







数据库和Python
持久化存储
在任何应用中,都需要持久化存储,一般有三种基础的存储机制,文件,数据库系统,以及一些混合类型,一种是使用普通文件或者python特定文件进行访问,另一种是使用数据库管理器访问。
数据库
底层存储
数据库通常使用文件系统作为基本的持久化存储,他可以是普通的操作系统文件,专用的操作系统文件,甚至是原始的磁盘分区
数据库
数据库存储可以抽象为一张表,每行数据都有一些字段对应数据库的列,每一列的表定义的集合以及每个表的数据类型放到一起定义了数据库的模式。
数据库可以创建和删除,表也一样。当查询一个数据库的时候,可以一次性取回一次性结果,也可以逐条遍历每个结果行,一些数据库使用游标的概念来提交SQL命令,查询以及获取结果,不管是一次性获取还是逐行获取都可以使用这个概念。
在python中数据库是通过适配器的方式进行访问的,适配器是一个python模块,使用他可以与关系数据库的客户端库(通常是使用C语言编写的)接口相连。一般情况下会推荐所有的python适配器应当符合python数据库特殊兴趣小组的API标准。
python数据库应用的结构,包括使用和没有使用ORM的情况,DB-API是连接到数据库客户端的C语言库接口。
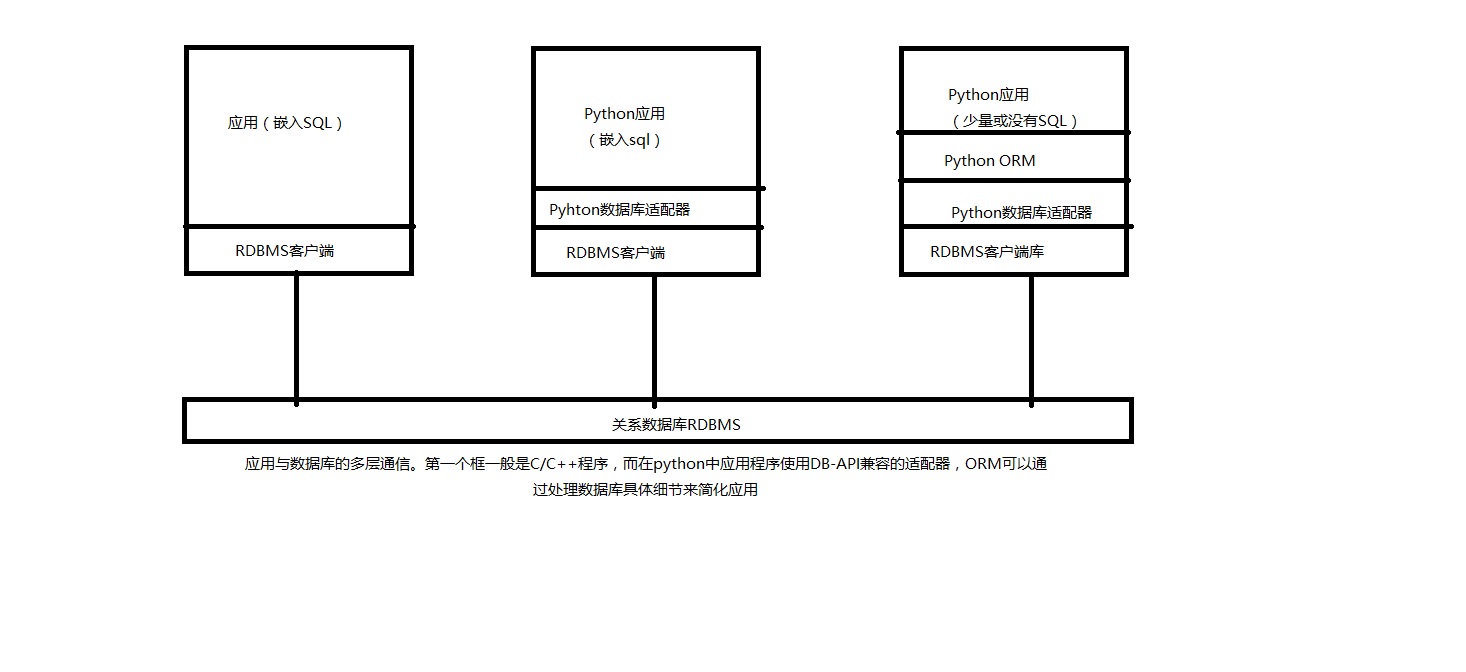
Python的DB-API
DB-API阐明一系列所需对象和数据库访问机制的标准,它可以为不同的数据库适配器和底层数据库系统提供一致性访问。
模块属性
| 属性 | 描述 |
|---|---|
| apilevel | 需要适配器兼容的DB-API版本 |
| threadsafety | 本模块线程安全级别 |
| paramstyle | 本模块sql语句参数风格 |
| connect() | Connect()函数 |
数据属性
apilevel:该字符串指明了模块要兼容的DB-API最高版本,比如,1.0,2.0等,默认值是1.0
threadsafety:这是一个整型值,可选值如下:
- 0,不支持线程安全,线程间不能共享模块
- 1,最小化线程安全支持,线程间可以共享模块,但是不能共享连接
- 2,适度的线程安全支持,线程间可以共享模块和连接,但是不能共享游标
- 3,完整的线程安全支持,线程间可以共享模块,连接和游标
参数风格
该参数是一个字符串,用于指定构建查询行或命令时使用的字符串替代形式
| 参数风格 | 描述 | 示例 |
|---|---|---|
| numeric | 数值位置风格 | WHERE name=:1 |
| named | 命名风格 | WHERE name=:name |
| pyformat | Python字典printf()格式转换 | WHERE name=%(name)s |
| qmark | 问号风格 | WHERE name=? |
| format | ANSIC 的printf()格式风格 | WHERE name=%s |
函数属性
connect()函数通过Connection对象访问数据,兼容模块必须实现connect()函数,该函数创建并返回一个Connection对象.
