







《Data Caching Optimization in the Edge Computing Environment》论文阅读笔记
Common Sense
数据缓存是边缘计算中一项关键技术。由于网络中接入的移动用户数越来越多,用户对服务质量的要求也越来越高(如低延时、高准确性等),需要频繁从云中心获取请求的数据,在此过程中,由于内容的获取效率低下(重复数据多次获取等情况)、获取时延增加等问题,需要在移动边缘网络中对数据进行缓存,从而降低时延,提高服务质量。
传统的缓存替换策略如最近最少使用(LRU)和最近最少访问频次(LFU), 已经被大量的研究工作采用。对于相同规模的内容, 这两种策略简单而且高效。但是, 它们会忽略内容的下载时延以及内容的数据量。为此, 研究者们提出了一些新的缓存方案, 如基于用户偏好、增强学习或多节点合作的缓存策略。

数据的流行度(data popularity)在边缘计算的数据缓存问题中是一项重要的因素。
Question
关于数据缓存的现有研究,大多从减少网络时延和提高移动设备的能量利用效率的方面进行考虑,这是以移动用户的视角来看待问题的。而本文则以服务提供商的角度切入,研究如何在数据接入时延约束下,最大化服务提供商的收益(revenue)。
Analysis

上图为一个边缘网络,包含5个边缘服务器,边缘服务器接收到来自覆盖范围内的用户的数据请求,d1或者d2。针对这些请求,边缘服务器如何进行数据缓存才能使得收益最大化呢?
首先考虑对于5个边缘服务器,全部缓存d1和d2一定能够满足用户的请求,但是这增加了缓存的代价,对于服务提供商来说并不划算。合理的缓存方式为,S2缓存数据d1,S5缓存数据d2。
从服务提供商的角度,目标为满足用户数据接入时延的同时,最大化缓存数据带来的收益。
数据缓存收益(data caching revenue)有两部分组成:一是缓存数据后用户请求带来的利润,二是存储数据和传输数据的代价。需要在两者进行trade-off。
Contributions
- 在考虑数据流行度的基础上,基于获益和代价建模服务提供商的收益。
- 扩展Page-Hinckley-Test方法用户检测数据流行度。
- 将数据缓存问题建模成整数规划问题,证明其为NP-complete。
- 提出一种近似算法来解决大规模场景下的数据缓存问题,并证明了算法的近似比。
- 在一个真实世界构造的数据集上进行扩展实验,与两种baseline方法进行比较。
Related work
| 作者 | 方法 | 目标or特点 |
| Drolia et.al | 提出了缓存模型系统Cachier | 通过平衡云边负载最小化时延 |
| E. Zeydan et al | 用大量的数据进行内容流行度估计,存储流行度高的数据 | 实现用户的高满意度 |
| Halalai et al | 基于动态规划提出了缓存模型系统Agar | 考虑数据流行度 |
| Xuanyu et al | 从服务提供商角度提出一种优化竞争机制 | 保证缓存空间上的内容分配和用户的支付 |
| Xi et al | 提出联合缓存机制,未考虑数据流行度 | 最大化缓存命中率 |
| Gharaibeh et al | 提出在线缓存算法 | 未考虑数据流行度 |
| George et al. | 基于视频流行度分布设计了挑选视频缓存的准则 | 确定视频流行度时考虑用户偏好 |
Edge data caching architecture

如图所示,边缘数据缓存架构分为三层:
- 服务提供层:该层为服务提供商在云上提供的不同种类数据。
- 边缘服务器层: 该层边缘服务器部署在基站上面,用户缓存一些流行数据。
- 用户层:该层移动用户能够从附近的边缘服务器中获取流行数据。
Edge data caching approach
边缘服务器定义为S={s1,s2, … , sk, … , sK} ,s0为云服务器。数据定义为D={d1, d2, … ,dj, … ,dM},数据大小为SZ={sz1, sz2, …}。请求数据的移动用户数量定义为U={u1,u2, …, ui, …, uI}。由于数据存储价格的锐减,实验假设每个边缘服务器的缓存空间是无限的。
fk,j代表数据dj缓存到边缘服务器sk上的单元存储花费
hji,k代表用户ui从边缘服务器sk上获取数据dj时的单元传输花费或者用户直接从云上获取数据的单元传输花费
pk,j代表数据dj在sk覆盖范围内的流行度,threadshold代表特定于域的阈值,超过阈值则表明该数据能够缓存在对应边缘服务器上。该阈值只能决定缓存哪个数,而不能决定怎么缓存数据,所以对于本文提出方法的有效性和效率没有影响。
Data caching benefit model
数据是否缓存到边缘服务器中取决于其数据流行度,而数据流行度依赖于特定时间段内移动用户对该数据的请求数量。如果一段时间内数据的请求量迅速上升,那么该数据的流行度就是高的。计算流行度的方法有很多,本文采用Page-Hinkley Test工具来评估数据流行度。
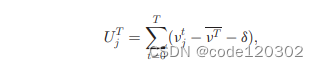
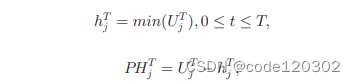
如果PHTj高于阈值,那么数据dj被认为是流行的,缓存到边缘服务器上。
定义缓存数据dj的利润:
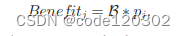
An optimal approach
本文将问题建模为一个IP问题,并证明了它是NP完备的。
covi,k定义了用户ui是否被sk覆盖

