






一:ElasticSearch 检索数据与分析
1.简介

2.基本概念
1、Index(索引)
动词,相当于 MySQL 中的 insert;
名词,相当于 MySQL 中的 Database
2、Type(类型)---->表(废弃)
在 Index(索引)中,可以定义一个或多个类型。
类似于 MySQL 中的 Table;每一种类型的数据放在一起;
3、Document(文档)---->一条条数据
保存在某个索引(Index)下,某种类型(Type)的一个数据(Document),文档是 JSON 格
式的,Document 就像是 MySQL 中的某个 Table 里面的内容;
4.属性 ----->列
3.倒排序机制

4.安装和使用可视化界面
1.在docker中安装
下载镜像
docker pull elasticsearch:7.4.2
下载可视化
docker pull kibana:7.4.2
- 在linux本机创建elasticsearch文件夹(后面将docker中的elastic配置文件与linux本机的配置文件绑定)
#Linux创建目录
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
mkdir -p /mydata/elasticsearch/plugins
# 将一条命令写入linux本机的创建的配置文件中
# es可以被远程任何机器访问
echo "http.host: 0.0.0.0" >/mydata/elasticsearch/config/elasticsearch.yml
# 递归更改权限,es需要访问
chmod -R 777 /mydata/elasticsearch/
- 启动elasticsearch(将elasticsearch映射到本机) 容器卷挂仔
# 9200是用户交互端口 9300是集群心跳端口
# -e指定是单阶段运行
# -e指定占用的内存大小,生产时可以设置32G
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
# 设置开机启动elasticsearch
docker update elasticsearch --restart=always
4.访问测试

5.全文检索ElasticSearchsDocker安装Kibana可视化界面
# 这里-e是自己的elasticsearch服务地址
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.20.132:9200 -p 5601:5601 -d kibana:7.4.2
# 设置开机启动kibana
docker update kibana --restart=always

5.对ElasticSearch的基本操作
1._cat…

GET /_cat/nodes:查看所有节点
GET /_cat/health:查看 es 健康状况
GET /_cat/master:查看主节点
GET /_cat/indices:查看所有索引 show databases;
2.索引一个文档(保存)
保存一个数据,保存在哪个索引的哪个类型下,指定用哪个唯一标识
PUT customer/external/1;在 customer 索引下的 external 类型下保存 1 号数据为
索引名 类型名 标识
PUT customer/external/1
{
"name": "John Doe"
}
PUT 和 POST 都可以,
POST 新增。如果不指定 id,会自动生成 id。指定 id 就会修改这个数据,并新增版本号
PUT 可以新增可以修改。PUT 必须指定 id;由于 PUT 需要指定 id,我们一般都用来做修改
操作,不指定 id 会报错。
3、查询文档
索引名 类型名 标识
GET customer/external/1
结果:
{
"_index": "customer", //在哪个索引
"_type": "external", //在哪个类型
"_id": "1", //记录 id
"_version": 2, //版本号
"_seq_no": 1, //并发控制字段,每次更新就会+1,用来做乐观锁
"_primary_term": 1, //同上,主分片重新分配,如重启,就会变化
"found": true,
"_source": { //真正的内容
"name": "John Doe"
}
}
更新携带 ?if_seq_no=0&if_primary_term=1
4、更新文档
索引名 类型名 标识
POST customer/external/1/_update
{
//要带上doc
"doc":{
"name": "John Doew"
}
}
不同:POST 操作会对比源文档数据,如果相同不会有什么操作,文档 version 不增加
PUT 操作总会将数据重新保存并增加 version 版本;
带_update 对比元数据如果一样就不进行任何操作。
看场景;
对于大并发更新,不带 update;
对于大并发查询偶尔更新,带 update;对比更新,重新计算分配规则。
5、删除文档&索引
删除文档
DELETE customer/external/1
删除索引
DELETE customer
6、bulk 批量 API
POST customer/external/_bulk
{"index":{"_id":"1"}} //index表示新增 一个
{"name": "John Doe" } //表示新增的数据
{"index":{"_id":"2"}}
{"name": "Jane Doe" }
7.加上测试数据
数据地址:
https://gitee.com/xlh_blog/common_content/blob/master/es%E6%B5%8B%E8%AF%95%E6%95%B0%E6%8D%AE.json#

