







1DW层整体设计
建模思想:
DWD:放明细数据
DWS:数仓服务层;它的建模思想,就是为最终需求计算来提供支持服务,所以建模相对灵活
常见的建模套路有:
1.建大宽表(对应:维度建模思想中的维度退化)
2.轻度聚合
3.看具体需求(如,用户连续活跃区间记录表)
1.1技术选型概述
存储:HDFS
运算:HIVE/SPARK
1.2输入输出
数仓内部
| 输入 | dwd层事实表及dim层维度表 |
|---|---|
| 输出 | dws层聚合表 |
1.3主题模型举例
流量会话聚合天/月表
日新日活维度聚合表
事件会话聚合天/月表
访客连续活跃区间表
新用户留存维度聚合表
运营位维度聚合表
渠道拉新维度聚合表
访客分布维度聚合表
用户事件链聚合表(支撑转化分析,高级留存分析,)
2全局访客id表
需求:记录全局到目前为止出现过的所有guid,并且带一个自增的id
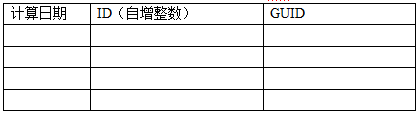
dwd.user_guid_global
计算的源表:
- 设备账号 关联评分表
设备,账号,评分,首访时间,最近时间
device01,account01,2000,t1,t8
device01,account02,1000,t2,t8
device02,account03,2000,t1,t8
device04,account04,2000,t1,t8
device05,\NULL ,\N, t1,t8
实现逻辑
用T日的设备关联表,来获取所有guid,去LEFT JOIN T-1日的全局id表,获得T日新增guid
然后插入全局id表的T日分区,并带上row_number +(T-1的id最大值)
3基础指标分析主题
3.1会话聚合表
页面浏览事件的:一次会话一行

表名: dws.tfc_app_agr_session
Hive的向量化执行引擎,对parquet的支持尚不完善,如果报向量化相关的错误,可关闭向量化执行: SET
hive.vectorized.execution.enabled=false
3.2支撑的ADS报表
可以支撑的报表分析举例:
- PV/UV[DAU]/DNU概况日报表,周报表,月报表
Pv日报表: 日期,pv总数
Uv日报表: 日期,uv总数
DNU日报表: 日期,nu总数
Pv周报表: 日期,周pv总数
Uv周报表: 日期,周uv总数
DNU周报表: 日期,周nu总数
-
访问次数分析

-
访问深度分析

-
访问时长分析

-
访问入口页分析

-
访问跳出页分析

-
回头访客数分析

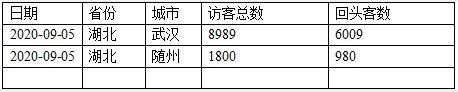

-
不同时段流量对比分析

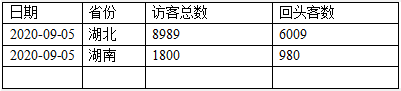
不同地域的流量情况
不同地域的访问次数情况
不同地域的新、老用户分布情况
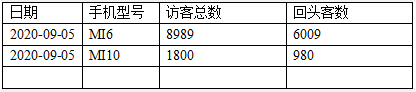
不同手机型号的活跃用户数
3.3补充:多维数据立方体cube
3.3.1概述
实际生产中,各种指标的报表统计,往往都会涉及到多维分析
,比如,统计日活数,日会话次数,日回头访客数,日新,日用户平均访问时长,访问深度……都可以从如下维度来进行分析:
时间段
省市区等地域维度
设备类型
操作系统
App版本
App下载安装渠道
……
而数据分析师,可能会提出各种各样的“维度组合”下的指标统计需求:
,比如:
省,日活总数
省,市,日活总数
手机型号,日活总数
省,手机型号,日活总数
……
如果上述维度分析需求,都逐个开发计算sql(逐个去group by聚合),工作繁冗!
那么,如何解决这个问题呢?
关键要点:
- 创建一个统一的目标维度分析聚合结果表,这个表应该包含所有的维度字段
- 利用hive的高阶聚合函数,在一个sql中,即可计算出所有可能的维度组合
3.3.2Cube表模型