可以使用包含多个参数的字符串(DSN)来传递数据库连接信息,也可以按照位置传递每个参数,或者是使用关键字参数的形式传入。
例子
connect(dsn="myhost:MYDB",user="guido",password="1234")| 参数 | 描述 |
|---|---|
| user | 用户名 |
| password | 密码 |
| host | 主机名 |
| database | 数据库名 |
| dsn | 数据源名 |
使用DSN还是独立参数主要基于所连接的系统,比如,你使用的像ODBC或者JDBC的API,这需要使用DSN,而如果你直接使用数据库,则更倾向于使用独立的登陆参数,另一个使用独立参数的原因就是很多数据适配器并没有实现对DSN的支持,比如mysqldb使用的db而不是database
- MySQLdb.connect(host=”dbsever”,db=”inv”,user=’root’)
- PgSQL.connect(database=”sales”)
- psycopg.connect(database=”temp”,user=”pgsql”)
- gadfly.dbapi20.connect(‘csrDB’,’/usr/loacl/database’)
- sqlites.connect(‘marketing/test’)
Connection对象
应用与数据库之间进行通信需要建立数据库连接,他是最基本的机制,只有通过数据库连接才能吧命令传递给服务器,并得到返回结果。当一个连接建立后,可以创建一个游标,向数据库发送请求。
Connection对象方法
| 方法名 | 描述 |
|---|---|
| close | 关闭数据库连接 |
| commit | 提交当前事务 |
| rollback | 取消当前事务 |
| cursor | 使用该链接创建(并返回)一个游标或者类游标的对象 |
| errorhandler(cxn,cur,errls,errval) | 作为给定连接的游标的处理程序 |
当使用close()的时候,这个链接将不在使用,否则会进入到异常的处理中
如果数据库不支持事务处理,或者启用了自动提交功能,commit()方法都将无法使用。
和commit()相似,rollback()方法也只有在支持事务处理的数据库中才有用,发生异常之后,rollback()会将数据库的状态恢复到事务处理开始时。
如果RDBMS不支持游标,那么cursor()任然会返回一个尽可能模仿真实游标的对象,这是最基本的要求。
cursor对象
游标可以让用户提交数据库命令,并获得查询的结果行。Python DB-API游标对象总能提供游标的功能。即使是哪些不支持游标的数据库。此时,如果你创建了一个数据库适配器,那必须要实现cursor对象,以扮演类似游标的角色。
当游标创建好后,就可以执行查询或者命令,,并从结果集中取回一行或者多行结果。
| 对象属性 | 描述 |
|---|---|
| arraysize | 使用fetchmany()方法时,一次取出的结果行,默认为1 |
| connection | 创建此游标的连接 |
| description | 返回游标活动状态:(name,type_code,dispaly_size,internal_size,precison,scale,null_ok) |
| lastrowid | 上次修改行的行ID |
| rowcount | 上次execute*()方法处理或影响的行数 |
| callproc(func [,args]) | 调用存储过程 |
| close() | 关闭游标 |
| execute(op [,args]) | 执行数据库查询命令 |
| executemany(op,args) | 类似execute()和map()结合,为给定的所有参数准备并执行数据库查询或者命令 |
| fetchone() | 获取查询结果的下一行 |
| fetchmany([size=cursor.arraysize]) | 获取查询结果的下面size行 |
| fetchall() | 获取查询结果的所有行 |
类型对象和构造函数
| 类型对象 | 描述 |
|---|---|
| Date(yr,mo,dy) | 日期值对象 |
| Time(hr,min,sec) | 时间值对象 |
| Timestamp(yr,mo,dy,hr,min,sec) | 时间戳对象 |
| DateFromTicks(ticks) | 日期对象 |
| TimeFromTicks(ticks) | 时间对象 |
| TimestampFromTicks(ticks) | 时间戳对象 |
| Binary | 对应二进制字符串对象 |
| STRING | 表示基于字符串列的对象,比如varchar |
| BINARY | 表示长二进制列对象 比如 RAW,BLOB |
| NUMBER | 表示数值了列对象 |
| DATETIME | 表示日期/时间了列对象 |
| ROWID | 表示“行ID” 列对象 |
python的MySQLdb模块
数据库:
mysql> desc stu;
+---------------+----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------------+----------+------+-----+---------+----------------+
| stu_id | int(11) | NO | PRI | NULL | auto_increment |
| name | char(32) | NO | | NULL | |
| age | int(11) | NO | | NULL | |
| register_date | date | YES | | NULL | |
+---------------+----------+------+-----+---------+----------------+
4 rows in set (0.00 sec)数据:
mysql> select * from stu;
+--------+------+-----+---------------+
| stu_id | name | age | register_date |
+--------+------+-----+---------------+
| 1 | v1 | 22 | 2016-10-17 |
| 2 | v2 | 24 | 2016-10-17 |
| 3 | v3 | 23 | 2016-10-17 |
| 4 | v2 | 25 | 2016-10-17 |
| 5 | v1 | 25 | 2016-10-17 |
| 6 | v1 | 23 | 2016-10-17 |
+--------+------+-----+---------------+
6 rows in set (0.00 sec)
连接数据库
con=MySQLdb.connect(host='localhost',user='root',passwd='123456',db='notes')
#获取游标
cur=con.cursor()插入数据
t=datetime.datetime.now().strftime("%Y-%m-%d")
name='v5'
