







主要内容翻译自github kudu docs/tablet.md(翻译有些也不是很准确),自己做了一些补充
1 概述
tablet是Kudu表的水平分区,类似于BigTable中的tablet或HBase中的region。每个tablet都包含一个连续的行范围,该行范围不与任何其他tablet的范围重叠。table中的所有tablet共同构成了table的整个键空间。
每个tablet又细分为许多行集合,称为行集。每个RowSet包含一组行的数据。 RowSet是不相交的,即不同RowSet的行集不相交,因此任何给定键最多存在一个RowSet中。当行集不相交时,它们的键空间可能会重叠。
一个行集保存在内存中,称为MemRowSet。所有插入都直接进入MemRowSet,它是一个内存B树,按表的主键排序。插入数据后,数据会累积在MemRowSet中,在此之后,根据MVCC,该数据将立即显示给以后的读操作者。
与BigTable不同的是,只有最近插入数据的插入和更新才进入MemRowSet。每行仅存在于MemRowSet中的一个条目中。 此项的值包含一个特殊的标头,后跟行数据的打包格式。 由于MemRowSet完全在内存中,因此它将最终填满并“刷新”到磁盘形成DiskRowSet(真实存储为一系列的cfile)。

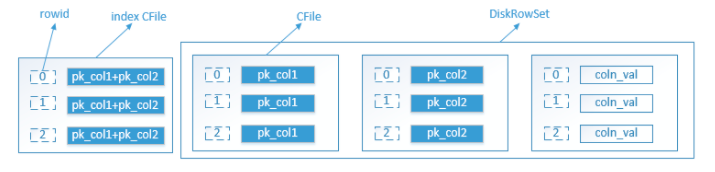
下面介绍下图中主要概念:
- MemRowSet:MemRowSet是一个按主键排序的内存B-tree(一行数据对应这个B-tree的一个entry,即一个MRSRow实例),数据插入时都会先进入MemRowSet,然后数据就对查询可见了,而为了维持快照的一致性(可以理解为并发读写某行数据时候,可以读到自己正确的快照数据),那么就要求对每行数据的所有修改(叫做mutation)都需要保存下来,形成一个mutation链表,作为该行的redo log。当内存满后,MemRowSet会刷到磁盘中形成DiskRowSet,然后再创建新的MemRowSet。每个RowSet中仅存在一个MemRowSet
- DiskRowSet:MemRowSet刷到存盘形成DiskRowSet,而DiskRowSet真正存储为一系列的cfile;每个DiskRowSet中的每行记录都会对应一个"rowid" (DiskRowSet有点像数组,"rowid"对应一个数组下标且对使用者不可见),"rowid"与主键之间会有一个映射关系
-
- 当主键为单列主键时,“rowid"其实就内置在存储主键列的cfile中,主键是排序存储的,所以每个主键默认对应着一个"rowid”,通过主键获得"rowid",然后再从其它cfile快速定位其它列,这个就是所谓的主键索引