这种表,在业内通常被称之为: cube (多维数据立方体)
- 一个小问题:如果我要从上面的表中,获取到 各省份日活数,如何获取?
SELECT
province,
dau_cnt
FROM cube
WHERE province is not null and coalesce(city,district,devicetype,osname,....) is null
;
- 另一个小概念:维度的基数
上述表的行数很大;
比如按**(省、市、区、手机型号、app版本、下载渠道、小时段)维度组合计算日活数,结果行数有: 省维度的基数 * 市维度的基数 * 区维度的基数 * ……
基数: 就是某个维度字段的去重值个数!
3.3.3高阶聚合函数
基础写法:
INSERT INTO TABLE cube
SELECT
province,
city,
district,
null as device_type,
null as os_name,
null as app_version,
null as release_channel,
null as hour_segement,
dount(distinct guid) as dau_cnt
FROM t_src
GROUP BY province,city,district
这种写法,要完成上面的数据立方体的完整计算,需要些2的8次方个sql
显然要命!
改用hive的高阶聚合函数,则一个sql搞定!别人加班,我陪女友
- With cube函数
INSERT INTO TABLE cube
SELECT
province,
city,
district,
device_type,
os_name,
app_version,
release_channel,
hour_segement,
count(distinct guid) as dau_cnt
FROM t_src
GROUP BY
province,
city,
district,
device_type,
os_name,
app_version,
release_channel,
house_segment
WITH CUBE
;
- Grouping sets函数
由用户自己决定需要哪些维度组合
INSERT INTO TABLE cube
SELECT
province,
city,
district,
device_type,
os_name,
app_version,
release_channel,
hour_segement,
count(distinct guid) as dau_cnt
FROM t_src
GROUP BY
province,
city,
district,
device_type,
os_name,
app_version,
release_channel,
house_segment
GROUPING SETS(
(),
(province),
(province,city),
(province,city,district),
(device_type),(province,device_type)
)
;
- with rollup函数
主要针对层级维度的组合处理
INSERT INTO TABLE cube
SELECT
province,
city,
district,
device_type,
os_name,
app_version,
release_channel,
hour_segement,
count(distinct guid) as dau_cnt
FROM t_src
GROUP BY province,city,district
WITH ROLLUP
;
3.4流量用户聚合表(日活表)
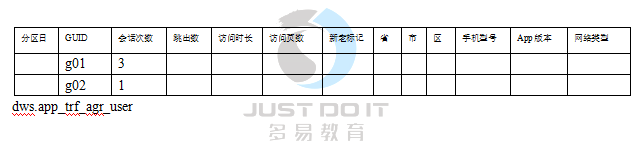
3.5流量基础指标多维报表
3.5.1需求
- 度量值
pv数
uv数
session数
访问时长
回头客数
跳出次数(只访问了一个页面就结束的会话)
跳出人数
- 维度
地域维度
时段维度
手机型号维度
操作系统维度
入口页面维度
跳出页面维度
新老属性维度
3.5.2模型设计
目标表模型:

3.6利用bitmap思想实现distinct的层级聚合
用户聚合表
"1,江苏省,南通市,下关区",
"1,江苏省,南通市,下关区",
"2,江苏省,南通市,下关区",
"2,江苏省,南通市,白领区",
"3,江苏省,南通市,白领区",
"3,江苏省,南通市,富豪区",
"1,江苏省,苏州市,园林区",
"1,江苏省,苏州市,园林区",
"4,江苏省,苏州市,虎跳区"
base cuboid
省, 市, 区, 人数(bitmap)
江苏省,南通市,下关区, [1,1,0,0]
江苏省,南通市,白领区, [0,1,1,0]
江苏省,南通市,富豪区, [0,0,1,0]
江苏省,苏州市,园林区, [1,0,0,0]
江苏省,苏州市,虎跳区, [0,0,0,1]
省, 市, 人数(bitmap)
江苏省,南通市, [1,1,1,0]
江苏省,苏州市, [1,0,0,1]
省, 人数(bitmap)
江苏省, [1,1,1,1]
逐级聚合(去重聚合计算)
在具体实现上,我们项目中采用了一个第三方的bitmap工具包:RoaringBitmap
然后为其开发了一系列的工具:
- array[Int] -> bitmap
- bitmap序列化
- bitmap反序列化
- bitmap的UDAF实现分组聚合or运算
- bitmap求基数的UDF
3.7可以支撑的报表分析举例
比如,各类用户分布分析
新老访客占比

