







题目:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
- 作者 : Peter Anderson , Xiaodong He , Chris Buehler , Damien Tency
- 论文地址[https://arxiv.org/abs/1707.07998]
1.解决的问题
- Image Captioning 和 VQA
2.方法
- Top-down atttention 和 Bottom-up attention 结合起来,作者说 bottom-up attention 就是将图片的一些重要得区域提取出来,每一个区域都有一个特征向量,Top-down attention 就是确定特征对文本得贡献度。
对于一个图片 I I ,提取出 个图片特征 V=v1,v2,...,vk,viϵRD V = v 1 , v 2 , . . . , v k , v i ϵ R D , 每一个特征代表图片得一个显著区域的编码, V V 就可以看成是 bottom-up attention model 的输出,然后将这些用于top-down attention model,提取出对描述贡献大的显著性区域的特征。
3. Bottom-Up Attention Model
- 使用 Faster R-CNN 来提取图片中的兴趣点,然后对感兴趣的区域采用 ResNet-101 来提取特征,使用 IoU 阈值来对所有区域进行一个筛选(“hard” attention)。对于每一个区域 ,
vi
v
i
定义为每个区域的 mean-pooled convolutional 特征(2048维)。使用这种方法从很多候选配置中选出一小部分候选框。
- 预训练Bpttom-Up Attention Model , 首先初始化Faster-RCNN 和 ResNet-101并在ImageNet上进行预训练,然后在Genome data 上进行训练。为了增强学习特征表达的能力,作者增加了一个预测物体属性类别的任务,为了预测区域 i i 的属性, 作者将 与一个代表着物体真实类别的 embedding 连接,并将其喂给一个新增的输出层输出一个在属性类别和非属性类别上的softmax(???)。
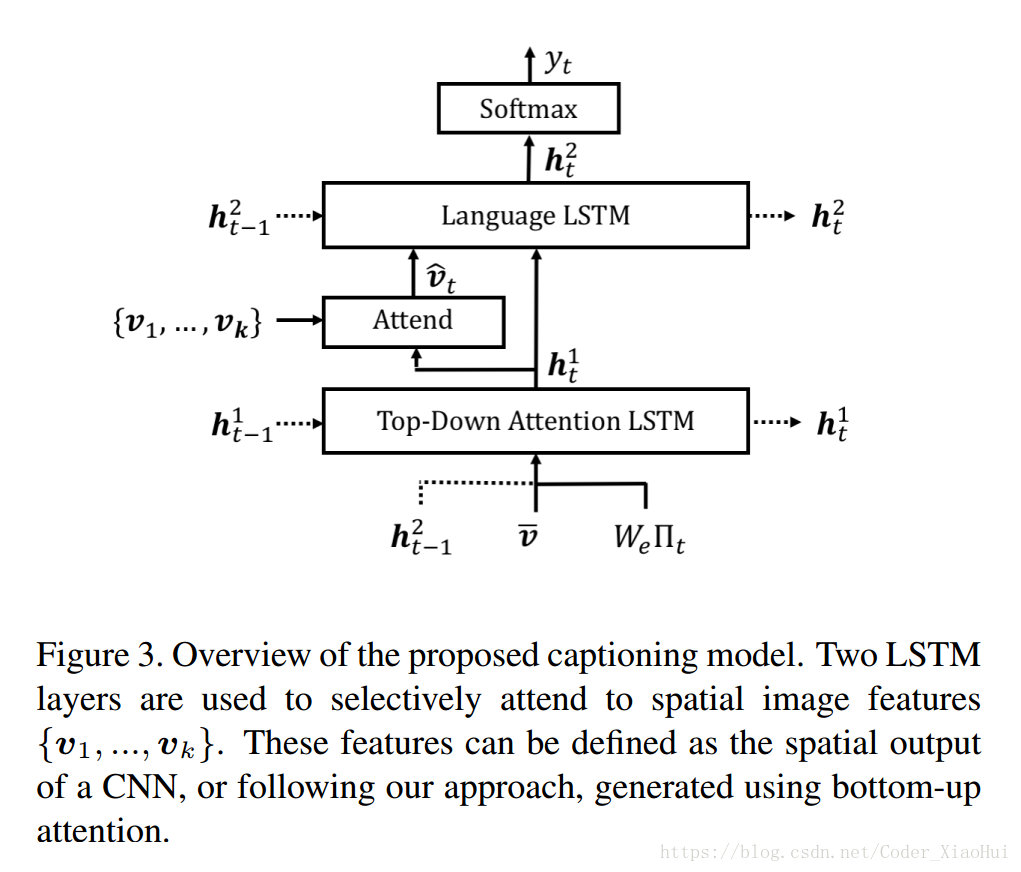
4.Captioning Model
- 主要有两个LSTM,第一个是Attention LSTM, 第二个是Language LSTM。
4.1. Top-Down Attention LSTM