6.测试高级检索
进阶:两种查询方式(Query DSL + 路径参数查询)
查询领域对象语言

1 rest风格 + 参数在请求路径中
GET bank/_search?q=*&sort=account_number:asc
说明:
q=* # 查询所有
sort # 排序字段
asc #升序
 took – 花费多少ms搜索
took – 花费多少ms搜索
timed_out – 是否超时
_shards – 多少分片被搜索了,以及多少成功/失败的搜索分片
max_score –文档相关性最高得分
hits.total.value - 多少匹配文档被找到
hits.sort - 结果的排序key(列),没有的话按照score排序
hits._score - 相关得分 (not applicable when using match_all)
- 进阶 QueryDSL
使用时不要加#注释内容
GET bank/_search
{
"query": { # 查询的字段
"match_all": {}
},
"from": 0, # 从第几条文档开始查
"size": 5,
"_source":["account_number"], #指定只返回account_number字段
"sort": [
{
"account_number": { # 返回结果按哪个列排序
"order": "desc" # 降序
}
}
]
}
7.match全文检索
GET bank/_search
{
"query":{
"match": {
"age":20
//如果不是查询的值不是字符串则进行精确匹配是字符串则进行全文检索
//会分词匹配
}
}
}
GET bank/_search
{
"query":{
"match_phrase": {
"address": "Bainbridge"
//按照这个短语匹配 不会分词了
}
}
}
GET bank/_search
{
"query":{
"multi_match": {
"query": "Bainbridge",
//多个字段分词匹配 条件必须是个词
"fields": ["address","dsadsa"]
}
}
}
8.bool多条件匹配
must:必须达到must所列举的所有条件
must_not:必须不匹配must_not所列举的所有条件。
should:应该满足should所列举的条件。满足条件最好,不满足也可以,满足得分更高
特别注意
should:应该达到should列举的条件,如果到达会增加相关文档的评分,并不会改变查询的结果。如果query中只有should且只有一种匹配规则,那么should的条件就会被作为默认匹配条件并且改变查询结果
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "M"
}
},
{
"match": {
"address": "mill"
}
}
],
"must_not": [
{
"match": {
"age": "18"
}
}
],
"should": [
{
"match": {
"lastname": "Wallace"
}
}
]
}
}
}
9filter过滤查询 不会有相关性得分
GET bank/_search
{
"query":{
"bool": {
"filter": {
"range": { //指定范围区间
"age": {
"gte": 20,
"lte": 30
}
}
}
}
}
}
10.term适用于精确数值匹配
GET bank/_search
{
"query":{
"bool": {
"must": [
{"term": {
"age": {
"value": "20"
}
}}
]
}
}
}
11 属性.keyword
“term”: {
“name.keyword”: “测试名称”
}
相当于对 测试名称进行不分词查询
实现完全匹配 精确匹配 而match_phrase短语匹配 会匹配到这个字段中包含这个短语的
12 .aggregations集合 像执行函数分析一样
聚合(aggregations)可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
桶(Bucket)聚合:用来对文档做分组
TermAggregation:按照文档字段值分组
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
Avg:求平均值
Max:求最大值
Min:求最小值
Stats:同时求max、min、avg、sum等
管道(pipeline)聚合:其它聚合的结果为基础做聚合
“aggs”:{ # 聚合
“aggs_name”:{ # 这次聚合的名字,方便展示在结果集中
“AGG_TYPE”:{} # 聚合的类型(avg,term,terms)
}
}
如果要写同级别的话就可以在一个aggs中写多个aggs名字
如果是嵌套的话 就必须再用aggs声明
搜索 address 中包含 mill 的所有人的年龄分布以及平均年龄,但不显示这些人的详情
GET bank/_search
{
"query":{
"match": {
"address": "mill"
}
},
"size": 0,
"aggs": { //聚合
"AVGage": { // 聚合名字
"terms": { //集合类型 terms用来做分布的
"field": "age",
"size": 100
}
},
"AvG":{ //聚合可以写多个
"avg": {
"field": "age"
}
}
}
}
按照年龄聚合,并且请求这些年龄段的这些人的平均薪
GET bank/_search
{
"query":{
"match_all": {}
},
"aggs": {
"AGE": {
"terms": {
"field": "age",
"size": 100
}, //集合内嵌聚合
"aggs": {
"AVGAGE": {
"avg": {
"field": "balance"
}
}
}
}
}
}
查出所有年龄分布,并且这些年龄段中 M 的平均薪资和 F 的平均薪资以及这个年龄
段的总体平均薪资
GET bank/_search
{
"query": {"match_all": {}},
"aggs": {
"AGE": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"GENN": {
"terms": {
"field": "gender.keyword",
"size": 10
},
"aggs": {
"AVG": {
"avg": {
"field": "balance"
}
}
}
},
"VAG": {
"avg": {
"field": "balance"
}
}
}
}
}
}