-
- 当主键为复合主键时,会有一个单独的索引文件(index cfile,即Ad_hoc Index)保存着编码后的复合主键,这样就可以像单主键提供一样的功能
2 MVCC
2.1 概述
Kudu使用多版本并发控制来提供许多有用的功能:
- 快照扫描器(snapshot scanners):当创建一个扫描器时,它将作为tablet的一个时间点快照进行操作。在扫描过程中发生的对tablet的任何进一步更新都将被忽略。此外,这个时间点可以存储和重用,以便在同一tablet上进行额外的扫描,例如,如果应用程序希望执行分析,需要对一致的数据视图进行多次传递。
- 时间旅行扫描器(Time-travel scanners):与上面类似,用户可以创建一个扫描器,它可以从过去的某个时间点运行,提供一致的“时间旅行读取”。这可以用于执行时间点一致的备份。
- 更改历史查询:给定两个MVCC快照,用户可以查询任意给定行的这两个快照之间的增量集。这可以用于进行增量备份、执行跨集群同步或进行离线审计分析。
- 一个tablet内的多行原子更新:单个变动可能应用于tablet内的多行,并且它将在单个原子操作中可见。
为了提供MVCC的功能,每个变动都带有时间戳标记。时间戳是由TS范围内的Clock实例生成的,并由tablet的MvccManager确保在tablet内唯一。 MvccManager的状态确定一组时间戳,这些时间戳被视为“已提交”,因此对于新生成的扫描程序可见。创建后,扫描程序会获取MvccManager状态的快照,然后将该扫描程序看到的任何数据与MvccSnapshot进行比较,以确定哪些插入,更新和删除应视为可见。
每个tablet的时间戳单调递增。主要使用一种称为HybridTime的技术来创建时间戳,该时间戳既对应于真实的挂钟时间,又反映了节点之间的因果关系。
为了支持这些快照和时间旅行读取,必须在数据库中存储任何给定行的多个版本。为了防止空间的无限使用,用户可以配置一个保留期限,在该保留期限之前可以对旧的事务记录进行GC(用于防止从历史记录中早于该点的任何快照读取)(注意:历史记录GC当前未实现)。
2.2 MVCC在MEMRowSet中的变动
为了在MemRowSet中支持MVCC,每行都用插入该行的时间戳进行标记。此外,该行还包含一个单链表,其中包含该行插入后对该行进行的任何其他变动,每个变动都标记有该变动的时间戳。
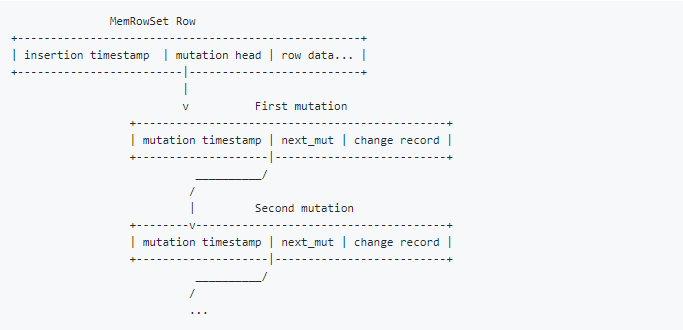
用传统的数据库术语,可以想到变动列表形成了一种“ REDO日志”,其中包含影响该行的所有更改。
任何遍历MemRowSet的读取器都需要通过以下逻辑应用这些变动来读取行的正确快照:
- 如果行插入时间戳尚未在扫描器的MVCC快照中提交,则跳过改行(在创建快照扫描器时尚未将该行插入);
- 否则就将数据复制到输出缓冲区中;
- 对于列表中的每个变动:
-
- 如果在扫描程序中的MVCC快照中提交了变动的时间戳,则将更改应用到行的内存备份中,否则跳过这个变动(创建快照时变动尚未发生);
- 如果该变动表示删除,则通过在扫描器的选择向量中将该行的位调零,并将改行标记为已删除。
前文提及的变动属于如下三种类型:
- 更新:更改一个或多个列的值;
- 删除:从数据库中删除行;
- reinsert:用一组新数据重新插入到该行(此操作仅发生在先前具有删除变动的MemRowSet行上)
示例:
| INSERT INTO t VALUES ("row", 1); | [timestamp 1] |
| UPDATE t SET val = 2 WHERE key = "row"; | [timestamp 2] |
| DELETE FROM t WHERE key = "row"; | [timestamp 3] |
| INSERT INTO t VALUES ("row", 3); | [timestamp 4] |