首先,Attention LSTM 在每个时间步上的输入为:上一个时间步的 Language LSTM的 输出 + v¯=1k∑ivi v ¯ = 1 k ∑ i v i + 上一时刻生成的encoding of word。
x1i=[h2t−1,v¯,Wc∏t] x i 1 = [ h t − 1 2 , v ¯ , W c ∏ t ] Wc W c 是一个word embedding matrix, ∏t ∏ t 是一个单词的one-hot编码,这个输入提供给了Attention LSTM截至当前时间步的最大上下文信息,还有整个图片的内容,以及当前生成的单词内容, Wc W c 是随机生成的,没有经过预训练。
在每个时间步:Attention LSTM 都会输出一个output h1t h t 1 ,并且都会为 k k 个image feature 生成一个标准化的 attention权重 αi,t α i , t :
ai,t=wTatanh(Wvavi+Whah1t) a i , t = w a T t a n h ( W v a v i + W h a h t 1 )
αt=softmax(at) α t = s o f t m a x ( a t )Wva,Wha,wa W v a , W h a , w a 是学习的参数,并且 Attention的结果:
vˆi=∑i=1Kai,tvi v ^ i = ∑ i = 1 K a i , t v i
4.2. Language LSTM
- Language LSTM的输入为: x2t=[vˆt,h1t] x t 2 = [ v ^ t , h t 1 ] ,即是Attention LSTM的隐含层输出和Attention的结果,然后输出的 h2t h t 2 经过softmax 层输出单词的概率,整个句子的概率可以看成是所有单词概率的连乘。
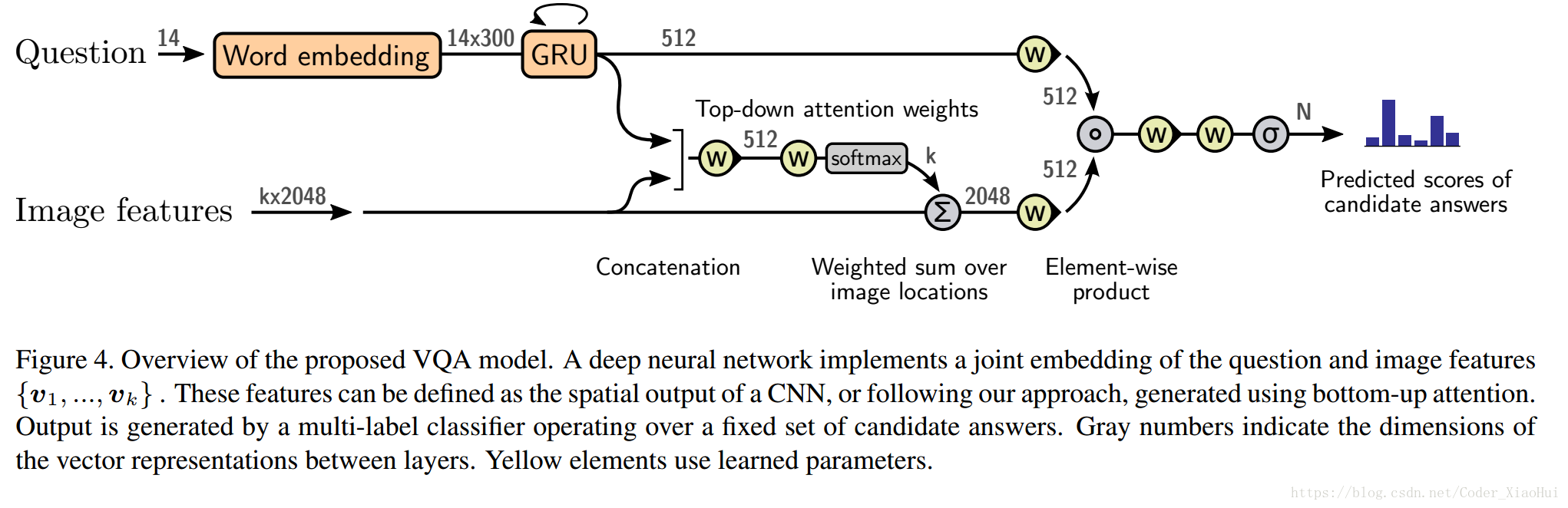
5. VQA Model
- 作者没有说太多细节,看另一个论文:D. Teney, P. Anderson, X. He, and A. van den Hengel. Tips and tricks for visual question answering: Learnings from the 2017 challenge. In CVPR, 2018.
6. Result
使用了 Visual Genome 数据集对我们的bottom -up 模型进行预训练。这个数据集共有108K的图片并且有物体属性和关系,并且有 1.7M 的问题和答案。预训练bottom-up attention model 只使用了物体和属性的数据,保留了5K作为验证,5K作为测试,剩下的98K作为训练。