(n)=O(f(n)),称O(f(n))为算法的渐进时间复杂度(O是数量级的符号 ),简称时间复杂度。
计算方法
计算出基本操作的执行次数T(n)
基本操作即算法中的每条语句(以;号作为分割),语句的执行次数也叫做语句的频度。在做算法分析时,一般默认为考虑最坏的情况。
计算出T(n)的数量级
求T(n)的数量级,只要将T(n)进行如下一些操作:忽略常量、低次幂和最高次幂的系数
令f(n)=T(n)的数量级。
用大O来表示时间复杂度
当n趋近于无穷大时,如果lim(T(n)/f(n))的值为不等于0的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n))。
例题
(1) for(i=1;i<=n;i++) //循环了n*n次,当然是O(n^2)
for(j=1;j<=n;j++)
s++;
(2) for(i=1;i<=n;i++)
for(j=i;j<=n;j++)
s++;//循环了(n+n-1+n-2+...+1)≈(n^2)/2,因为时间复杂度是不考虑系数的,所以也是O(n^2)
(3) for(i=1;i<=n;i++)//循环了(1+2+3+...+n)≈(n^2)/2,当然也是O(n^2)
for(j=1;j<=i;j++)
s++;
(4) i=1;k=0;
while(i<=n-1){
k+=10*i;
i++;
}//循环了n-1≈n次,所以是O(n)
(5) for(i=1;i<=n;i++)
for(j=1;j<=i;j++)
for(k=1;k<=j;k++)
x=x+1;
//循环了(1^2+2^2+3^2+...+n^2)=n(n+1)(2n+1)/6(这个公式要记住哦)≈(n^3)/3,不考虑系数,自然是O(n^3)
另外,在时间复杂度中,log(2,n)(以2为底)与lg(n)(以10为底)是等价的,因为对数换底公式:log(a,b)=log(c,b)/log(c,a),所以,log(2,n)=log(2,10)∗lg(n),忽略掉系数,二者当然是等价的
常见的时间复杂度
按数量级递增排列,常见的时间复杂度有:常数阶O(1),对数阶O(log2n),线性阶O(n), 线性对数阶O(nlog2n),平方阶O(n^2),立方阶O(n^3),…, k次方阶O(n^k),指数阶O(2^n) 。
其中:
1.O(n),O(n^2), 立方阶O(n^3),…, k次方阶O(n^k) 为多项式阶时间复杂度,分别称为一阶时间复杂度,二阶时间复杂度…
2.O(2^n),指数阶时间复杂度,该种不实用
3.对数阶O(log2n), 线性对数阶O(nlog2n),除了常数阶以外,该种效率最高
有向图,无向图,连通图,完全图
无向图:即图的边没有方向,边一般用弧形括号表示()
有向图:图的边有方向,边一般用尖括号表示<>
完全图:图的每两个顶点之间有边连接,n个端点的完全图有n个端点以及n(n − 1) / 2条边
连通图:图的每两个顶点之间有路径连接。
一个无向图 G=(V,E) 是连通的,那么边的数目大于等于顶点的数目减一:|E|>=|V|-1,而反之不成立。
如果 G=(V,E) 是有向图,那么它是强连通图的必要条件是边的数目大于等于顶点的数目:|E|>=|V|,而反之不成立。
没有回路的无向图是连通的当且仅当它是树,即等价于:|E|=|V|-1。
线性表
特征
1.集合中必存在唯一的一个“第一元素”。
2.集合中必存在唯一的一个 “最后元素” 。