zji,k定义了是否用户ui从sk上获取到dj

yk,j为数据缓存策略,定义了是否数据dj缓存在sk上
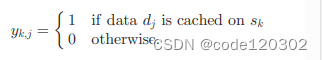
pi,j定义了数据dj在覆盖用户ui的边缘服务器上的流行度
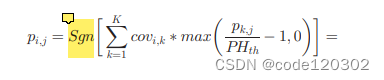
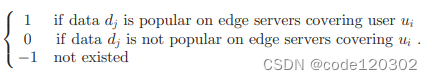
其中,对于Sgn(number)函数,如果 number 大于0,则Sgn 返回1;等于0,返回0;小于0,则返回-1。
revenue = caching benifit - (storage cost + transmission cost)
则将问题建模为:
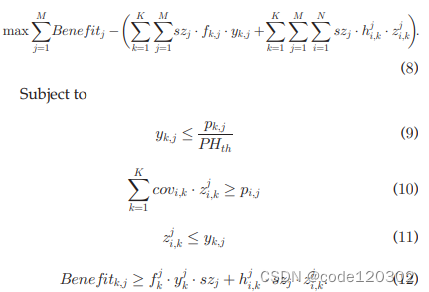
约束9保证了当数据dj在sk内流行时,dj有机会被缓存到sk上了人当数据dj在sk内不流行时,dj不会被缓存到sk上。
约束10保证了当数据dj在覆盖用户ui的边缘服务器上流行时,用户ui能够从覆盖ui的至少一个边缘服务器中获取到数据dj。
约束11保证了只有数据dj被缓存到sk上时,用户ui才能从sk上访问到dj。
约束12保证了将数据dj缓存到sk上的收益(revenue)都是正值。
可以采用Gurobi和IBM CPLEX Optimizer.对整数规划问题进行求解,其解为最优数据缓存策略。
Theorem 1 这是一个NP-complete问题。
Proof. 该问题可以归约成集合覆盖问题。U={(ui,di)…}U为用户的请求集,B={b1,b2,…}B为缓存决策,如b1={1,2,3}则表明数据d1被缓存在服务器s1,s2,s3上。w为将数据缓存到服务器上的revenue。该问题求解为如何选取B的子集B’,使得所有用户请求被覆盖的同时缓存产生的revenue最大。
根据解决集合覆盖问题的思路,采用贪心策略,每次选择revenue最大的缓存方式,直至所有用户数据请求被覆盖。由于集合覆盖问题为NP-complete问题,则本文建模的问题也是NP-complete的。
An approximation algorithm
基于以上的思路,本文提出一种近似优化算法。