请注意,当更新频率较高时,这具有两个不良特性:
- 数据读取者必须通过单个链接列表追逐指针,这可能会导致许多CPU高速缓存未命中。
- 更新必须附加到单链表的末尾,即O(n),其中“ n”是该行已更新的次数。
但是,考虑到以下假设,我们认为上述低效率是可以容忍的:
Kudu的目标用例的更新率相对较低:我们假设单行的更新频率不高,MemRowSet中只有很小一部分的数据库位于MemRowSet中,一旦MemRowSet达到目标大小阈值,它将刷新。 因此,即使由于更新处理而导致扫描MemRowSet的速度很慢,它也只占整个查询时间的一小部分。
2.3 MemRowSet flush
当MemoryRowSet填满后,数据将被flush到数据磁盘上:
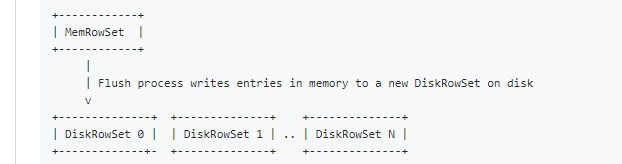
刷新数据后,会将其存储为一组CFile。数据中的每一行都可以通过连续的“行”来寻址,该行在该DiskRowSet中是密集的,不变的并且是唯一的。例如,如果给定的DiskRowSet包含5行,则将按升序将它们分配给rowid 0至4。在不同的DiskRowSet中,将存在具有相同rowid的不同行。
读取可以使用索引结构在主键(用户可见)和行标识符(内部)之间进行映射。在主键是简单键的情况下,键结构嵌入在主键列的CFile中。否则,单独的索引CFile将存储编码的复合键并提供类似的功能。
注意:行标识符不是显式存储在每一行中,而是基于文件中该行的序号索引的隐式标识符。源代码的某些部分将行标识符称为“行索引”或“普通索引”。
注意:其他系统(例如C-Store)将MemRowSet称为“写优化存储”(WOS),磁盘文件称为“读取优化存储”(ROS)。
2.4 DiskRowSets中的历史MVCC
为了继续为磁盘数据提供MVCC,每个磁盘RowSet不仅包括当前列数据,还包括“ UNDO”记录,这些记录提供了将行数据回滚到较早版本的能力。
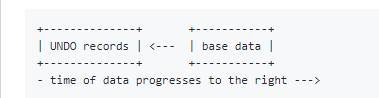
当用户希望在刷新后立即读取数据的最新版本时,仅需要基本数据。 因为基本数据是以列格式存储的,所以这种常见情况非常有效。 相反,如果用户希望运行时间顺序的查询,则读取路径将查阅UNDO记录,以便将可见数据回滚到更早的时间点。
当扫描仪遇到一行时,它将按以下方式处理MVCC信息:
- 读取行的基本图像
- 对于每个UNDO记录:-如果未提交关联的时间戳,请执行回滚更改。
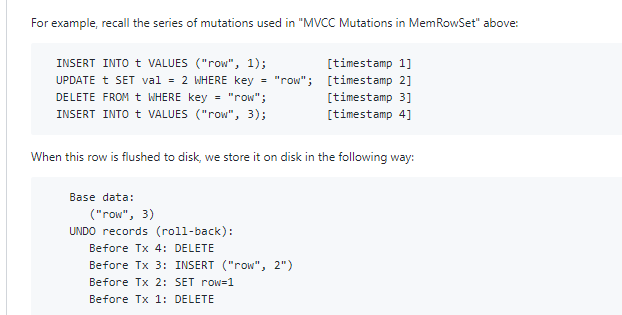
每个UNDO记录都是触发它的事务的逆过程-例如,当事务1的INSERT保存为UNDO记录时,它会变成“ DELETE”。
此处使用UNDO记录的作用是保留插入时间戳:MVCC快照指示Tx 1尚未提交的查询将执行DELETE“ UNDO”记录,从而使该行不可见。如:
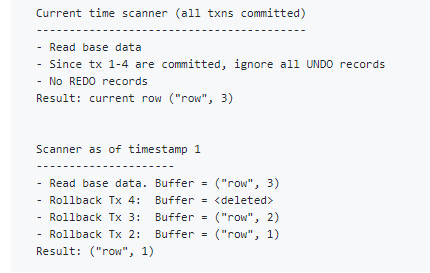
每个案例都处理正确的UNDO记录集,以得出所需时间点的行状态。
鉴于查询的最常见情况将针对“当前”数据运行。 在这种情况下,我们希望通过避免处理任何UNDO记录来优化查询执行。 为此,我们包含文件级元数据,该元数据指示存在UNDO记录的交易范围。 如果扫描程序的MVCC快照表明所有这些事务均已提交,则这组增量可能会短路,查询可以在没有MVCC开销的情况下进行。
2.5 处理文件磁盘上的变动
已经刷新到磁盘的行的更新或删除不会进入MemRowSet。而是在所有RowSet中结合元数据以及布隆过滤器搜索更新的键,以便找到保存此键的唯一RowSet。此过程首先使用间隔树来定位一组候选行集,其中可能包含所讨论的键。在此之后,我们为每个候选对象查询一个bloom过滤器。对于通过这两个检查的行集,我们寻找主键索引来确定行集中的rowid。
一旦确定了适当的RowSet,变动还将知道RowSet中的键的rowid(作为相同键搜索的结果,该键验证了键在RowSet中存在)。然后,该变动可以进入称为DeltaMemStore的内存结构。
DeltaMemStore是一个在内存中的并发BTree,由Rowid和突变时间戳的复合键作为键。在读取时,这些突变的处理方式与新插入的数据的突变相同。
当Delta MemStore变得太大时,它将刷新到磁盘上的DeltaFile,并将自身重置为空:

DeltaFiles包含与Delta MemStore相同类型的信息,但压缩为密集的磁盘序列化格式。因为这些增量文件包含需要重新应用到基本数据以使行更新的事务记录,所以它们被称为“ REDO”文件,而包含的变动称为“ REDO”记录。与驻留在MemRowSet中的数据类似,需要使用REDO变动来读取较新版本的数据。
给定的行可能具有多个增量结构中的增量信息。在这种情况下,增量将按顺序应用,以后的修改会胜过以前的修改。
请注意,给定行的变异跟踪结构不一定包含整个行。如果仅更新一行的单个列,则突变结构将仅包括更新的列。这样可以快速更新小列,而无需读取或重写大列(与C-Store和PostgreSQL等系统使用的MVCC技术相比,这是一个优势)。
2.6 Delta file处理摘要
总之,每一个DiskRowSet 都包含如下三个逻辑组件:

增量文件处理摘要
- 基本数据:刷新行集时行集的列数据
- UNDO记录:历史数据,需要处理这些历史数据才能将行回滚到RowSet刷新之前的时间点。
- REDO记录:需要处理的数据,以便在刷新RowSet之后对行进行更新。
UNDO记录和REDO记录以相同的文件格式(称为DeltaFile)存储。
2.7 Delta 压缩
在行集中,随着增量跟踪结构中累积的更多突变,读取的效率降低。特别是,在读取基础数据时,必须搜索并合并每个刷新的增量文件。此外,如果记录已多次更新,则必须应用许多REDO记录才能将最新版本显示给扫描仪。
为了减轻这种情况并提高读取性能,Kudu执行后台处理,该处理将RowSet从无效的物理布局转换为更有效的布局,同时保持相同的逻辑内容。这些类型的转换称为“增量压缩”。 Delta压缩具有几个主要目标:
- 减少增量文件的数量
已被RowSet刷新的增量文件越多,则必须读取越多的单独文件才能生成行的当前版本。在不适合RAM的工作负载中,每次随机读取都会导致对每个增量文件的磁盘搜索,从而导致性能下降。
- 将redo记录转换为undo记录
RowSet由基本数据(按列存储,由一组“undo”记录(以向后移)和一组“redo”记录(以从基础数据向后移)组成)。鉴于大多数查询将针对数据库的当前版本进行,因此我们希望最大程度地减少存储的REDO记录的数量。
在任何时候,一行的REDO记录都可以合并到基础数据中,并由包含单元格旧版本的一组等效的UNDO记录代替。
- GC旧的UNDO记录
UNDO记录仅需要保留到用户配置的历史保留期。在此期间之后,我们可以删除旧的“撤消”记录以节省磁盘空间。
注意:在BigTable设计中,时间戳与数据相关,而与更改无关。在Kudu设计中,时间戳与更改相关,而与数据无关。删除历史撤消日志之后,就没有关于插入或更新任何行或单元格的剩余记录。如果用户需要这个功能,他们应该保留自己的“inserted_on”时间戳列,就像在传统的RDBMS中一样。
2.8 Delta 压缩分类
主要分为两类:minor major
- Minor REDO delta 压缩
“少量”压缩是不包含基础数据的压缩。 在这种压缩中,生成的文件本身就是一个增量文件。

较小的REDO增量压缩仅用于减少增量文件的数量:因为它们不读取或重写基本数据,所以无法将REDO记录转换为UNDO。
- Major REDO delta 压缩
“主要” REDO压缩是一种包含基本数据以及任意数量的REDO增量文件的压缩。

大增量压缩可满足增量压缩目标1和2,但成本要比小增量压缩高,因为它们必须读取和重新写入通常大于增量数据的基本数据。
可以对DiskRowSet中列的任何子集执行主要的REDO增量压缩,如果仅单个列已收到大量更新,则可以执行仅读取和重写该列的压缩。 假定这是许多类似EDW的应用程序中的常见工作负载(例如,更新订单表中的orderstatus列或用户表中的visitcount列)。
请注意,两种类型的增量压缩都在RowSet中维护rowId:因此,它们可以完全在后台完成而无需锁定。 通过与压缩输入进行原子交换,可以将所得的压缩文件引入RowSet中。 交换完成后,预压缩文件可能会被删除。
2.9 压缩合并
随着将更多数据插入tablet,将会累积越来越多的DiskRowSet。 在以下情况下,这可能会损害性能:
a)随机访问(按主键获取或更新单行)
在这种情况下,必须分别查询其键范围包括探测键的每个行集来定位指定的键。Bloom过滤器可以减少物理搜索的数量,但是额外的Bloom过滤器访问会影响CPU,还会增加内存使用量。
b)指定范围扫描(如主键在A和b之间的扫描)
在这种情况下,无论bloom过滤器如何,必须单独查找具有重叠键范围的每个行集。专门的索引结构在这里可能会有所帮助,但是同样以内存为代价,等等。
c)排序的扫描
如果用户查询要求以主键排序的顺序生成扫描结果,则必须通过合并进程传递结果。合并成本与输入数量的关系通常是对数的:随着输入数量的增加,合并的成本也会增加。
鉴于以上,我们希望合并行集来减少行集的数量:

与上述Delta压缩不同,请注意,合并ID中不保留行ID。 这使得并发突变的处理有些复杂。
2.10 整个流程图
















 3355
3355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