3.除最后一个元素之外,均有 唯一的后继(后件)。
4.除第一个元素之外,均有 唯一的前驱(前件)
线性表顺序存储结构的优缺点
优点 :
①无须为表中元素之间的逻辑关系而增加额外的存储空间
②可以快速地存取表中任一位置的元素
缺点 :
①插入和删除需要移动大量元素
②当线性表长度变化较大时,难以确定存储空间的容量
③造成存储空间的“碎片”
顺序结构代码实现
获得元素操作
对于线性表的顺序存储结构来说,我们要实现GetElem操作,即将线性表L中的第i个位置元素返回,其实是非常简单的。就程序而言,只要第i个元素在下标范围内,就是把数组第i - 1下表值返回即可。
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
typedef int Status;
//Status是函数的类型,其值是函数结果状态代码,如OK等
//初始条件:顺序线性表L已经存在,1 ≤ i ≤ ListLength(L)
//操作结果:用e返回L中第i个元素的值
Status GetElem(SqList L,int i,ElemType *e)
{
if(L.length == 0 || i < 1 || i > L.length)
return ERROR;
*e = L.data[i - 1];
return OK;
}注意这里返回值类型Status是一个整型,返回OK代表1,ERROR代表0。
插入操作
插入算法的思路:
①如果插入位置不合理,抛出异常;
②如果线性表长度大于等于数组长度,则抛出异常或动态增加容量;
③从最后一个元素开始向前遍历到第i个元素,分别将它们都向后移一位;
④将要插入元素填入位置i处;
⑤表长加1。
//初始条件:顺序线性表L已存在,1 ≤ i ≤ ListLength(L)
//操作结果:在L的第i个位置插入新的数据元素e,L的长度加1
Status ListInsert(SqList *L,int i,ElemType e)
{
int k;
if(L->length == MAXSIZE)//当线性表已满
return ERROR;
if(i < 1 || i >L->length + 1)//当i不在范围内时
{
return ERROR;
}
if(i <= L->length)//若插入数据位置不在表尾
{
for(k = L->length-1;k > i-1;k--)
{
L->data[k + 1] = L->data[k];
}
}
L->data[i - 1] = e;//将新元素插入
L->length++;
return OK;
}删除操作
删除算法的思路:
①如果删除位置不合理,抛出异常;
②取出删除元素;
③从删除元素位置开始遍历到最后一个元素位置,分别将它们向前移动一个位置;
④表长减1。
//初始条件:顺序线性表L已经存在,1 <= i <= ListLength(L)
//操作结果:删除L的第i个元素,并用e返回其值,L的长度减1
Status ListDelete(SqList *L ,int i , ElemType *e)
{
int k;
if(L->length == 0)//线性表为空
return ERROR;
if(i < 1 || i > L->length)//删除位置不正确
return ERROR;
*e = L->data[i];
if(i < L->length)
{