reConut=cur.execute("insert into stu (name,age,register_date) values(%s,%s,%s)",(name,22,t))
print reConut
cur.close()
con.close()批量插入数据
li=[
('v6',22,t),
('v7',45,t)
]
reConut=cur.executemany("insert into stu (name,age,register_date) values(%s,%s,%s)",li)
print reConut
con.commit()
cur.close()
con.close()删除数据
reCount=cur.execute("delete from stu where stu_id=11")
print reCount
con.commit()
cur.close()
con.close()修改数据
reCount=cur.execute("update stu set age=%s where name=%s",(78,'v5'))
print reCount
con.commit()
cur.close()
con.close()查找
re=cur.execute("select * from stu")
print re
#print cur,fetchone() #f一条
print cur.fetchall() #所有的
cur.close()
con.close()PostgreSQL
与Mysql不同,PostgreSQL至少包含三种Python适配器:psycopg(推荐),PyPgSQL和PyPgSQL。还有一种适配器,叫PoPy,目前已废弃,并且在2003年将其项目与PyGreSQL进行了合并。
psycopg模块
import psycopg
con=psycopg.connect(user='pgsql')
cur=con.cursor()
cur.execute('select * from pg_database')
rows=cur.fetchall()
for i in rows:
print i
cur.close()
con.commit()
con.close()SQLite
对于简单的应用而言,使用文件作为持久化存储通常就足够了,但是大多数复杂的数据驱动的应用则需要全功能的关系数据库,SQLite的目标则是介于两者之间的中小系统,他量级轻,速度快,没有服务器,很少或者不需要进行管理。
SQLite被打包在Python中,(即sqlite3模块纳入了标准库中)。在标准库中拥有该模块,可以使你在Python中使用SQLite开发更加快速,并且使你在有需要时,能够更加任意的移植到更加强大的RDBMS
import sqlite3
con=sqlite3.connect('sqlite_test/test')
cur=con.cursor()
cur.execute('create table users(login varchar(8)),userid integer')
cur.execute('insert into users values("join",100)')
cur.execute('insert into users values("jane",100)')
cur.execute('select * from users')
for i in cur.fetchall():
print i
"""
(u'join',100)
(u'jane',100)
"""
cur.close()
con.commit()
con.close()ORM
ORM系统的作者将纯SQL语句进行了抽象化处理,将其实现为Python中的对象,这样你只操作这些对象就能完成与生成SQL语句相同的任务。
数据库表被神器的转化为Python类,其中的数据列作为属性,而数据库操作则会作为方法,让你的应用支持ORM与标准数据库适配器有点类似,由于ORM需要代替你执行很多工作,因此一些事情变得更加复杂,或者需要比直接使用适配器更多的代码行。不过,带来了更高的工作效率
python和ORM
目前最知名的python ORM是SQLalchemy和SQLObject,由于设计哲学的不同,这两种ORM也会存在些许区别。
其他一些Python ORM还包括,Storm,PyDO/PyDO2、PDO、Dejavu、Durus、QLime和ForgetSQL。基于web的大型系统也会包含他们自己的ORM组件,如WebWare,MiddieKit和Django的数据库API。
SQLAlchemy
SQLAlchemy是Python编程语言下的一款ORM(对象关系映射)框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
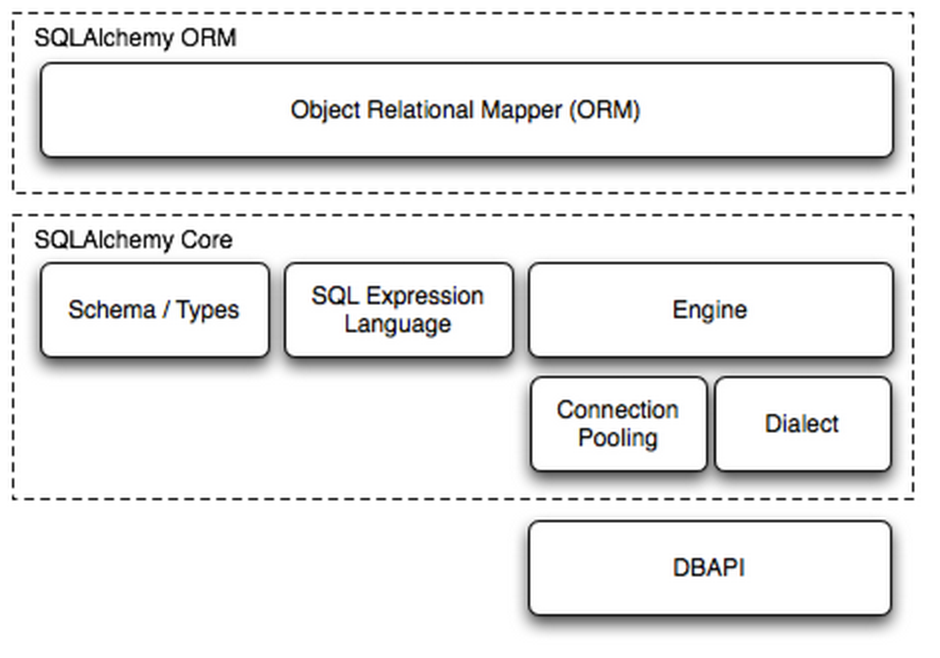
内部处理
Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html使用 Engine/ConnectionPooling/Dialect 进行数据库操作,Engine使用ConnectionPooling连接数据库,然后再通过Dialect执行SQL语句。
from sqlalchemy import create_engine
import datetime
t=datetime.datetime.now().strftime('%Y-%m-%d')
engine=create_engine("mysql+mysqldb://root:123456@localhost:3306/notes",max_overflow=5,echo=True) #最多5个是连接查询,可以查看执行sql语句
#单个插入
engine.execute("insert into stu (name,age,register_date) values('t1',33,%s)",t)
#或者
engine.execute("insert into stu (name,age,register_date) values(%(name)s,%(age)s,%(date)s)",name='t2',age=31,date=t)
#批量插入
engine.execute("insert into stu (name,age,register_date) values(%s,%s,%s)",(('c1',33,t),('c2',43,t)))
#查询
result=engine.execute("select * from stu")
print result.fetchall()
ORM功能使用
创建表
使用 ORM/Schema Type/SQL Expression Language/Engine/ConnectionPooling/Dialect 所有组件对数据进行操作。根据类创建对象,对象转换成SQL,执行SQL
from sqlalchemy import create_engine,Table,Column,Integer,String,MetaData,ForeignKey
metadata=MetaData() #创建一个元数据对象,就是用来描述数据的数据,就跟字典里的词一样
#接下来我们来创建两个表
user=Table(
'user',metadata,
Column('id',Integer,primary_key=True), #默认自动加1