这个数据集中接近51K的图片都可以在MSCOCO里面找到,作者也小心的避免了数据交叉的问题(比如有一张图在Visual Genome训练集中,一张在MSCOCO的测试集中)。这个数据集中有2000个object classes 和 500 个 attribute classes, 作者手动的移除了一些detection 效果不好的物体和属性,剩下1600个object classes 和 400 个 attribute classes。当训练VQA Model 时,用Visual Genome数据集扩增了(VQA 2.0)数据集。
MSCOCO 数据集
VQA 2.0 数据集,包含1.1M的问题和11.1M的答案(关于MSCOCO的)
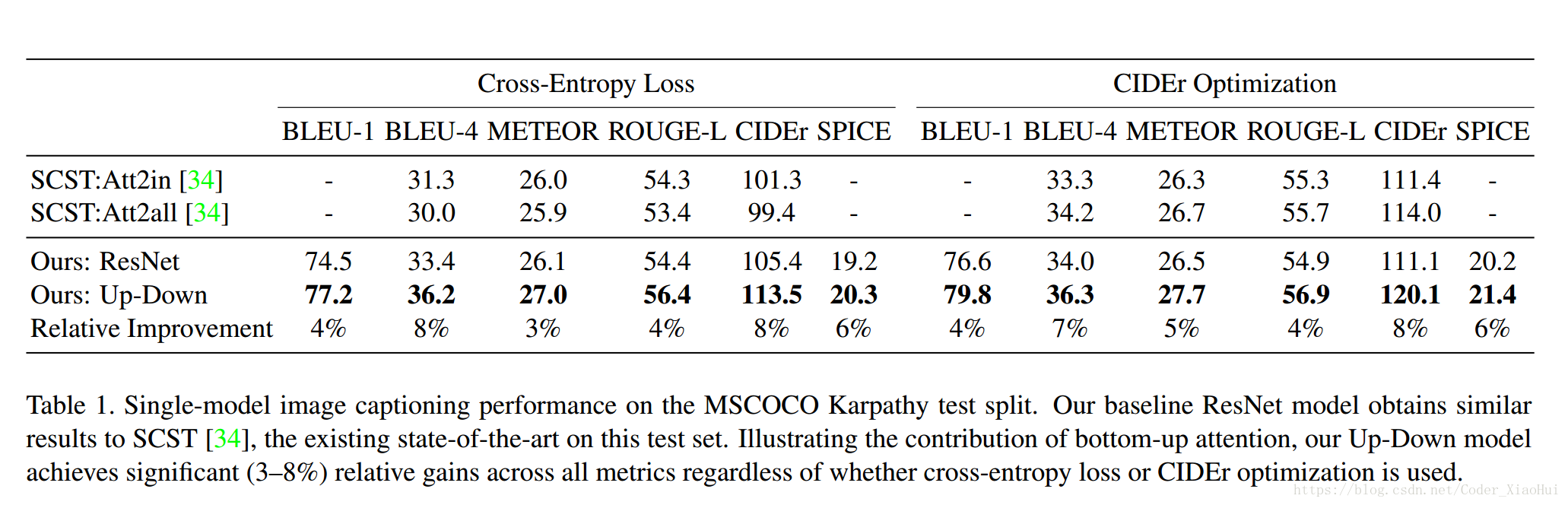
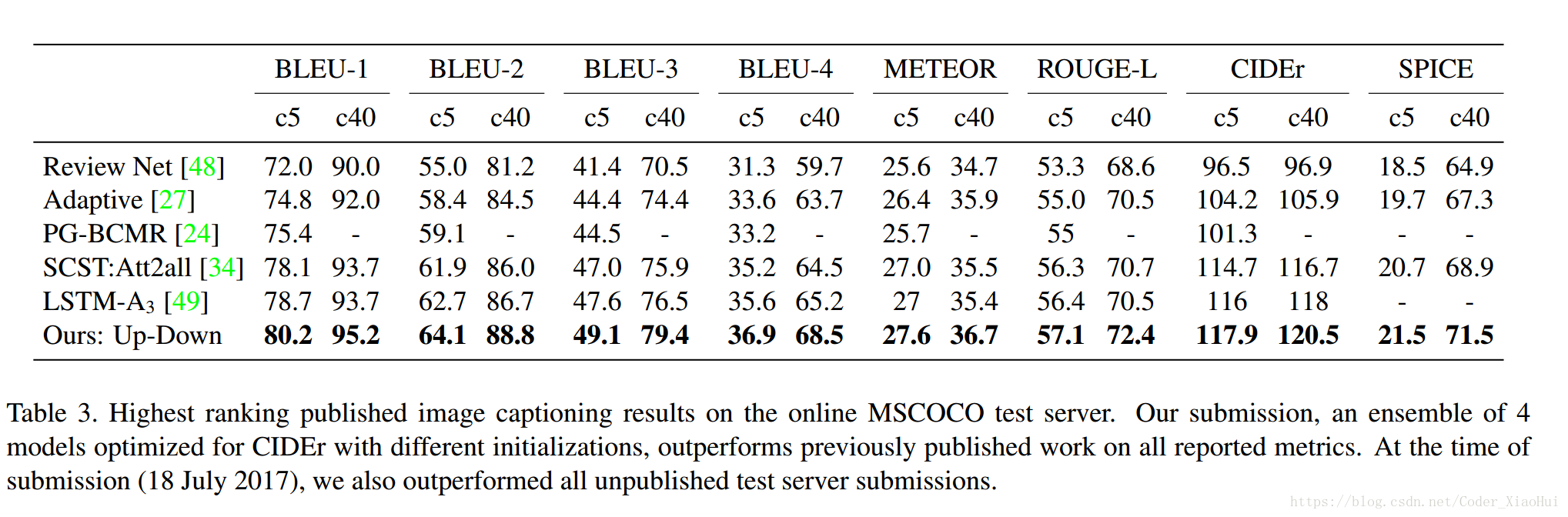
Image Captioning 结果:
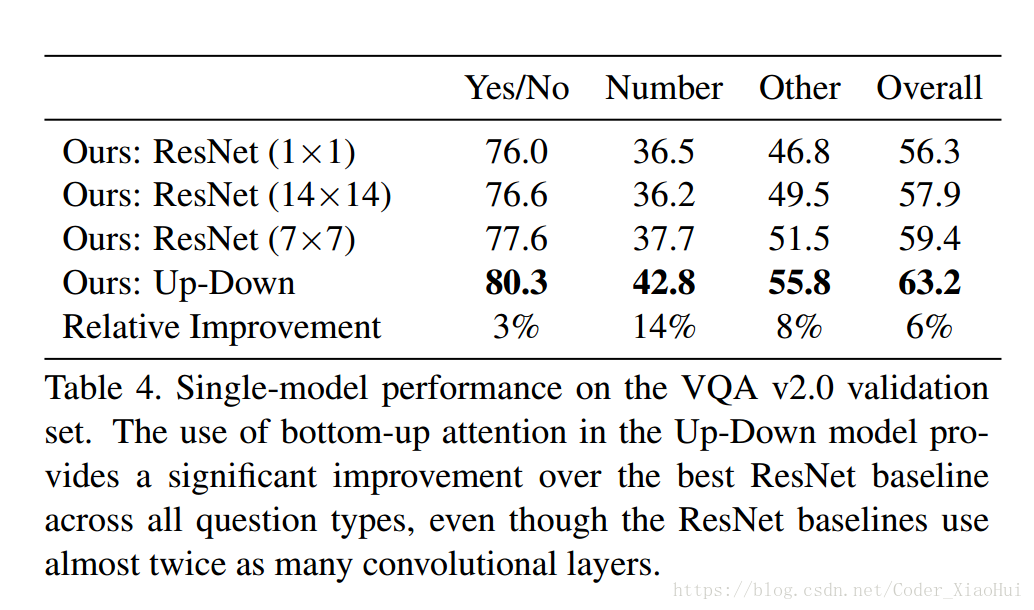
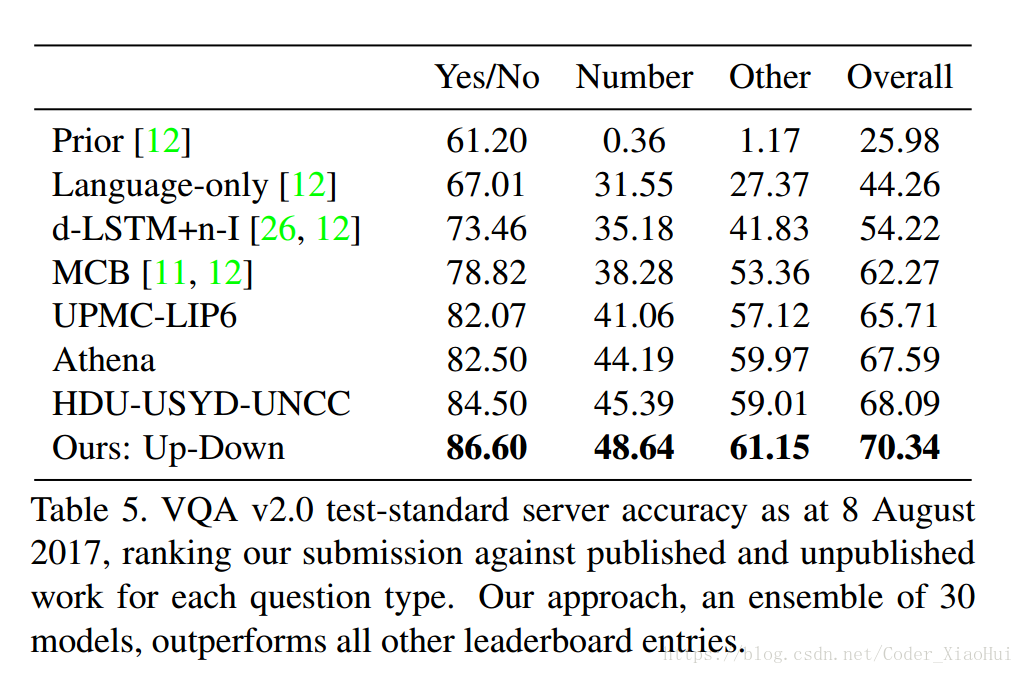
- VQA 结果:














 252
252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









