







相关概念
分布式缓存
GeeCache特性
●单机缓存和基于 HTTP 的分布式缓存
●最近最少访问(Least Recently Used, LRU) 缓存策略
●使用 Go 锁机制防止缓存击穿
●使用一致性哈希选择节点,实现负载均衡
●使用 protobuf 优化节点间二进制通信
存储
key:string类型
value:字节类型
整体架构
●group:一个group就是一个缓存命名空间,是最重要的结构,得到请求先从maincache查,再调用pickpeer从远端查,最后调用回调获取

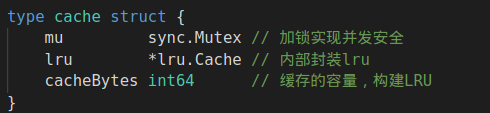
●cache:是并发安全的缓存,内部封装了LRU,实现add、get等方法,即加锁并调用LRU的add、get,不支持delete
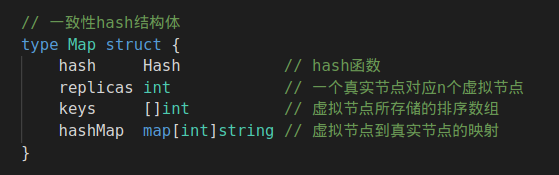
●map:一致性hash结构体,实现Add方法添加节点,实现Get方法根据key获得所在真实节点
●HTTPPool:
实现ServeHTTP监听请求,获得group和key的字符,得到group后调用group的Get(key)
实现Set:更新peers以及httpGetters,维护分布式节点
实现PickPeer:根据Key选择节点

1.LRU
概念
map和双向链表实现
代码
https://leetcode-cn.com/problems/lru-cache/
2.单机并发缓存
概念
通过加锁实现并发,如果缓存不存在,通过配置回调函数得到源数据
代码
3.HTTP服务端
概念
访问路径格式为 ///,通过groupname得到group实例,再使用group.Get(key)获取缓存,最终使用w.write()将缓存值作为body返回。
代码
4.一致性hash
概念
作用:用于实现分布式节点,解决分布式缓存中收到请求选择哪个节点的问题。
不直接用hash的原因:
hash可以让每次请求选择同样的节点,但是当节点数量变化时,hash(key) % 10 变成了 hash(key) % 9,意味着对应的节点全都发生了改变,几乎所有的缓存值都失效了。后面再获取数据都需要去数据源获取,容易引起缓存雪崩。
缓存雪崩
缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。常因为缓存服务器宕机,或缓存设置了相同的过期时间引起。
一致性hash原理:
一致性哈希算法将 key 映射到 2^32 的空间中,将这个数字首尾相连,形成一个环。
●计算节点/机器(通常使用节点的名称、编号和 IP 地址)的哈希值,放置在环上。
●计算 key 的哈希值,放置在环上,顺时针寻找到的第一个节点,就是应选取的节点/机器。

数据倾斜问题
节点映射全都挤在一块,容易造成缓存节点间负载不均。
引入虚拟节点解决,假设 1 个真实节点对应 3 个虚拟节点,那么 peer1 对应的虚拟节点是 peer1-1、 peer1-2、 peer1-3,并维护真实节点与虚拟节点的映射关系,其余节点也以相同的方式操作。
第一步,计算虚拟节点的 Hash 值,放置在环上。
第二步,计算 key 的 Hash 值,在环上顺时针寻找到应选取的虚拟节点,例如是 peer2-1,那么就对应真实节点 peer2。
代码
●hash算法:使用crc32
●实现hash环:使用数组实现,存储hash值
●添加节点:
对每个真实节点添加n个编号,计算hash值,添加到hash环数组中,并维护虚拟节点到真实节点的映射。添加完后将数组排序。
●选择节点:
计算key的hash值,顺时针找到第一个匹配的虚拟节点的下标,通过map找到真实节点。
●删除节点:
从数组中删除掉虚拟节点,并删除映射关系。
5.分布式节点
流程
●一个api服务(选取一个节点开启api服务),n个节点(用户感知不到),通过…/api?key=Tom访问api
●调用group.get:如果api服务所在的节点的maincache无数据,就调用一致性hash算法找到所在的远程节点
●将要查询的group与key发送给远程节点,远程节点调用group的get(先查maincache,如果maincache没有,pickpeer必定返回错误,因为是本节点,所以用回调函数获取数据,并存入远程节点的maincache)
●如果有数据就获得数据,无数据就调用回调(整个group统一),并存储在节点的maincache


6.防止缓存击穿
概念
缓存雪崩:缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。缓存雪崩通常因为缓存服务器宕机、缓存的 key 设置了相同的过期时间等引起。
缓存击穿:一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到 DB ,造成瞬时DB请求量大、压力骤增。
缓存穿透:查询一个不存在的数据,因为不存在则不会写到缓存中,所以每次都会去请求 DB,如果瞬间流量过大,穿透到 DB,导致宕机。
做法
建立key与请求的map,表示key有个正在处理的请求
●第一次请求时,上锁,将key与请求加入map,获得结果后再解锁,从map删除映射。
●并发的请求(非第一次)会查询到map中已有请求,调用wg.wait()等待解锁,等待解锁后,将请求的值返回。
func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
if c, ok := g.m[key]; ok {
g.mu.Unlock()
c.wg.Wait() // 如果请求正在进行中,则等待
return c.val, c.err // 请求结束,返回结果
}
c := new(call)
c.wg.Add(1) // 发起请求前加锁
g.m[key] = c // 添加到 g.m,表明 key 已经有对应的请求在处理
g.mu.Unlock()
c.val, c.err = fn() // 调用 fn,发起请求
c.wg.Done() // 请求结束
g.mu.Lock()
delete(g.m, key)
g.mu.Unlock()
return c.val, c.err
}
7.使用protobuf通信
原因
1.效率高:编码解码,可以显著降低二进制传输的大小
2.扩展方便:适合传输结构化数据,便于通信字段的扩展
proto
syntax = "proto3";
package geecachepb;
message Request {
string group = 1;
string key = 2;
}
message Response {
bytes value = 1;
}
service GroupCache {
rpc Get(Request) returns (Response);
}















 519
519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