Column('name',String(20))
)
colo=Table(
'color',metadata,
Column('id',Integer,primary_key=True),
Column('name',String(20))
)
engine=create_engine("mysql+mysqldb://root:123456@localhost:3306/notes",max_overflow=5)
#创建
metadata.create_all(engine)
#metadata.clear()
#metadata.remove()创建结果
mysql> desc user;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)
mysql> desc color;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)增删查改
代码前部分
from sqlalchemy import create_engine,Table,Column,Integer,String,MetaData,ForeignKey
metadata=MetaData() #创建一个元数据对象,就是用来描述数据的数据,就跟字典里的词一样
#接下来连接数据库
user=Table(
'user',metadata,
Column('id',Integer,primary_key=True), #默认自动加1
Column('name',String(20))
)
colo=Table(
'color',metadata,
Column('id',Integer,primary_key=True),
Column('name',String(20))
)
engine=create_engine("mysql+mysqldb://root:123456@localhost:3306/notes",max_overflow=5)
con=engine.connect()插入数据
#插入
sql=user.insert().values(id=123,name='cheng')
sql1=user.insert().values(id=134,name='wang')
sql2=user.insert().values(id=111,name='chow')
#提交执行
con.excete(sql)
con.execute(sql2)
con.execute(sql1)
mysql> select * from user;
+-----+-------+
| id | name |
+-----+-------+
| 111 | chow |
| 123 | cheng |
| 134 | wang |
+-----+-------+
3 rows in set (0.00 sec)
删除
sql=user.delete().where(user.c.id>123)
con.execute(sql)
mysql> select * from user;
+-----+-------+
| id | name |
+-----+-------+
| 111 | chow |
| 123 | cheng |
+-----+-------+
更新
sql = user.update().where(user.c.name == 'chow').values(name='ed')
con.execute(sql)
mysql> select * from user;
+-----+-------+
| id | name |
+-----+-------+
| 111 | ed |
| 123 | cheng |
+-----+-------+
2 rows in set (0.00 sec)查询
from sqlalchemy import create_engine,Table,Column,Integer,String,MetaData,ForeignKey,select
sql=select([user,])
result=con.execute(sql)
print result.fetchall() #[(111L, 'ed'), (123L, 'cheng')]
sql1=select([user.c.name,])
result=con.execute(sql1)
print result.fetchall()
sql=select([user.c.name,colo.c.name]).where(user.c.id==colo.c.id)
result=con.execute(sql)
print result.fetchall() #[('ed', 'kk')]
# sql = select([user.c.name]).order_by(user.c.name)
# sql = select([user]).group_by(user.c.name)
#result=con.execute(sql)
print result.fetchall()
con.close()
继承SqlORM类来操作数据库
使用 ORM/Schema Type/SQL Expression Language/Engine/ConnectionPooling/Dialect 所有组件对数据进行操作。根据类创建对象,对象转换成SQL,执行SQL。
使用类创建表
#coding:utf-8
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import String,Column,Integer,select
from sqlalchemy.orm import sessionmaker
Base=declarative_base() #生成一个sqlORM基类,这个基类封装了metadata这些
#链接数据库
engine=create_engine("mysql+mysqldb://root:123456@localhost:3306/notes",echo=True) #echo可以看见创建过程
#创建一个host表
class Host(Base):
__tablename__='host'
id=Column(Integer,primary_key=True,nullable=False,autoincrement=True)
hostname=Column(String(64),unique=True,nullable=True)
ip_addr=Column(String(128),unique=True,nullable=True)
port=Column(Integer,default=22)
#创建所有表结构
Base.metadata.create_all(engine)
"""
创建过程
CREATE TABLE host (
id INTEGER NOT NULL AUTO_INCREMENT,
hostname VARCHAR(64),
ip_addr VARCHAR(128),
port INTEGER,
PRIMARY KEY (id),
UNIQUE (hostname),
UNIQUE (ip_addr)
)
"""
if __name__ == '__main__':
#创建完成后,就可以开始使用了
