






 本文介绍了如何使用HTML5和JavaScript的WebSpeechAPI中的SpeechSynthesis接口来创建语音合成功能,包括文本输入、语音选择、速度控制以及错误处理等关键部分。
本文介绍了如何使用HTML5和JavaScript的WebSpeechAPI中的SpeechSynthesis接口来创建语音合成功能,包括文本输入、语音选择、速度控制以及错误处理等关键部分。
HTML5+JavaScript实现语音合成(文字转语音)
本文介绍用HTML5和JavaScript实现语音合成朗读(文字转语音)。
Web Speech API 有两个部分:SpeechSynthesis 语音合成(文本到语音 TTS)和 SpeechRecognition 语音识别(异步语音识别)。权威文档可见:
https://developer.mozilla.org/zh-CN/docs/Web/API/Web_Speech_API
在此我们关注语音合成。
语音合成通过 SpeechSynthesis 接口进行访问,它提供了文字到语音(TTS)的能力,这使得程序能够读出它们的文字内容(通常使用设备默认的语音合成器)。
https://developer.mozilla.org/zh-CN/docs/Web/API/SpeechSynthesis
使用HTML5实现语音朗读功能相对简单,主要用到的是Web Speech API。这是一个非常强大的API,允许网页合成语音(Text-to-Speech, TTS)。
下面给出比较完善的例子,先看效果图:
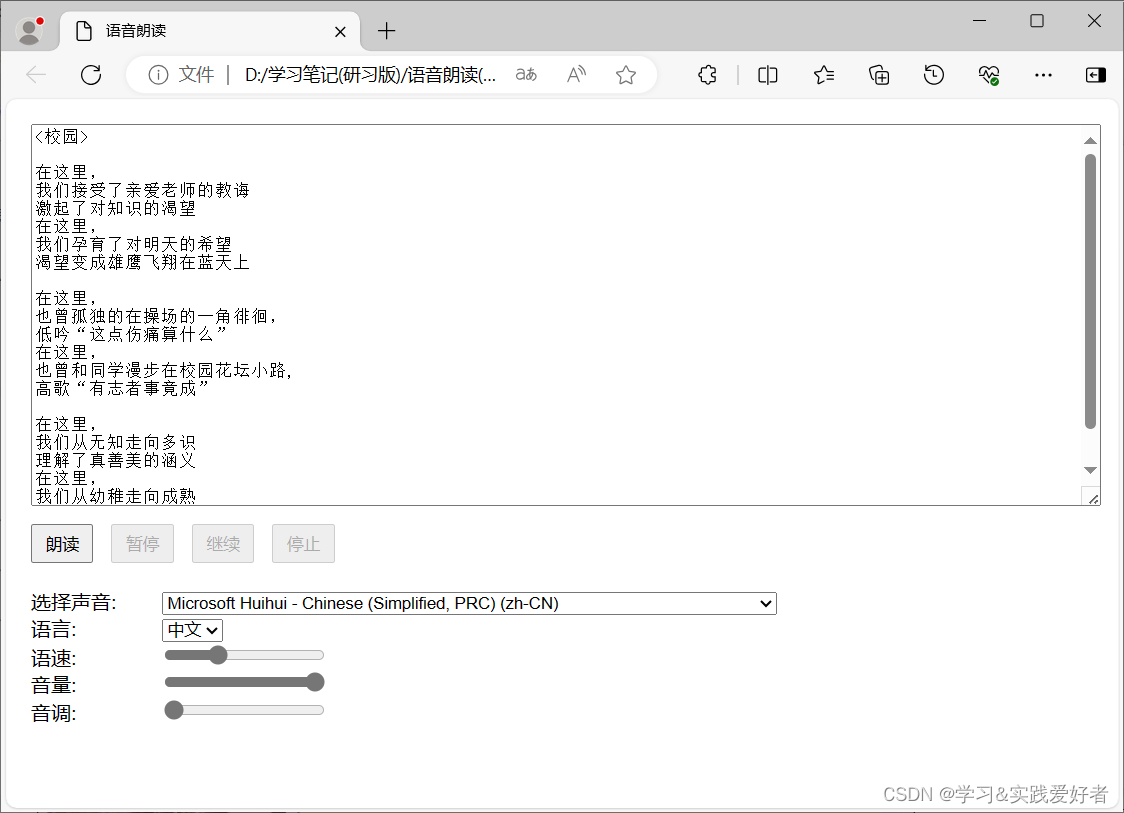
源码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>语音朗读</title>
<style>
body {
font-family: Arial, sans-serif;
margin: 20px;
}
#text-area {
width: 100%;
height: 300px;
}
#controls {
margin-top: 10px;
}
#controls button {
padding: 5px 10px;
margin-right: 10px;
}
#options {
margin-top: 20px;
}
#options label {
display: inline-block;
width: 100px;
}
</style>
</head>
<body>
<textarea id="text-area" placeholder="在这里输入文本..."></textarea>
<div id="controls">
<button id="speak-button">朗读</button>
<button id="pause-button" disabled>暂停</button>
<button id="resume-button" disabled>继续</button>
<button id="stop-button" disabled>停止</button>
</div>
<div id="options">
<label for="voice-select">选择声音:</label>
<select id="voice-select"></select>
<br>
<label for="lang">语言:</label>
<select id="lang">
<option value="zh-CN">中文</option>
<option value="en-US">英文</option>
</select>
<br>
<label for="rate">语速:</label>
<input type="range" id="rate" min="0.1" max="3" value="1" step="0.1">
<br>
<label for="volume">音量:</label>
<input type="range" id="volume" min="0" max="1" value="1" step="0.1">
<br>
<label for="pitch">音调:</label>
<input type="range" id="pitch" min="0" max="2" value="1" step="0.1">
</div>
<script>
const textArea = document.getElementById('text-area');
const speakButton = document.getElementById('speak-button');
const pauseButton = document.getElementById('pause-button');
const resumeButton = document.getElementById('resume-button');
const stopButton = document.getElementById('stop-button');
const voiceSelect = document.getElementById('voice-select');
const langSelect = document.getElementById('lang');