13.mapping映射
映射定义文档如何被存储和存储类型和检索的
核心数据类型
(1)字符串
text ⽤于全⽂索引,搜索时会自动使用分词器进⾏分词再匹配
keyword 不分词,搜索时需要匹配完整的值
(2)数值型
整型: byte,short,integer,long
浮点型: float, half_float, scaled_float,double
(3)日期类型:date
(4)范围型
integer_range, long_range, float_range,double_range,date_range
gt是大于,lt是小于,e是equals等于。
age_limit的区间包含了此值的文档都算是匹配。
(5)布尔
boolean
(6)二进制
binary 会把值当做经过 base64 编码的字符串,默认不存储,且不可搜索
复杂数据类型
(1)对象
object一个对象中可以嵌套对象。
(2)数组
Array
嵌套类型
nested 用于json对象数组
1.在创建索引的时候指定属性的存储类型

2.向已经创建好的索引中增加字段
PUT /my_index/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false # 字段不能被检索。检索
}
}
}

14.修改映射之数据迁移
对于已经存在的字段映射,我们不能更新。更新必须创建新的索引,进行数据迁移
相当于把一个表数据传给另一个表
不过另一个表的mapping映射规则可能不同于原表
因为新版本的elasticsearch去除了类型和这个概念
于是数据迁移的写法如下
1.先创建一个字段名字相同 ,字段类型为自己想要的不同的类型的索引
PUT /newbank
{
"mappings": {
"properties" : {
"account_number" : {
"type" : "integer"
},
"address" : {
"type" : "keyword"
},
"age" : {
"type" : "integer"
},
"balance" : {
"type" : "long"
},
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"email" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"employer" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"firstname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"gender" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"lastname" : {
"type" : "text"
},
"state" : {
"type" : "text"
}
}
}
}
2.数据迁移
新写法
POST reindex
{
"source":{
"index":"twitter"
},
"dest":{
"index":"new_twitters"
}
}
老写法
POST reindex
{
"source":{
"index":"twitter",
"twitter":"twitter"
},
"dest":{
"index":"new_twitters"
}
}
15.用开源中文分词器ik
1.去这个地址下载ik 7.4.2
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.4.2
解压到ik文件夹
2.把它传到虚拟机的elasticsearch的容器卷挂仔目录的/mydata/elasticsearch/plugins这个目录下
3.进去容器内部看有无安装好
docker exec -it 5c4c377c9178 /bin/bash
cd bin/
elasticsearch-plugin
看有无ik
4.修改ik目录的权限
chmod -R 777 ik
5.重启elasticsearch容器
docker restart elasticsearch
6.测试
POST _analyze
{ //智能处理
"analyzer": "ik_smart",
"text": ["我是中国人"]
}
结果
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
POST _analyze
{ //按照最大分词来分
"analyzer": "ik_max_word",
"text": ["我是中国人"]
}
结果
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "中国",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "国人",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 4
}
]
}
16.高亮highlight
{
"query": {
"match": {
"FIELD": "TEXT"
}
},
"highlight": {
"fields": { // 指定要高亮的字段
"FIELD": {
"pre_tags": "<em>", // 用来标记高亮字段的前置标签
"post_tags": "</em>" // 用来标记高亮字段的后置标签
}
}
}
}
17.DSL语句查询
// 查询所有
GET /indexName/_search
{
"query": {
"match_all": {
}