SessionCls=sessionmaker(bind=engine) #创建与数据库回话的session,注意,这里返回sessionCls是类,不是实例
session=SessionCls()
#增加
# h1=Host(hostname="localhost",ip_addr="127.0.0.1")
# h2=Host(hostname="ubuntu",ip_addr="192.168.2.243")
# h3=Host(hostname="kali",ip_addr="172.17.135.1")
# h4=Host(hostname="win32",ip_addr="10.0.0.1")
#添加到session中
# session.add(h1)
# session.add_all([h2,h3])
# session.add(h4)
#只要没有提交在这里也能修改,
# h4.hostname="windows"
# session.rollback() #如果事件没有完成,可以在提交之前使用这个函数回滚数据库
#提交
session.commit()
建立表
mysql> select * from host;
+----+-----------+---------------+------+
| id | hostname | ip_addr | port |
+----+-----------+---------------+------+
| 1 | localhost | 127.0.0.1 | 22 |
| 2 | ubuntu | 192.168.2.243 | 22 |
| 3 | kali | 172.17.135.1 | 22 |
| 4 | windows | 10.0.0.1 | 22 |
+----+-----------+---------------+------+
4 rows in set (0.00 sec)基本的增删查改
删除
session.query(Host).filter(Host.id>3).delete() #DELETE FROM host WHERE host.id > %s
#提交
session.commit()
"""
mysql> select * from host;
+----+-----------+---------------+------+
| id | hostname | ip_addr | port |
+----+-----------+---------------+------+
| 1 | localhost | 127.0.0.1 | 22 |
| 2 | ubuntu | 192.168.2.243 | 22 |
| 3 | kali | 172.17.135.1 | 22 |
+----+-----------+---------------+------+
3 rows in set (0.00 sec)
"""修改
session.query(Host).filter(Host.id==1).update({'ip_addr':'127.0.0.2','port':34})
#UPDATE host SET ip_addr=%s, port=%s WHERE host.id = %s
session.commit()
"""
mysql> select * from host;
+----+-----------+---------------+------+
| id | hostname | ip_addr | port |
+----+-----------+---------------+------+
| 1 | localhost | 127.0.0.2 | 34 |
| 2 | ubuntu | 192.168.2.243 | 22 |
| 3 | kali | 172.17.135.1 | 22 |
+----+-----------+---------------+------+
3 rows in set (0.00 sec)
"""
查询
#查询
ret=session.query(Host).filter_by(hostname='kali').all()
#如果是查询一条数据
#ret=session.query(Host).filter_by(hostname='kali').first()
"""
SELECT host.id AS host_id, host.hostname AS host_hostname, host.ip_addr AS host_ip_addr, host.port AS host_port
FROM host WHERE host.hostname = %s
"""
for i in ret:
print i.id,i.hostname,i.ip_addr #3 kali 172.17.135.1
查找二:查找hostname中是localhost或者kali的行信息
ret=session.query(Host).filter(Host.hostname.in_(['kali','localhost'])).all()
"""
SELECT host.id AS host_id, host.hostname AS host_hostname, host.ip_addr AS host_ip_addr, host.port AS host_port
FROM host WHERE host.hostname IN (%s, %s)
"""
for i in ret:
print ">>>",i.hostname,i.port
">>> localhost 34"
">>> kali 22"
方式三:查询host表根据id排序
ret=session.query(Host).order_by(Host.id).all()
"""
SELECT host.id AS host_id, host.hostname AS host_hostname, host.ip_addr AS host_ip_addr, host.port AS host_port
FROM host ORDER BY host.id
"""
for i in ret:
print ">>>", i.hostname
"""
>>> localhost
>>> ubuntu
>>> kali
"""
方式四:查询Host表里根据id排序输入0到2的字段
ret = session.query(Host).order_by(Host.id)[0:2]
print ret
for i in ret:
print(i.hostname)
print(i.hostname)
"""
localhost
ubuntu
"""
方式五:创建Query查询,filter是where条件,最后调用one()返回唯一行,如果调用all()则返回所有行:
host = session.query(Host).filter(Host.id == 2).one()
"""
SELECT host.id AS host_id, host.hostname AS host_hostname, host.ip_addr AS host_ip_addr, host.port AS host_port
FROM host
WHERE host.id = %s
"""
# 打印类型和对象的name属性:
print 'name:', host.hostname #name: ubuntu