calSingleBenefits函数计算数据dj缓存到服务器sk上的revenue。
V代表用户请求,即(ui, dj)表示用户i对数据dj有需求。
DS代表缓存需求,即(sk, dj)表示服务器sk覆盖范围内的用户对数据dj有需求。(注意这里的有需求指的是数据流行度较高)
W代表数据缓存到服务器上的revenue。
T代表用户请求数,即t表示服务器覆盖范围内用户对某一数据的请求数。
在所有缓存需求中,选择权重最大的一个缓存需求(sk, dj),设置y为1,表示可以将dj缓存在sk上;将权值设为-1,表示该需求已分配,更新C。(line 23 - 27)
对于跟sk具有交叉范围的服务器,若交叉范围内用户请求了数据dj,并且用户能够通过sk获取到数据dj,那么这些具有交叉范围的服务器在计算revenue时,需要在benefit中减少请求数,且减少了对应的传输时延(因为用户通过sk能够获取数据,不用通过这些服务器)。(line 28 - 35)
对于可缓存决策,选择其中存储花费最少的,作为用户访问数据的最合适边缘服务器。(line 36 - 39)
不断迭代,直到所有的用户请求全部考虑完毕。
Experimental Evaluation
Dataset
采用EUA数据集,采样自真实环境,包含移动用户和边缘服务器的地理位置信息。
Experiment Setup
| 边缘服务器的数据条数 | 60 |
| 移动用户的数据条数 | 2000 |
| 用户请求数据的总数量 | 不超过I*K(I为用户数量,K为服务器数量) |
| 用户请求的数据的种类 | 500 |
| 用户请求的数据的大小 | 范围[3, 20)MB |
| 计算benefit的B | 80 |
| 单位存储花费 | 范围[5, 20) |
| 单位传输花费 | 范围[1,2] |
为了模拟不同的场景,作者改变了边缘服务器数量和用户数量,实验进行100次取均值。
Baseline
- Random:随机选择边缘服务器进行数据的缓存直到满足接入时延的情况下所有可缓存数据都缓存完毕。
- User Coverage Oriented(UCO):每次贪心选择覆盖用户请求数最多的边缘服务器进行数据缓存直到所有可缓存数据缓存完毕。
- Caching Benefit Oriented(CBO):每次贪心选择benefit最高的缓存需求进行缓存直到所有可缓存数据缓存完毕。
- NSGA-II:基于遗传算法的一种算法
Performance Metrics
- 数据缓存收益(revenue):benefit - cost
- 数据缓存花费(cost):storage cost + transmission cost
- 每个缓存数据的平均收益(revenue per replica)
- 计算时间(computation time)
Expriment Settings
实验分为四组,通过改变边缘服务器数量和用户的数量,以查看不同场景中算法的性能优劣。

set1为小规模场景,set2为大规模场景。
Experiment Set#1

在set#1.1中,随着服务器数量的增加,数据缓存收益、数据缓存花费和计算时间都在增加,每个缓存数据的平均收益在降低。并且除了最优解之外,本实验的近似算法总体性能是最好的。

在set#1.2中,随着用户数量的增加,数据缓存收益、数据缓存花费、计算时间和每个缓存数据的平均收益都在增加。
Experiment Set#2

set2的实验结果与set1十分相似,设置set2的目的是为了体现算法的扩展性(聚焦计算时间)。从图中可以看到,在大规模场景中,近似算法依然能够取得很好的效果。
Threats to validity
- Threats to Construct Validity
Q:从服务提供商角度最大化revenue这一思路没有直接的比较方法?
A:选用四个具有代表性的算法进行比较,通过改变实验设置参数(服务器数量和用户数量)检验方法的有效性。 - Threats to External Validity
Q:模拟参数的设置是否合理(单位缓存花费,单位传输花费,数据大小等)?
A:
- 采用合成的数据,所有数据符合均匀分布。使用RpR指标计算每个数据的平均收益,能够降低参数的影响使评估更加全面。
- 实验结果为运行100轮的平均结果,能够代表一种更为普遍的结果。
- 用户请求随机生成,假定用户有一定的数据偏好,使用PHT测试流行度时更符合现实场景。
- Threats to Internal Validity
Q:如何说明实验的全面性?
A:通过改变实验设置参数(服务器数量和用户数量)说明方法的可扩展性。
Conclusion
本文使用PHT方法测试数据流行度,将数据缓存问题建模为IP问题,并且通过将其归约至集合覆盖问题证明了其NP-complete,提出求解模型的近似算法,通过改变实验参数模拟了不同场景,对算法的性能进行了对比。
未来方向:
- 以去中心化方式解决大规模场景中的边缘数据缓存问题(game-theoretic思路)
- 边缘服务器的协同合作
——————————————————————————
参考文献:
【1】张开元, 桂小林, 任德旺, 李敬, 吴杰, 任东胜. 移动边缘网络中计算迁移与内容缓存研究综述[J]. 软件学报, 2019, 30(8): 2491-2516.(中文A)
【2】Y. Liu, Q. He, D. Zheng, M. Zhang, F. Chen and B. Zhang, “Data Caching Optimization in the Edge Computing Environment,” 2019 IEEE International Conference on Web Services (ICWS), Milan, Italy, 2019, pp. 99-106, doi: 10.1109/ICWS.2019.00027.(CCF-B)
【3】Y. Liu, Q. He, D. Zheng, X. Xia, F. Chen and B. Zhang, “Data Caching Optimization in the Edge Computing Environment,” in IEEE Transactions on Services Computing, vol. 15, no. 4, pp. 2074-2085, 1 July-Aug. 2022, doi: 10.1109/TSC.2020.3032724.(CCF-A)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