}
}
GET /索引库名/_search
{ "query": { "查询类型": { "FIELD": "TEXT"}}}
匹配一个:
{
"query": {
"match": {
"FIELD": "TEXT"
}
}
}
匹配多个
{
"query": {
"multi_match": {
"query": "TEXT",
"fields": ["FIELD1", " FIELD12"]
}
}
}
精确查询:
{
"query": {
"term": {
"FIELD": {
"value": "VALUE"
}
}
}
}
范围查询:
{
"query": {
"range": {
"FIELD": {
"gte": 10,
"lte": 20
}
}
}
}
地理位置查询:
geo_bounding_box:查询geo_point值落在某个矩形范围的所有文档
{
"query": {
"geo_bounding_box": {
"FIELD": {
"top_left": {
"lat": 31.1,
"lon": 121.5
},
"bottom_right": {
"lat": 30.9,
"lon": 121.7
}
}
}
}
}
geo_distance:查询到指定中心点小于某个距离值的所有文档
{
"query": {
"geo_distance": {
"distance": "15km",
"FIELD": "31.21,121.5"
}
}
}
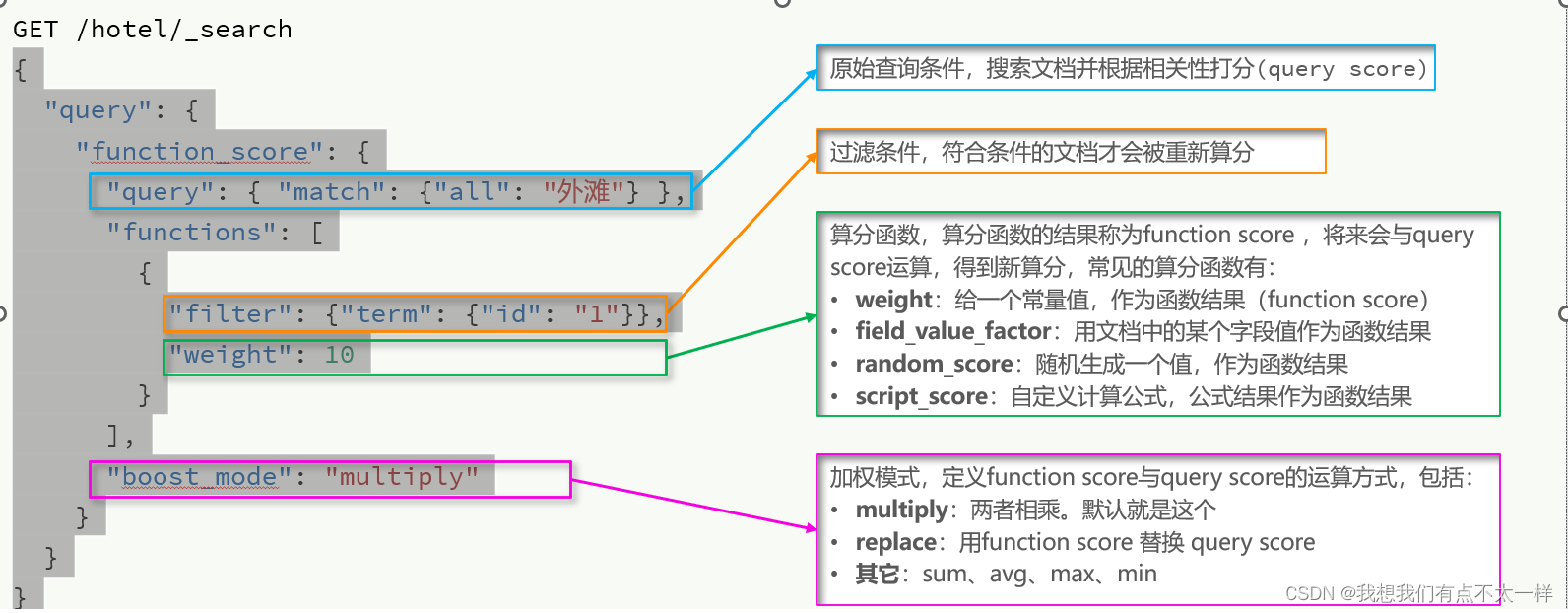
18.得分使用 function score query,可以修改文档的相关性算分(query score),根据新得到的算分排序
{
"query": {
"function_score": {
"query": { "match": {"all": "外滩"} },
"functions": [
{
"filter": {"term": {"id": "1"}},
"weight": 10
}
],
"boost_mode": "multiply"
}
}
}
JAVA语法篇
1.初始化javaClient
1.引入es的RestHighLevelClient依赖:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
2.因为SpringBoot默认的ES版本是7.6.2,所以我们需要覆盖默认的ES版本:
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
3.初始化RestHighLevelClient:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")));
@BeforeEach
void setUp() {
client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")
));
}
@AfterEach
void tearDown() throws IOException {
client.close();
}
2.创建索引库
private RestHighLevelClient client;
@Test
void testCreateIndex() throws IOException {
// 1.准备Request PUT /hotel
CreateIndexRequest request = new CreateIndexRequest("hotel");
// 2.准备请求参数
request.source(MAPPING_TEMPLATE, XContentType.JSON);
// 3.发送请求
client.indices().create(request, RequestOptions.DEFAULT);
}
3.删除索引库判断索引库是否存在
@Test
void testExistsIndex() throws IOException {
// 1.准备Request
GetIndexRequest request = new GetIndexRequest("hotel");
// 3.发送请求
boolean isExists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(isExists ? "存在" : "不存在");
}
@Test
void testDeleteIndex() throws IOException {
// 1.准备Request
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
// 3.发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
}
4.添加数据到索引库
// 1.准备Request
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
// 2.准备请求参数DSL,其实就是文档的JSON字符串
request.source(json, XContentType.JSON);
// 3.发送请求
client.index(request, RequestOptions.DEFAULT);
5.查询数据
// 1.准备Request // GET /hotel/_doc/{id}
GetRequest request = new GetRequest("hotel", "61083");
// 2.发送请求
GetResponse response = client.get(request, RequestOptions.DEFAULT);
