







作者:高斌龙,腾讯云大数据Elasticsearch高级开发工程师
前言
Elasticsearch作为一款基于Lucene打造的分布式搜索引擎,常用于搜索和日志场景,而在数据分析场景,Elasticsearch也提供了聚合Aggregations API支持完成复杂的查询分析,并且可以使用Kibana完成数据的可视化。本文就如何使用Elasticsearch进行数据分析做一个简单的介绍。
概览
聚合分析主要为了解决以下问题:
-
网站的平均加载时间是多久?
-
根据交易记录来看谁是最有价值的客户?
-
每个种类的产品数量是多少?
Elasticsearch的聚合分析API,主要分为三类:
-
Metric: 指标,比如平均值、求和、最大值等,都是指标
-
Bucket: 桶,根据某个字段的值进行的分桶聚合
-
Pipeline: 管道,不基于索引中的原始数据,而是基于其它的聚合结果再次进行统计分析
Bucket聚合
Bucket聚合用于根据指定的字段,统计该字段的不同值的数量,每个不同的值就成为一个Bucket,聚合结果中会返回不同的Bucket中文档的数量。Bucket聚合的种类也是非常多的,常用的有Terms 聚合,Date histogram聚合,Composite聚合。另外,Bucket聚合可以包含嵌套的子聚合。
1. Terms聚合
Terms聚合支持的字段类型有Keyword,Numberic, ip, boolean 以及binary,可以支持统计这些字段类型的字段中不同值的数量。
示例:
请求:
GET /_search
{
"aggs": {
"product": {
"terms": { "field": "productName" }
}
}
}
返回结果:
{
...
"aggregations": {
"product": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "books",
"doc_count": 6
},
{
"key": "clothes",
"doc_count": 3
},
{
"key": "shoes",
"doc_count": 2
}
]
}
}
}
返回结果中的buckets列表默认会按照doc_count进行排序,并返回前10项。更多参数请参考Terms aggregation。(https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-terms-aggregation.html)
2. Date histogram聚合
Date histogram聚合是对Date类型的字段进行统计分析,用于统计一段时间内的文档总数,时间段的起始值即为Bucket的key。
Date histogram聚合对于每个Bucket代表的时间段,又支持两种模式:
-
Calendar日历时间段:按日历中的自然时间确定Bucket,可指定为minute,hour,day,week,month, quarter,year, 例如指定为1d,则每个自然日都会产生一个Bucket,时间跨度从当日的00:00:00到23:59:59.
-
Fixed固定时间段:每个Bucket代表的时间段跨度是定长的,例如指定为1d, 则从1970-01-01为起始值,并且以文档中Date类型字段的起始值所在的Bucket为第一个Bucket,,每隔24小时会有一个bucket产生,即便这些bucket中的文档可能在不同的自然日中产生。
Calendar时间段示例:
GET/sales/_search?size=0
{
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "date_field",
"calendar_interval": "month"
}
}
}
}
返回结果:
{
...
"aggregations": {
"sales_over_time": {
"buckets": [
{
"key_as_string": "2015-01-01",
"key": 1420070400000,
"doc_count": 3
},
{
"key_as_string": "2015-02-01",
"key": 1422748800000,
"doc_count": 2
},
{
"key_as_string": "2015-03-01",
"key": 1425168000000,
"doc_count": 2
}
]
}
}
}
Fixed固定时间段示例:
GET/sales/_search?size=0
{
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "date_field",
"fixed_interval": "30d"
}
}
}
}
返回结果:
"aggregations": { -
"sales_over_time": { -
"buckets": [ -
{ -
"key_as_string": "2021-12-29T00:00:00.000Z",
"key": 1640736000000,
"doc_count": 1
},
{ -
"key_as_string": "2022-01-28T00:00:00.000Z",
"key": 1643328000000,
"doc_count": 2
},
{ -
"key_as_string": "2022-02-27T00:00:00.000Z",
"key": 1645920000000,
"doc_count": 6
}
]
}
}
3. Composite聚合
Composite复合聚合是一个Multi-bucket聚合,bucket的key可以由多个字段组合而成。Composite聚合支持分页查询,在bucket数量比较多的情况下可以分批次获取聚合结果。
Composite聚合通过在sources参数中指定多个value source成分源数据的来构建multi-bucket聚合,sources参数支持的成分源数据类型有Terms,Histogram, Date Histogram和GeoTile Grid聚合,
如果只在sources参数中指定了单一的成分源数据,比如指定为Terms,那么Composite聚合就和普通的Terms聚合几乎没有区别了,优点是可以支持分页获取聚合结果。
GET /_search
{
"size": 0,
"aggs": {
"my_buckets": {
"composite": {
"sources": [
{ "product": { "terms": { "field": "product" } } }
]
}
}
}
}Composite聚合的分页是通过指定size参数和after参数实现的, size参数默认为10, 第一次的查询中会包含一个after_key字段表明当前已经的结果中最后一个bucket的key的值,之后的查询中可以通过指定after参数来实现分页获取。
指定size参数获取指定数量的聚合结果:
GET /_search
{
"size": 0,
"aggs": {
"my_buckets": {
"composite": {
"size": 2,
"sources": [
{ "date": { "date_histogram": { "field": "timestamp", "calendar_interval": "1d" } } },
{ "product": { "terms": { "field": "product" } } }
]
}
}
}
}
返回结果中会包含有after_key字段,值为当前结果中最后一个bucket的key:
{
...