常见的查询方法
- filter_by():将指定列的值作为关键字参数以获取查询结果
- filter():与filter_by()相似,不过更加灵活,还可以使用表达式。query.filter_by(userid=1)与query.filter(User.userid==1)相同
- order_by():与SQL的ORDER BY指令相似,默认情况下是升序的,需要到日sqlalchemy.desc()使其降序排列
- limit():与SQL的LIMIT指令类似
- offset():与SQL的offset指令类似
- all():返回匹配查询的所有对象
- one():返回匹配查询的唯一一个对象
- first():返回匹配的第一个对象
- join():按照给定的JOIN条件创建SQL JOIN对象
- update():批量更新行
- delete():批量删除行
一个完整的例子
声明层使用
#!/usr/bin/env python
#coding:utf-8
from distutils.log import warn as printf
from os.path import dirname
from random import randrange as rand
from sqlalchemy import Column,String,create_engine,Integer,exc,orm
from sqlalchemy.ext.declarative import declarative_base
DBNAME='test2'
NAMELEN=16
FILEDS=('login','userid','projd')
#定制字符串的格式
tformat=lambda s:str(s).title().ljust(10)
cformat=lambda s:s.upper().ljust(10)
RDBMSs={'s':'sqlite','m':'mysql','g':'gadfly'}
NAMES=(
('a',1232),('b',4545),('c',2343),('d',7345),
('e',3456),('f',5677),('g',6765),('h',3434),
('i',4566),('j',6755),('k',3466),('l',4544)
)
def randName():
pick=set(NAMES)
while pick:
yield pick.pop()
def setup():
return RDBMSs[raw_input("""
Choose a database system:
(M)ysql
(G)adfly
(S)QLite
Enter choice:""").strip().lower()[0]]
DSNs={
'mysql':'mysql+mysqldb://root:123456@localhost:3306/%s'%DBNAME,
'sqlite':'sqlite:///:memory'
}
Base=declarative_base()
class Users(Base): #子类继承这个Base类
__tablename__='users' #定义了映射的数据库名,可以写成__table__
#列属性
login=Column(String(NAMELEN),nullable=False)
userid=Column(Integer,primary_key=True,nullable=False)
projid=Column(Integer)
def __str__(self):
return ''.join(map(tformat,(self.userid,self.login,self.projid))) #将序列中的每一个元素取出来传入函数中,再将函数结果的返回值组成一个新的序列
class SQLAlchemyTest(object):
def __init__(self,dsn):
try:
eng=create_engine(dsn,echo=True) #创建数据库引擎
except ImportError: #出现这个错误,意味着SQLalchemy不支持所选的数据库
raise RuntimeError()
try:
eng.connect() #尝试连接数据库
except exc.OperationalError: #连接不上说明也可能不存在这个数据库,于是我们创建这个数据库
eng=create_engine(dirname(dsn)) # mysql+mysqldb://root:123456@localhost:3306
eng.execute('create database %s'%DBNAME).close()
eng=create_engine(dsn,echo=True) #重新创建数据库引擎
Base.metadata.create_all(eng) #创建所有表结构
Session=orm.sessionmaker(bind=eng) #创建一个会话对象,用于管理单独的事物对象
self.ses=Session()#当涉及一个或者对个数据库操作时,可以保证所有要写入的数据都必须提交,然后将这个会话对象保存
#得结合使用
self.users=Users.__table__
self.eng=self.users.metadata.bind=eng #引擎与表的元数据进行额外的绑定,意味着这张表的所有操作都会绑定到这个指定的引擎中
def insert(self):
self.ses.add_all(
Users(login=who,userid=userid,projid=rand(1,5)) for who,userid in randName()
)
self.ses.commit()
def update(self):
fr=rand(1,5)
to=rand(1,5)
i=-1
#使用query.filter_by()方法进行查找
users=self.ses.query(Users).filter_by(projid=fr).all()
for i,user in enumerate(users):
user.projid=to
self.ses.commit()
return fr,to,i+1
def delete(self):
rm=rand(1,5)
i=-1
users=self.ses.query(Users).filter_by(projid=rm).all()
for i,user in enumerate(users):
self.ses.delete(user)
self.ses.commit()
return rm,i+1
def dbDump(self):
printf('\n%s'%''.join(map(cformat,FILEDS)))
users=self.ses.query(Users).all()
for user in users:
printf(user)
self.ses.commit()
#授权
def __getattr__(self, item):
return getattr(self.users,item)
def finish(self):
self.ses.connection().close()
def main():
printf("***Connect to %r database"%DBNAME)
db=setup()