const rateRange = document.getElementById('rate');
const volumeRange = document.getElementById('volume');
const pitchRange = document.getElementById('pitch');
let voices = [];
function populateVoices() {
voices = speechSynthesis.getVoices();
voiceSelect.innerHTML = '';
voices.forEach(voice => {
const option = document.createElement('option');
option.textContent = voice.name + " (" + voice.lang + ")";
option.value = voice.name;
voiceSelect.appendChild(option);
});
}
if (speechSynthesis.onvoiceschanged !== undefined) {
speechSynthesis.onvoiceschanged = populateVoices;
}
const utterance = new SpeechSynthesisUtterance();
let isSpeaking = false;
let isPaused = false;
speakButton.addEventListener('click', function() {
if (isSpeaking) {
window.speechSynthesis.pause();
pauseButton.disabled = true;
updateButtons();
return;
}
window.speechSynthesis.cancel();
utterance.text = textArea.value;
utterance.voice = voices.find(voice => voice.name === voiceSelect.value);
utterance.lang = langSelect.value;
utterance.rate = rateRange.value;
utterance.volume = volumeRange.value;
utterance.pitch = pitchRange.value;
window.speechSynthesis.speak(utterance);
isSpeaking = true;
updateButtons();
});
pauseButton.addEventListener('click', function() {
if (!isSpeaking || isPaused) return;
window.speechSynthesis.pause();
isPaused = true;
updateButtons();
});
resumeButton.addEventListener('click', function() {
if (!isSpeaking || !isPaused) return;
window.speechSynthesis.resume();
isPaused = false;
updateButtons();
});
stopButton.addEventListener('click', function() {
if (!isSpeaking) return;
window.speechSynthesis.cancel();
isSpeaking = false;
isPaused = false;
updateButtons();
});
function updateButtons() {
speakButton.disabled = isSpeaking && !isPaused;
pauseButton.disabled = !isSpeaking || isPaused;
resumeButton.disabled = !isSpeaking || !isPaused;
stopButton.disabled = !isSpeaking;
}
// 当朗读结束时更新状态
utterance.onend = function() {
isSpeaking = false;
updateButtons();
};
// 当朗读出错时更新状态
utterance.onerror = function() {
isSpeaking = false;
updateButtons();
};
// 页面加载完成后立即尝试填充语音列表
populateVoices();
// 如果在页面加载时语音列表不可用,那么当它变得可用时填充语音列表
if (speechSynthesis.onvoiceschanged !== undefined) {
speechSynthesis.onvoiceschanged = populateVoices;
}
// 初始化时更新按钮状态
updateButtons();
</script>
</body>
</html>


















 1230
1230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