"aggregations": {
"my_buckets": {
"after_key": {
"date": 1494288000000,
"product": "mad max"
},
"buckets": [
{
"key": {
"date": 1494201600000,
"product": "rocky"
},
"doc_count": 1
},
{
"key": {
"date": 1494288000000,
"product": "mad max"
},
"doc_count": 2
}
]
}
}
}
再次发起请求时,指定after字段的值为上一次请求的after_key,实现分页获取聚合结果:
GET /_search
{
"size": 0,
"aggs": {
"my_buckets": {
"composite": {
"size": 2,
"sources": [
{ "date": { "date_histogram": { "field": "timestamp", "calendar_interval": "1d", "order": "desc" } } },
{ "product": { "terms": { "field": "product", "order": "asc" } } }
],
"after": { "date": 1494288000000, "product": "mad max" }
}
}
}
}Metric指标聚合
Metric指标类的聚合诸如avg平均值,max最大值,min最小值等数值类的聚合,在使用中通常作为一个子聚合。
Max最大值聚合
Max最大值聚合用于返回数值类型的字段中的最大值:
GET /_search
{
"size":0,
"aggs": {
"max_price": { "max": { "field": "price" } }
}
}
Stats统计聚合
Stats统计聚合用于统计字段中值的最小值、最大值、总和、平均值以及文档的总数:
请求示例:
GET /_search
{
"size":0,
"aggs": {
"grades_stats": { "stats": { "field": "grade" } }
}
}返回结果:
{
...
"aggregations": {
"grades_stats": {
"count": 2,
"min": 50.0,
"max": 100.0,
"avg": 75.0,
"sum": 150.0
}
}
}Cardinality基数聚合
Cardinalit基数聚合用于统计字段中不同值的数量:
GET /_search
{
"aggs": {
"type_count": {
"cardinality": {
"field": "type"
}
}
}
}Pipeline管道聚合
Pipeline聚合基于其它的Bucket聚合或Metric聚合的结果,再次聚合出新的数据,给原始的聚合结果中增加新的分析数据。Pipeline聚合主要分为两类:
-
Parent:此时的Pipeline聚合作为一个嵌套的子聚合,从它的父聚合的结果中抽取数据,再给父聚合增加新的分析数据
-
Sibling: 此时的Pipeline聚合会从同一级的兄弟聚合的结果中抽取数据,再给兄弟聚合的结果中增加新的分析数据
Pipeline聚合通过buckets_path参数引用父聚合或者兄弟聚合,例如buckets_path指定为"my_bucket>my_stats.avg",意即引用名为"my_bucket"的兄弟聚合中的名为"my_stats"子聚合中的avg指标项。