print db
if db not in DSNs:
printf('\nERROR:%r not supported,exit'%db)
return
try:
orm=SQLAlchemyTest(DSNs[db])
except RuntimeError:
printf('\nERROR:%r not supported.exit'%db)
printf('\n***Create users trable (drop old one if appl)')
orm.drop()
orm.create()
printf('\n*** Insert names into tables')
orm.insert()
orm.dbDump()
printf('\n*** Move users to a random group')
fr,to,num=orm.update()
printf('\t(%d users moved) from (%d) to (%d)'%(num,fr,to))
orm.dbDump()
printf('\n*** Randomly delete group')
rm,num=orm.delete()
printf('\t(group #%d; %d users removed)'%(rm,num))
orm.dbDump()
printf('\n***Drop users table')
orm.drop()
printf('\n***Close cxns')
orm.finish()
if __name__ == '__main__':
main()显式使用
#! /usr/bin/env python
#coding:utf-8
from distutils.log import warn as printf
from random import randrange as rand
from sqlalchemy import Column,String,Integer,create_engine,orm,exc,MetaData,Table
from os.path import dirname
DBNAME='orm_test2'
NAMELEN=16
FILEDS=('login','userid','projd')
#定制字符串的格式
tformat=lambda s:str(s).title().ljust(10)
cformat=lambda s:s.upper().ljust(10)
RDBMSs={'s':'sqlite','m':'mysql','g':'gadfly'}
NAMES=(
('a',1232),('b',4545),('c',2343),('d',7345),
('e',3456),('f',5677),('g',6765),('h',3434),
('i',4566),('j',6755),('k',3466),('l',4544)
)
def randName():
pick=set(NAMES)
while pick:
yield pick.pop()
def setup():
return RDBMSs[raw_input("""
Choose a database system:
(M)ysql
(G)adfly
(S)QLite
Enter choice:""").strip().lower()[0]]
DSNs={
'mysql':'mysql+mysqldb://root:123456@localhost:3306/%s'%DBNAME,
'sqlite':'sqlite:///:memory'
}
class SQLAlchemyTest(object):
def __init__(self,dsn):
try:
eng=create_engine(dsn)
except ImportError:
raise RuntimeError()
try:
con=eng.connect()
except exc.OperationalError:
try:
eng=create_engine(dirname(dsn))
eng.execute('create database %s charset "utf8"'%DBNAME).close()
eng=create_engine(dsn)
con=eng.connect()
except exc.OperationalError:
raise RuntimeError()
metabase=MetaData()
self.eng=metabase.bind=eng
try:
users=Table('users',metabase,autoload=True) #是否存在这个表,存在就自动加载,否则抛出异常,重新创建这个表
except exc.NoSuchTableError:
users=Table(
'users',metabase,
Column('login',String(NAMELEN)),
Column('userid',Integer),
Column('projid',Integer),
)
self.con=con
self.users=users
def insert(self):
d=[dict(zip(FILEDS,[who,uid,rand(1,5)])) for who,uid in randName()]
return self.users.insert().execute(*d).rowcount
def update(self):
users=self.users
fr=rand(1,5)
to=rand(1,5)
return (fr,to, users.update(users.c.projid==fr).execute(projid=to).rowcount)
def delete(self):
users=self.users
rm=rand(1,5)
return (rm,users.delete(users.c.projid==rm).execute().rowcount)
def dbDump(self):
printf('\n%s'%''.join(map(cformat,FILEDS)))
users=self.users.select().execute()
for user in users.fetchall():
printf(''.join(map(tformat,(user.login,user.userid,user.projid))))
def __getattr__(self, item):
return getattr(self.users,item)
def finish(self):
self.con.close()
def main():
printf('\n***Connect to %r database'%DBNAME)
db=setup()
if db not in DSNs:
printf('\nERROR:%r not supported.exit'%db)
return
try:
orm=SQLAlchemyTest(DSNs[db])
except RuntimeError:
printf('\nERROR:%r not supported.exit'%db)
return
printf('\n***Create users table (drop old one if appl.)')