访客app版本分布
访客地域分布
访客手机型号分布
4事件概况分布分析

首先做一个中间层的表(dws.event_overview_d),从DWD事件明细表中计算即可
日期,GUID,事件名称,发生次数
然后,查询分析师想看的报表:
日期,事件,发生总人数,发生总次数,1-10次的人数,10-20次的人数,20-30次的人数,30+人数
5事件多维分析
5.1交互事件主题
在dws层,我们的各种终端渠道的数据,就可以汇总到一起
| share | {"pageId":"528","productId":"960","title":"mzH Zlm djr","url":"tFA/XSB","shareMethod":"微博"} |
| share | {"pageId":"310","productId":"272","title":"KpB LEt TMI","url":"jro/RzJ","shareMethod":"微博"} |
| share | {"pageId":"388","productId":"885","title":"Hsq Pcx bCi","url":"FNK/AHX","shareMethod":"微博"} |
-
分享事件,主题明细表
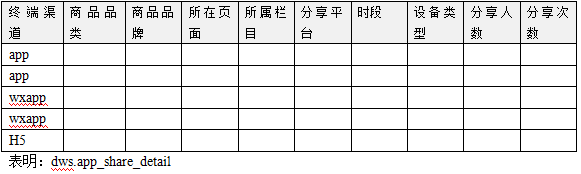
-
点赞事件,主题明细表

-
收藏事件,主题明细表

可以支撑的报表分析举例:
各栏目x事件发生次数
各栏目x事件发生人数
各item、各品类,各分享平台的发生次数
各item各分享平台发生人数
日点赞item排行榜(次数、人数)
日收藏item排行榜(次数、人数)
5.2广告运营位曝光点击分析主题
广告运营位:页面上放广告的位置;比如(首页中心轮播图,首页中心轮播图侧边栏……)
当你打开一个页面,划到页面上的某一屏,这一屏上的运营位上的埋点代码,就会发送运营位广告曝光事件,如果被点击,还会发送运营位广告点击事件
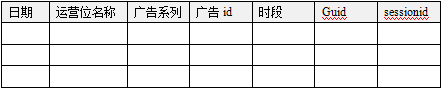
可以支撑的报表分析举例:
X运营广告位日曝光量
X运营广告位曝光量分时趋势分析
X运营广告位点击量
X运营广告位点击量分时趋势分析
X广告系列曝光量分时趋势分析
X广告系列点击量分时趋势分析
……
5.3站外投放广告分析主题
站外广告投放效果分析的数据跟踪原理:

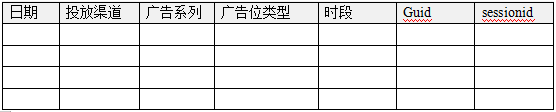
可以支撑的报表分析举例:
渠道投放引流效果分析
渠道拉新分析
各渠道投放引流量分析
各渠道投放引流量拉新数量分析
……
5.4优惠券分析主题
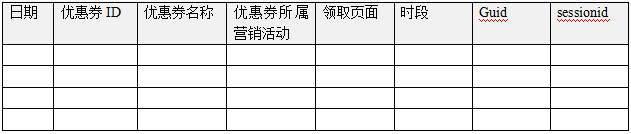
可以支撑的报表分析举例:
优惠券领取次数人数分析
优惠券分时段领取趋势变化分析
……
5.5红包分析主题


红包领取次数、人数分析
红包分时段领取趋势变化分析
6用户活跃度分析主题 [方案一]
6.1中间表设计:连续活跃区间记录
- 用户连续活跃区间记录(类似拉链表)