Max bucket聚合
计算销售额最大的月份是哪个月:
GET sales/_search
{
"size": 0,
"aggs": {
"sales_per_month": {
"date_histogram": {
"field": "date",
"calendar_interval": "month" // 按月分桶,统计每个月的销售条目
},
"aggs": {
"sales": {
"sum": {
"field": "price" // 统计每个月的销售总额
}
}
}
},
"max_monthly_sales": {
"max_bucket": {
"buckets_path": "sales_per_month>sales" // 通过引用同一级的sales_per_month聚合中的子聚合sales,计算销售总额最大的月份
}
}
}
}
返回结果:
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
}
}
]
},
"max_monthly_sales": {
"keys": ["2015/01/01 00:00:00"], // 销售额最大的月份是2015年1月,总金额为550元
"value": 550.0
}
}
}Stats bucket聚合
统计各个月销售额的最大值、最小值、平均值、综合和月份数量:
GET sales/_search
{
"size": 0,
"aggs": {
"sales_per_month": {
"date_histogram": {
"field": "date",
"calendar_interval": "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
}
}
},
"stats_monthly_sales": {
"stats_bucket": {
"buckets_path": "sales_per_month>sales"
}
}
}
}返回结果:
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
}
}
]
},
"stats_monthly_sales": {
"count": 3,
"min": 60.0,
"max": 550.0,
"avg": 328.3333333333333,
"sum": 985.0
}
}
}数据可视化
利用Kibana可是实现数据的可视化,可以通过定义查询语句把我们对数据进行分析的结果进行图标化展示。Kibana针对不同的场景提供了不同的数据可视化使用方式,常用的有Discover、Dashboard以及Maps。
使用Discover可以实现数据的检索,常用于日志数据的查询: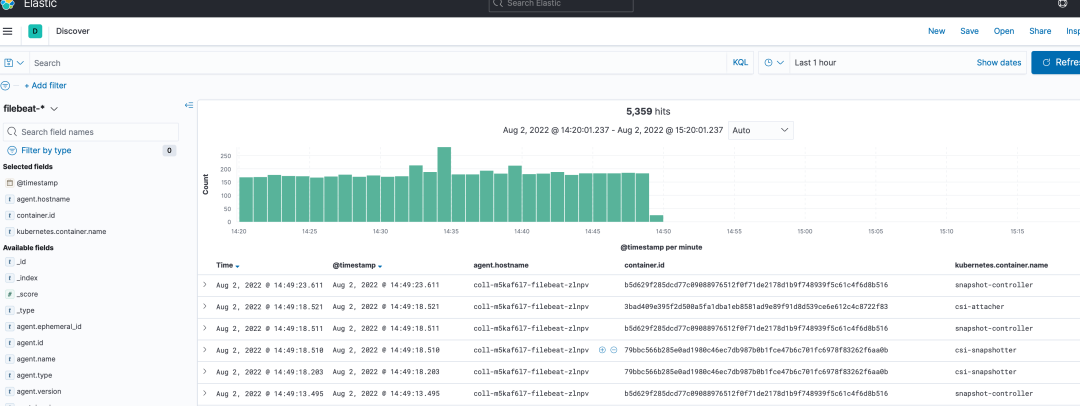
使用Dashboards可以实现实时的数据分析结果展示,常用于监控、APM等场景: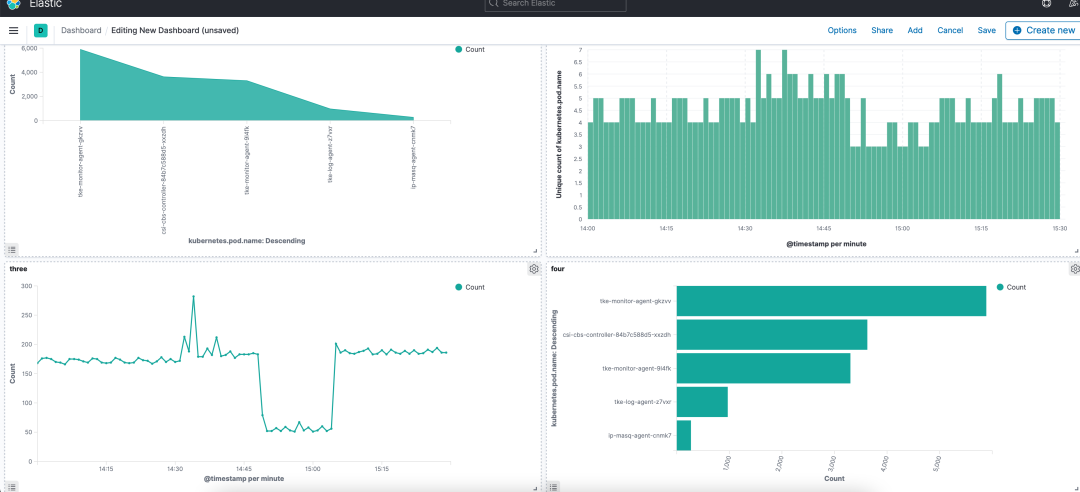
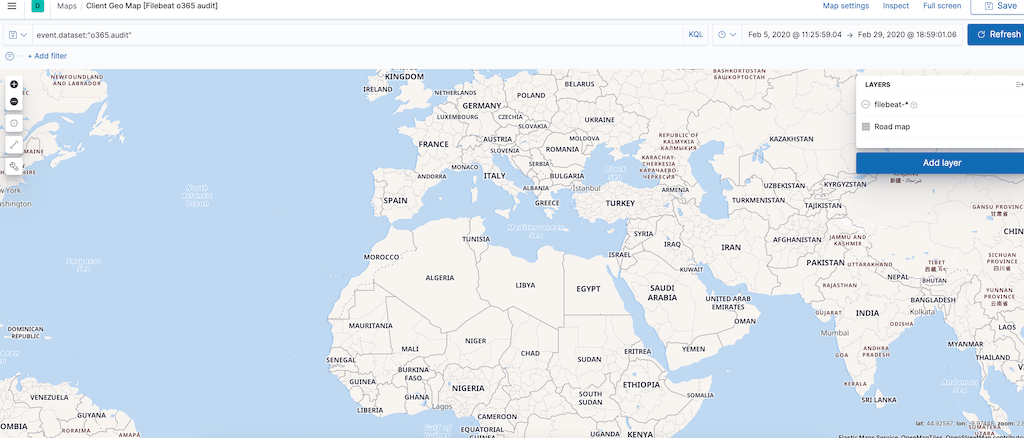
使用Maps可以实现地理位置信息的展示:















 241
241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