for(k = i;k < L->length;k++)
L->data[k - 1] = L->data[k];
}
L->length--;
return OK;
}线性表的顺序存储结构,在存、读数据时,不管是哪个位置,时间复杂度都是O(1);而插入或删除时,时间复杂度都是O(n)。这说明,它比较适合元素个数不太变化,而更多是存取数据的应用。
链式结构代码实现
获得链表第i个数据的算法思路:
- 声明一个指针p指向链表第一个结点,初始化j从1开始。
- 当j < i 时,就遍历链表,让p的指针向后移动,不断指向下一结点,j累加1;
- 若链表末尾p为空,则说明第i个结点不存在;
- 否则查找成功,返回结点p的数据。
//初始条件:顺序线性表L已存在,1 ≤ i ≤ ListLength(L)
//操作结果:用e返回L中第i个数据元素的值
Status GetElem(LinkList L,int i,ElemType *e)
{
int j;
LinkList p;//声明一指针
p = L->next;//让p指向链表L的第一个结点
j = 1;//j为计数器
while(p && j < i)//p不为空且计数器j还没有等于i时,循环继续
{
p = p->next;//让p指向下也结点
++j;
}
if(p || j > i)
return ERROR;//第i个结点不存在
*e = p->data;//取第i个结点的数据
return OK;
}单链表第i个数据插入结点的算法思路:
- 声明一指针p指向链表头结点,初始化j从1开始;
- 当j < i时,就遍历链表,让p的指针向后移动,不断指向下一结点,j累加1
- 若到链表末尾p为空,则说明第i个结点不存在;
- 若查找成功,在系统中生成一个空节点s;
- 将数据元素e赋给s->data;
- 单链表的插入标准语句s->next = p->next; p->next = s;
- 返回成功
//初始条件:顺序线性表L已存在,1≤i≤ListLength(L)
//操作结果:在L中第i个结点位置之前插入新的数据元素,L的长度加1
Status ListInsert(LinkList *L , int i , ElemType e)
{
int j = 1;
LinkList p,s;
p = *L;
while( p && j < i) //寻找第i个结点
{
p = p->next;
++j;
}
if( !p || j > 1)
{
return ERROR;//第i个结点不存在
}
s = (LinkList)malloc(sizeof(Node));//生成新结点
s->data = e;
s->next = p->next;//将p的后继结点赋值给s的后继
p->next = s;//将s赋给p的后继
return OK;
}单链表第i个数据删除结点的算法思路:
- 声明一指针p指向链表头指针,初始化j从1开始;
- 当j < i时,就遍历链表,让p的指针向后移动,不断指向下一个结点,i累加1;
- 若到链表末尾p为空,则说明第i个结点不存在;
- 否则查找成功,将欲删除的结点p->next 赋给q;
- 单链表的删除标准与p->next = q->next;
- 将q结点中的数据赋给e,作为返回;
- 释放q结点
- 返回成功
//初始条件:顺序线性表L已存在,1≤ i ≤ListLength(L)
//操作结果:删除L的i个结点,并用e返回其值,L的长度减1
