







多智能体解决数据缓存
contributions
- 将联合缓存问题建模成MDP问题,提出基于多智能体深度强化学习的联合数据缓存框架
- 基于经验回放机制(experience replay mechanism)使用n步学习算法提高DRL算法的有效性
- 在真实世界数据集上扩展实验,评估三种经典算法
经验回放(Experience Replay)是强化学习中的一个技术,旨在改善学习的效率和稳定性。在实时与环境交互中获得的经验(状态、动作、奖励等)通常会被立即用于更新模型。这种做法可能非常低效和不稳定。经验回放通过存储这些经验到一个称为“经验回放缓冲区”的数据结构中,然后在训练过程中随机抽样以用于模型更新,从而解决了这一问题。
experience
实验设置
固定边缘节点之间、边缘节点和数据中心之间的数据率。
对比算法
1.Myopic
2.MAMAB
3.Greedy
数据集
真实世界数据集MovieLens
实验参数
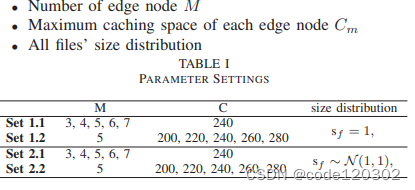
衡量指标

参考资料:
【1】https://zhuanlan.zhihu.com/p/658660090
【2】Y. Yu, S. Wu, S. Shao, J. Chen and X. Chen, “A Multi-Agent Deep Reinforcement Learning based Cooperative Edge Data Caching Approach,” 2023 24st Asia-Pacific Network Operations and Management Symposium (APNOMS), Sejong, Korea, Republic of, 2023, pp. 294-297.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









