









Spire.PDF 是一个专业的PDF组件,能够独立地创建、编写、编辑、操作和阅读PDF文件,支持 .NET、WPF和Silverlight三个版本,本文介绍了如何通过Spire.PDF使用C#从PDF中的特定矩形区域中提取文本。
使用Spire.PDF,程序员可以从PDF文档中的特定矩形区域提取文本,本文演示如何使用Spire.PDF和C#实现此功能。
示例文件:
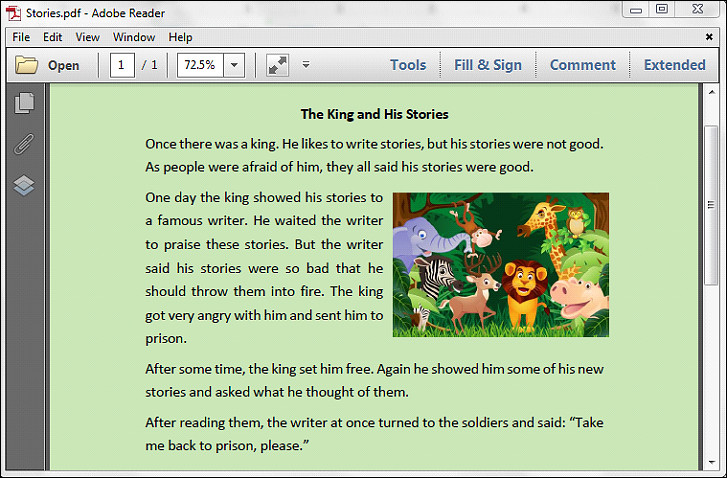
详细步骤:
Step 1: 初始化PdfDocument类的对象并加载PDF文件。
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("Stories.pdf");Step 2: 获取第一页。
PdfPageBase page = pdf.Pages[0];
Step 3: 从页面中的特定矩形区域中提取文本,之后将文本保存为.txt文件。
string text = page.ExtractText(new RectangleF(50, 50, 500, 100) );
StringBuilder sb = new StringBuilder();
sb.AppendLine(text);
File.WriteAllText("Extract.txt", sb.ToString());输出:
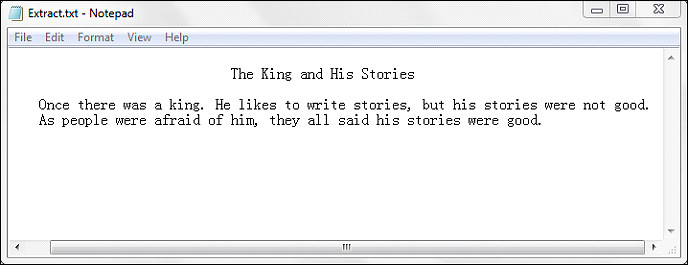
完整代码:
//Initialize an object of PdfDocument class
PdfDocument pdf = new PdfDocument();
//Load the PDF file
pdf.LoadFromFile("Stories.pdf");
//Get the first page
PdfPageBase page = pdf.Pages[0];
// Extract text from a specific rectangular area within the page
string text = page.ExtractText(new RectangleF(50, 50, 500, 100) );
//Save the text to a .txt file
StringBuilder sb = new StringBuilder();
sb.AppendLine(text);
File.WriteAllText("Extract.txt", sb.ToString());














 3136
3136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