6.删除和更新
删除
// 1.准备Request // DELETE /hotel/_doc/{id}
DeleteRequest request = new DeleteRequest("hotel", "61083");
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
更新
// 1.准备Request
UpdateRequest request = new UpdateRequest("hotel", "61083");
// 2.准备参数
request.doc(
"price", "870"
);
// 3.发送请求
client.update(request, RequestOptions.DEFAULT);
7.用bulk桶子添加数据
// 1.创建Bulk请求
BulkRequest request = new BulkRequest();
// 2.添加要批量提交的请求:这里添加了两个新增文档的请求
request.add(new IndexRequest("hotel")].id("101").source("json source", XContentType.JSON));
request.add(new IndexRequest("hotel").id("102").source("json source2", XContentType.JSON));
// 3.发起bulk请求
client.bulk(request, RequestOptions.DEFAULT);
8.高级匹配QueryBuilders 可以构建很多查询条件
matchAll
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.组织DSL参数
request.source()
.query(QueryBuilders.matchAllQuery());
// 3.发送请求,得到响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// ...解析响应结果
9.结果分析(配合kibana去分析结果、、或者程序打断点去分析)
// 4.解析结果
SearchHits searchHits = response.getHits();
// 4.1.查询的总条数
long total = searchHits.getTotalHits().value;
// 4.2.查询的结果数组
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
// 4.3.得到source
String json = hit.getSourceAsString();
// 4.4.打印
System.out.println(json);
}
10.trem和range查询
// 词条查询QueryBuilders.termQuery("city", "杭州");
// 范围查询QueryBuilders.rangeQuery("price").gte(100).lte(150);
// 创建布尔查询BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 添加must条件boolQuery.must(QueryBuilders.termQuery("city", "杭州"));
// 添加filter条件boolQuery.filter(QueryBuilders.rangeQuery("price").lte(250));
11.高亮
request.source().highlighter(new HighlightBuilder().field("name")
// 是否需要与查询字段匹配 .requireFieldMatch(false));
12.按照距离排序geoDistanceSort
// 价格排序request.source().sort("price", SortOrder.ASC);
// 距离排序request.source().sort(SortBuilders.geoDistanceSort("location", new GeoPoint("31.21, 121.5"))
.order(SortOrder.ASC).unit(DistanceUnit.KILOMETERS));
13.聚合编写
request.source().size(0);
request.source().aggregation(
AggregationBuilders.terms("brand_agg").field("brand").size(20));
14.聚合结果解析
// 解析聚合结果
Aggregations aggregations = response.getAggregations();
// 根据名称获取聚合结果
Terms brandTerms = aggregations.get("brand_agg");
// 获取桶List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
// 遍历for (Terms.Bucket bucket : buckets) {
// 获取key,也就是品牌信息
String brandName = bucket.getKeyAsString();
System.out.println(brandName);}















 1090
1090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