这个表的核心思想: 记录着每个人的每天活跃信息,但是又不用每天都存储一条记录!
6.2可以支撑的报表分析举例
- 最近一个月内,有过连续活跃10+天的人
- 最近一个月内,每个用户的平均活跃天数
- 最近一个月内,连续活跃[1-10)天的人数,[10-20)天的人数,[20+ 天的人数
- 任意指定的一段日期范围内,连续活跃5+天的人(比如,12-01,12-02,12-03连续3天活跃的人)
- 最近30天内,沉默天数超过3的有多少人,超过5天有多少人
计算日期 月份 10天内人数 20天内人数 30天内人数
2020-10-20 10 100000 8000 0
2020-10-21 10 100020 8020 100
CREATE TABLE ads17.app_useract_stat_m(
calc_date string,
month string,
continuous_5days int, -- 本月内连续活跃>=5天的人数
continuous_7days int, -- 本月内连续活跃>=7天的人数
continuous_14days int, -- 本月内连续活跃>=14天的人数
continuous_20days int,
continuous_30days int
)
STORED AS PARQUET
;
-- 计算 --
WITH tmp AS (
SELECT
guid,
max(datediff(if(rng_end='9999-12-31','2020-10-07',rng_end),if(rng_start<'2020-10-01','2020-10-01',rng_start))+1) as max_continuous_days
FROM dws17.app_useract_range
WHERE dt='2020-10-07' AND rng_end >= '2020-10-01'
GROUP BY guid
)
/*
+---------------+------------------+
| guid | continuous_days |
+---------------+------------------+
| 0TaMafscth6X | 1 |
| 1ANCwzVmNPZo | 1 |
| 1hyVlok7H49P | 5 |
| 1iCCizS18Us0 | 1 |
| 1kFxP0IfmhSf | 6 |
| 1ly5nTS29obZ | 1 |
| 2KiHc1ur1hEG | 1 |
| 2MSQj5R4ITn3 | 1 |
| 2OOMY1MjfK89 | 10 |
| 2Q5lMJtXYuQX | 25 |
+---------------+------------------+
*/
INSERT INTO TABLE ads17.app_useract_stat_m
SELECT
'2020-10-07' as calc_date,
month('2020-10-07') as month,
count(if(max_continuous_days>=5,1,null)) as continuous_5days , -- 本月内连续活跃>=5天的人数
count(if(max_continuous_days>=7,1,null)) as continuous_7days , -- 本月内连续活跃>=7天的人数
count(if(max_continuous_days>=14,1,null)) as continuous_14days , -- 本月内连续活跃>=14天的人数
count(if(max_continuous_days>=20,1,null)) as continuous_20days ,
count(if(max_continuous_days>=30,1,null)) as continuous_30days
FROM tmp
;
- 最近一周内,…
- 最近一个月内,最大沉默天数超10天的,20天的,30天的人 …
6.3DWS层连续活跃区间表开发
-
核心计算逻辑

-
代码开发
6.4扩展:加上维度分析需求呢?
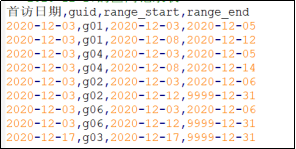
连续活跃区间记录表中,已经丢失了用户的行为详细数据,已经获取不到用户的相关维度属性;
直接通过该表,无法得出 “维度分析”需求的结果;
可以按如下方案设计:
在全局的层面上的,为所有用户维护一张“维度信息表”
GUID, 省 ,市 ,区 ,设备型号 , 首访日期, 年龄, 性别, 会员等级
我所要的维度字段值全在一张表中,在统计分析时,中心表 只要关联 一级 维表,即可得到所有维度字段

星型模型
这张维表,也可以做成如下结构:
①用户属性表:
Guid , 地域码, 设备型号码, 会员等级id
G01 001010 dv101903 2
②设备信息维表:
设备型号码 设备型号名称 操作系统 品牌名称
dv101903 小米6plus android 小米
dv101904 红米note8 android 红米
③会员等级维表
等级id 等级名称
1 白银会员
2 黄金会员
3 钻石会员
④地域信息维表
地域码 省 市 区
001010 广东省 佛山市 富人区