orm.drop(checkfirst=True)
orm.create()
printf('\n***Insert name into table')
orm.insert()
orm.dbDump()
printf('\n***Move users to a random group')
fr,to,num=orm.update()
printf('\t(%d users moved) from (%d) to (%d)'%(num,fr,to))
orm.dbDump()
printf('\n***Randomly delete group')
rm,num=orm.delete()
printf('\t(group #%d; %d users removed'%(rm,num))
orm.dbDump()
printf('\n***Drop users table')
orm.drop()
printf('\n***Close con')
orm.finish()
if __name__ == '__main__':
main()MongoDB
他是介于简单的键-值对存储(如redis,Voldemort,Amazon Dynamo等)与列存储之间,他有点像关系数据库的无模式衍生品,比基于列的存储更简单,约束更少,但是比普通的键值对存储更加灵活,一般情况下其数据会另存为JSON对象,并且允许诸如字符串,数值,列表设置嵌套等数据类型。
尽管python中有很多MongoDB驱动程序,不过最正式的是PyMongo。
ubuntu安装:
sudo apt-get install mongodb启动
cmustard@cmustard:/var$ mongo
MongoDB shell version: 2.6.10
connecting to: test
Welcome to the MongoDB shell.
For interactive help, type "help".
For more comprehensive documentation, see
http://docs.mongodb.org/
Questions? Try the support group
http://groups.google.com/group/mongodb-user
> ls
function ls() { [native code] }
> show dbs
admin (empty)
local 0.078GB
> use test
switched to db test
> show dbs
admin (empty)
local 0.078GB
test (empty)
> db.post.insert({'Title':'Test','Name':'cmustard'})
WriteResult({ "nInserted" : 1 })
> db.post.findOne()
{
"_id" : ObjectId("580ef9c273a1b01482410a74"),
"Title" : "Test",
"Name" : "cmustard"
}
bye帮助
> help
db.help() help on db methods
db.mycoll.help() help on collection methods
sh.help() sharding helpers
rs.help() replica set helpers
help admin administrative help
help connect connecting to a db help
help keys key shortcuts
help misc misc things to know
help mr mapreduce
show dbs show database names
show collections show collections in current database
show users show users in current database
show profile show most recent system.profile entries with time >= 1ms
show logs show the accessible logger names
show log [name] prints out the last segment of log in memory, 'global' is default
use <db_name> set current database
db.foo.find() list objects in collection foo
db.foo.find( { a : 1 } ) list objects in foo where a == 1
it result of the last line evaluated; use to further iterate
DBQuery.shellBatchSize = x set default number of items to display on shell
exit quit the mongo shell
代码实例
#!/usr/bin/python
#coding:utf-8
from distutils.log import warn as printf
from random import randrange as rand
import pymongo
from pymongo import errors
DBNAME='mongo_test'
NAMELEN=16
FILEDS=('login','userid','projid')
NAMES=(
('a',1232),('b',4545),('c',2343),('d',7345),
('e',3456),('f',5677),('g',6765),('h',3434),
('i',4566),('j',6755),('k',3466),('l',4544)
)
#定制字符串的格式
tformat=lambda s:str(s).title().ljust(10)
cformat=lambda s:s.upper().ljust(10)
def randName():
pick=set(NAMES)
while pick:
yield pick.pop()
COLLECTION='users' #集合的名字
class MongoTest(object):
def __init__(self):
try:
con=pymongo.MongoClient() #链接mongoDB数据库
except errors.AutoReconnect:
raise RuntimeError()
self.con=con
self.db=con[DBNAME] #连接数据库mongo_test
self.users=self.db[COLLECTION]
def insert(self):
self.users.insert(
dict(login=who,userid=uid,projid=rand(1,5)) for who,uid in randName()
)
def update(self):
fr=rand(1,5)
to=rand(1,5)
i=-1
for i,user in enumerate(self.users.find({'projid':fr})): #集合的find方法将查询条件传进去
self.users.update(user,{'$set':{'projid':to}}) #$set指令可以显式的修改已经存在的值
return fr,to,i+1
def delete(self):
rm=rand(1,5)
i=-1
for i ,user in enumerate(self.users.find({'projid':rm})):
self.users.remove(user) #找到之后执行remove删除操作
return rm,i+1
def dbDump(self):
printf('\n%s' %''.join(map(cformat,FILEDS)))
for user in self.users.find():
printf(''.join(map(tformat,(user[k] for k in FILEDS))))
def finish(self):
self.con.close() #关闭数据库
#授权
def __getattr__(self, item):
return getattr(self.con,item)
def main():
printf('***Connect to %r database'%DBNAME)
try:
mongo=MongoTest()
except RuntimeError:
printf('\nERROR:MongoDB server unreachable,exit')
return
printf('\n***Insert names into table')
mongo.insert()
mongo.dbDump()
printf('\n***Move users to a random group')
fr,to,num=mongo.update()
printf('\t(%d users moved) from (%d) to (%d) '%(num,fr,to))
mongo.dbDump()
printf('\n*** Randomly delete group')
rm,num=mongo.delete()
printf('\t(group #%d; %d users removed) '%(rm,num))
mongo.dbDump()
printf('\n***Drop users table')
mongo.drop_database(DBNAME)
printf('\n***Close conn')
mongo.finish()
if __name__ == '__main__':
main()














 1168
1168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