Status ListDelete(LinkList *L,int i,ElemType *e)
{
int j;
Link p,q;
p = *L;
j = 1;
while(p->next && j < i)//遍历寻找第i - 1个结点
{
p = p->next;
++j;
}
if( !(p->next) || j > i)
return ERROR;//第i个结点不存在
q = p->next;
p->next = q->next;//将q的后继赋给p的后继
*e = q->data;//将q结点中的数据给e
free(q);//让系统回收此结点,释放内存
return OK;
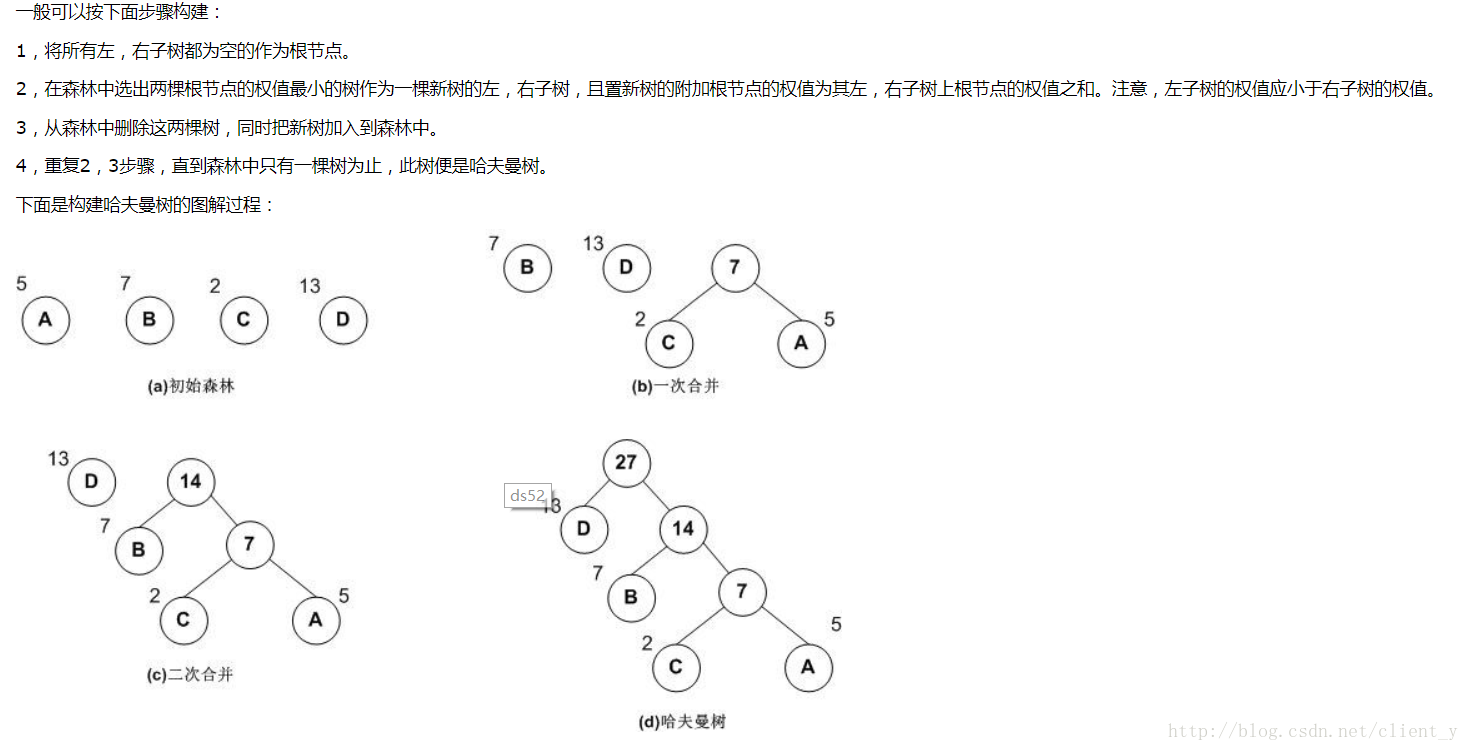
}哈夫曼树
二叉搜索树
二叉查找树是满足以下条件的二叉树:
1.左子树上的所有节点值均小于根节点值;
2右子树上的所有节点值均不小于根节点值;
3.左右子树也满足上述两个条件。
二叉查找树的插入过程如下:1.若当前的二叉查找树为空,则插入的元素为根节点,2.若插入的元素值小于根节点值,则将元素插入到左子树中,3.若插入的元素值不小于根节点值,则将元素插入到右子树中。
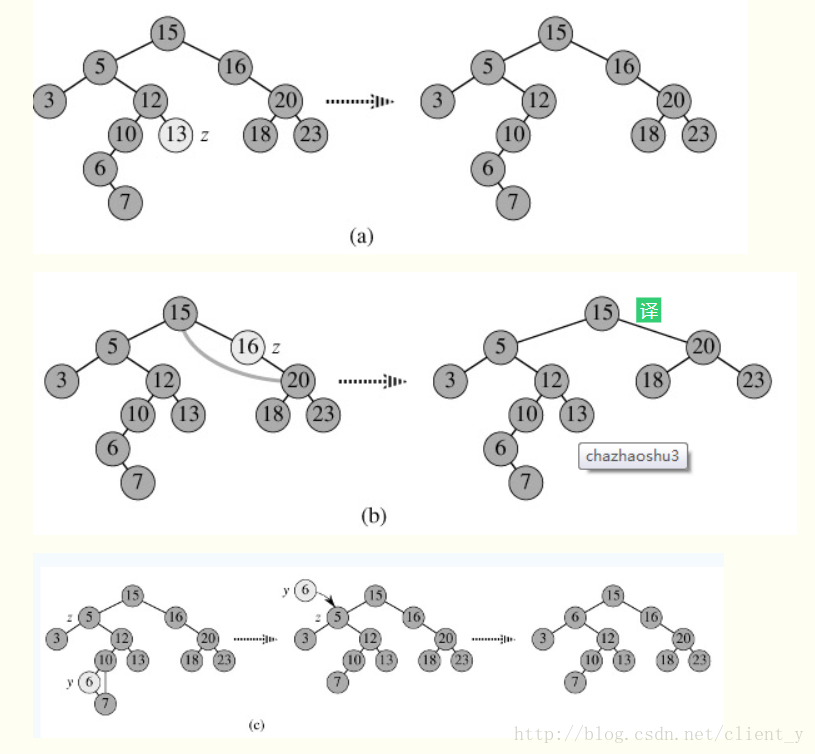
二叉查找树的删除,分三种情况进行处理:
1.p为叶子节点,直接删除该节点,再修改其父节点的指针(注意分是根节点和不是根节点),如图a。
2.p为单支节点(即只有左子树或右子树)。让p的子树与p的父亲节点相连,删除p即可;(注意分是根节点和不是根节点);如图b。
3.p的左子树和右子树均不空。找到p的后继y,因为y一定没有左子树,所以可以删除y,并让y的父亲节点成为y的右子树的父亲节点,并用y的值代替p的值;或者方法二是找到p的前驱x,x一定没有右子树,所以可以删除x,并让x的父亲节点成为y的左子树的父亲节点。如图c。
AVL树
最短路径算法
哈希函数
BFS和DFS
最小生成树
拓扑排序
定义
对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边(u,v)∈E(G),则u在线性序列中出现在v之前。
拓扑排序的实现步骤
1.在有向图中选一个没有前驱的顶点并且输出
2.从图中删除该顶点和所有以它为尾的弧(白话就是:删除所有和它有关的边)
3.重复上述两步,直至所有顶点输出,或者当前图中不存在无前驱的顶点为止,后者代表我们的有向图是有环的,因此,也可以通过拓扑排序来判断一个图是否有环。
参考资料:
1. 坐在马桶上看算法:快速排序
2. 图解排序算法(二)之希尔排序
3. 图基本算法 图的表示方法 邻接矩阵 邻接表
4. 如何计算时间复杂度
5. 算法时间复杂度的计算 [整理]
6. 有向图,无向图,连通图,完全图
7. 线性表的基本概念
8. 二叉查找树–插入、删除、查找
9. 4 张 GIF 图帮助你理解二叉查找树
10. 数据结构图文解析之:AVL树详解及C++模板实现
11. 图的基本算法(BFS和DFS)
12. 数据结构和算法系列16 哈夫曼树
13. 深入理解二叉搜索树(BST)
14. 数据结构—拓扑排序详解
15. AVL树(一)之 图文解析 和 C语言的实现
16. 选择排序
17. 插入排序

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









