






最近想进行强化学习的代码实战,于是学习了该视频课程:更简单的强化学习,代码实战_哔哩哔哩_bilibili
该强化学习课程需要搭建的环境信息:
我的系统是Ubuntu20.04
python==3.9
pytorch==1.12.1(cpu)
gym==0.26.2
pettingzoo==1.23.1
一、安装anconda3虚拟环境
1.1 为了便于管理,需要先装anaconda. 具体下载和安装步骤如下:
Step1. 下载anaconda安装包 .推荐利用清华镜像来下载,下载地址为:
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
根据需要搭建的环境为python==3.9,选择对应的anconda版本,我下载的是Anaconda3-2022.10-Linux-x86_64.sh。其他版本对应关系可查看以下连接
Old package lists — Anaconda documentation
Step2. 安装anaconda。下载完成anaconda后,安装包会在Dowloads文件夹下,在终Ctrl+Alt+T打开终端)键入cd Downloads, 然后键入
bash Anaconda3-2022.10-Linux-x86_64.shStep3. 过程会询问你是否将路径安装到环境变量中,键入yes, 当安装完成。你会在目录/home/你的用户名文件夹下面看到anaconda3文件夹。重新开一个终端,若用户名之前出现(base),即说明环境变量起作用。

1.2. 利用anaconda建一个虚拟环境。
Anaconda创建虚拟环境的格式为:conda create –-name 你要创建的名字 python=版本号。
我创建的虚拟环境名字为gymlab, 用的python版本号为3.9,可这样写:
conda create --name gymlab python=3.9此后,在anaconda3/envs文件夹下多一个gymlab。Python3.9就在gymlab下得lib文件夹中。
在新的终端里,键入以下命令激活虚拟环境
#方式一
source activate gymlab
#方式二
conda activate gymlab二、安装gym
Step1. 在虚拟环境(gymlab)中,键入以下命令安装gym
pip install gym[atari]==0.26.2 -i https://mirrors.aliyun.com/pypi/simpleStep2. 可通过以下步骤检查gym是否正确安装,检查pytorch和pettingzoo同理:
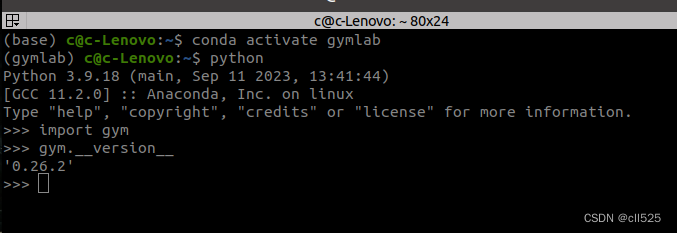
1. 开一个终端(ctr+alt+t), 然后激活用anaconda建立的虚拟环境:
source activate gymlab
2. 运行python:
python
3. 导入gym模块
import gym
4.查看gym的版本
gym.__version__
三、安装pytorch
我这里安装CPU的版本,在虚拟环境(gymlab)中,键入第一条命令安装,若安装GPU的版本,则键入第二条命令安装
# CPU
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cpuonly -c pytorch
# GPU
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.6 -c pytorch -c conda-forge四、安装pettingzoo
在虚拟环境(gymlab)中,键入以下命令安装
pip install pettingzoo[all]==1.23.1














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









