







目录
一、机器学习
1.1 机器学习特点
机器学习:机器学习是一门致力于研究如何通过计算的手段,利用经验来改善系统自身性能的学科。
主要内容:研究在计算机上 从数据中产生模型 的 学习算法。即从数据出发,提取数据的特征,抽象成数据模型,并应用到对新数据的分析预测中。

1.2 机器学习分类
| 类型 | 含义 |
| 任务类型 | |
| 回归 | 利用数理统计中的回归分析技术,确定变量间的依赖关系。进行如预测成熟度【0.95,0.37】等的连续值 |
| 分类 | 若希望预测的是离散值,如(猫,狗),(0,1,2)等,则被称作分类。 |
| 聚类 | 将样本集换分成若干“簇”,同簇中关系紧密 |
| 降维 | 将高位空间中的点映射到低维空间中,常用来去除噪声或减少特征向量。 |
| 学习方式【X,y中,若样本集含有结果信息,则成为有标记】 | |
| 有监督学习 | 训练数据有标记就是有监督学习,代表为回归和分类 |
| 无监督学习 | 训练集中无标记就是无监督学习,代表为聚类和降维 |
1.3 归纳学习
归纳和演绎是科学推理的两大基本手段
归纳:从特殊到一般的泛化过程,即从具体的事实归纳总结出一般性规律,机器学习属于归纳学习。
演绎:从一般到特化的过程,即从基础原理推演出具体情况,如基于一组公理推导出定理即演绎
归纳学习:广义上归纳学习大体相当于从样例中学习,狭义上则要求从训练数据中得到”概念“,因此也被称为概念学习,最基本的概念学习是布尔概念学习,就是通过学习判断 是否|0/1 (二分类)
1.3.1 假设空间
学习过程可以看做一个在所有假设组成的空间中进行搜索的过程,搜索目标是与训练集匹配的假设。假设的表示一旦确立,假设空间就确定了。在判断瓜的好坏中,假设空间由”(色泽=?)^(根蒂=?)^(敲声=?)“的所有取值形式组成。
版本空间:和训练集一致的假设集合就是版本空间,版本空间是假设空间的子集,包含所有的训练集。
1.3.2 归纳偏好
好瓜<->色泽=*^根蒂=蜷缩^敲声=浊响 和 好瓜<->色泽=*^根蒂=*^敲声=浊响 两种有学习的到的假设模型都能满足训练集的假设,但会对新样本产生不同的输出,但一个具体算法必须要产生一个模型,保证输出的一致性,如何进行选择,称为机器学习在学习过程中对某种类型偏好,即归纳偏好。
奥卡姆剃刀:奥卡姆剃刀是一种常用的,自然科学研究中的最基本原则,即“若有多个假设与观察一致,则选最简单的那个”
1.3.3 没有免费午餐定理 NFL
训练方法£a、£b在训练集外的所有样本上的误差【学习结果在训练集外样本产生错误结论的概率】可以表示为:
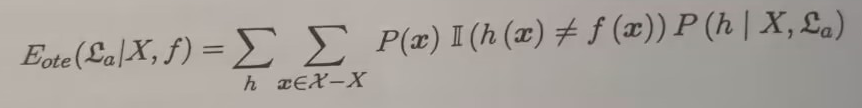
即该学习方法 产生错误结论的概率*P(x)
P(x)为产生自变量x的概率,
h(x)为产生的假设对x的判断,
P(h|X,/£a)表示该算法基于训练集X产生假设h的概率,,
χ表示假设空间,Χ表示样本空间
f(x)为真实情况下对自变量x的结果,
II(h(x)!=f(x))在相等时取1,不等时取0。
以二分类问题为例,对于真实的f(x)来说,f可能是任何x->{0,1}的映射,所以总误差可以表示为:

若对所有可能的f按均匀分布对误差求和,则可化简为:
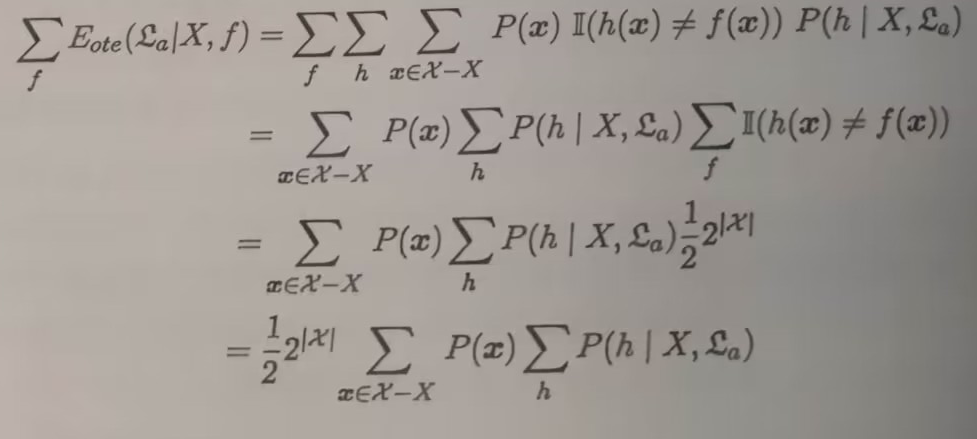
得出结论:总误差竟然与学习算法无关
NFL定理的前提:所有问题出现的机会相等,或所有问题同等重要【公式推导时假设所有f的概率均匀分布】,但实际情况斌不会如此。
NFL定理的意义:因为考虑到了所有!潜在问题,所以所有学习算法才一样好,但针对具体问题上,学习算法自身的归纳偏好和问题是否匹配,往往起到决定性作用。















 3747
3747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











