







一个线上实例,用户数据大概300g 400g的样子,由于用户自己修改了最大连接数,超过了我们设置的合理范围,导致自动恢复失败,现在需要我们手动搭建起来新的主从关系。
但是在搭建的过程中,出现了两个比较麻烦的问题。
第一个问题:主节点不能正确恢复数据
我们把pgbackrest.conf配置文件中的oss路径改成源pg实例的路径,通过pgbackrest restore进行按时间点恢复。这种恢复方法需要先找到距离本次恢复时间点最近的一次全量备份,然后再把之后到该时间点(包括该时间点)的所有wal日志下载到本地,然后启动pg服务就可以了。
然而由于数据量比较大,恢复需要一定时间,在恢复的过程中,源实例做了一次自动全量备份(每天晚上自动备份),导致连续的wal日志出现了如下图所示的.backup的备份文件。
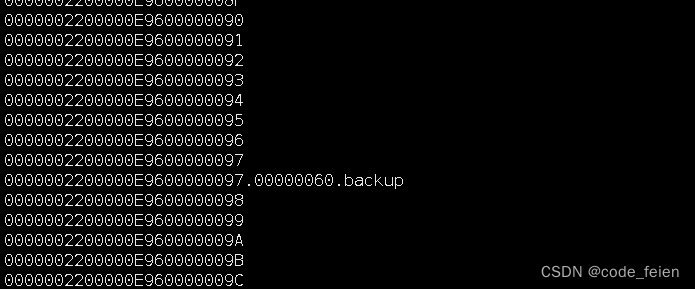
按照我的理解,这个.backup文件应该没有什么影响,但是本次全量备份做了大概有40分钟。目标实例在下载wal日志的时候中断在此了。。。
具体原因也不知道为什么,准备在其他的非生产实例上测试一下这个.backup文件是否会影响wal日志的下载。
这个问题相对好解决,我们通过pg_waldump定位到了需要的wal日志范围,pgbackrest archive-get命令把需要的wal日志都下载到本地,然后启动pg服务就可以了。
第二个问题:主从不能正常搭建
我们使用的主从搭建的工具是repmgr,这个工具大家应该都比较熟悉,一般就是用repmgr或者patroni来进行pg主从的搭建。先注册主节点,然后从节点clone,再register就可以了,按理说没什么难度。但是从节点注册之后,就比主节点多了一条timeline。

对了,刚开始的时候还注册不成功,我在从节点的data目录下手动创建了standby.signal,重启pg服务之后可以注册了。但是主从关系还是不对。
查了很多资料,卡了2天,但是没有解决。。。
直接说最后的解决方法吧。我把主节点的pgbackrest配置文件中的oss修改成当前实例,重建了stanza,修改了archive-command,然后又执行了一遍clone和register就成功了0.0.
感觉是和这个archive-command有关系,之前由于恢复把这个命令改成了/bin/true,忘记改回来了。后面改成pgbackrest archive-push,就成功了。其他的修改感觉用处不大。。















 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