雪花模型
上述两种模型,都属于“维度建模”思想!!
如果,维表中的数据,很少发生变化,则使用“星型模型”更方便(join 少)
如果,维表中的数据,变化比较频繁,则使用“雪花模型”更恰当,因为雪花模型中的维表更符合三范式原则,更新维护更方便灵活!
7用户活跃度分析主题 [方案二]
7.1概述
第3章中的模型设计方案,好处很明显:
- 可以很方便地进行
任意指定日期范围内的用户活跃分析 - 从该表进行各种用户活跃报表统计分析都十分方便和快捷
弊端也有:不够高级!
本章提供另一种更“高级”的方案:
借鉴bitmap数据结构的思想,来实现用户活跃分析的中间表模型
7.2bitmap思想的中间层

表中的bit数组字段:
- 脚标,代表距“now day”的天数,比如,
第1个bit,就是距当天0日前;
第2个bit,就是距当天1日前;
……
- value值,代表用户在该脚标所指示日期上的活跃状态,0表示没有活跃,1表示有活跃
该表的本质: 记录了最近N天(30)内,每个用户的每天的活跃状态;
形式简单直观;存储效率高!
7.3中间层bitmap表开发
1.初始化历史活跃数据成为bit串
比如,今天是2020-12-19,需要初始化 (2020-12-18)-30 ==》 2020-12-18 的bit串
得到形如: g01 --> 100101011010111101101001010110
核心计算表达式:sum(cast(pow(2,datediff('2020-11-18',dt)
reverse(lpad( cast(bin(sum(cast(pow(2,datediff('2020-11-18',dt)) as bigint))) as string) ,31,'0' ))
2.bit串的每日滚动更新计算
前日: g01 --> 100101011010111101101001010110
今天: g01活跃了
今天的结果:g01 --> 1100101011010111101101001010110
T+1日,用户没活跃,则如下更新:
select bin(1073741823 & cast(conv('111111111111111111111111111111',2,10)*2 as int));
T+1日,用户活跃,则如下更新:
select bin(1073741823 & cast(conv('111111111111111111111111111111',2,10)*2+1 as int));
8新用户留存分析主题
8.1需求概念
留存:通常指在X日发生某行为A后,在Y日后又发生了行为B
比如,新用户留存,则指X日发生行为A(首次到访)后,在Y日又发生了B(活跃/到访)行为
8.2查询需求
查询任意指定时间窗口内的,任意一天的新用户的次日、2日、3日、……留存
如下,为一个典型的“新用户留存”分析表
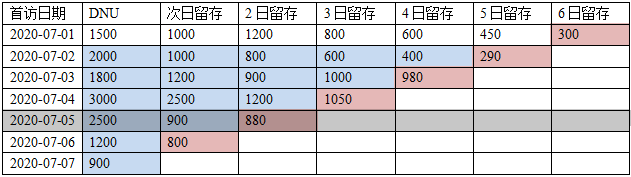
计算要点:
- 每日滚动计算
- 每天计算“x日->计算日” 的留存数即可
8.3中间服务表开发(聚合表)
上述横表形式的报表不方便直接计算,可设计如下纵表(竖表)作为中间表
-
dws.retention_newuser_active

-
代码开发
9漏斗模型分析主题
- 漏斗模型概念:
漏斗模型,是用来分析业务转化率的!
分析师(需求方)定义的一种业务路径,用户沿着这个路径上的各个步骤,不断走向业务目标;
路径上的各个步骤,人数通常是会逐步递减,形如一个漏斗;
把这种分析形象地称呼为:漏斗模型分析;

比如,分析师定义了一个业务路径:搜购
步骤1: 搜索(搜索词为:手机)
步骤2: 点击了一个搜索结果中的商品
步骤3: 将搜索结果中的商品添加到了购物车
步骤4: 提交订单
步骤5: 支付订单
比如,分析师定义了一个业务路径:秒购
步骤1: 点击了秒杀运营位广告
步骤2: 点击了广告落地页中的促销商品
步骤3: 订阅了这个商品的秒杀通知
dws.app_ld_compstep

可以支撑的报表分析举例:
- 搜索购买
–搜索
–点击详情
–添加购物车
–提交订单
–支付订单
- 收藏购买
–收藏商品
–添加购物车
–提交订单
–支付订单
10事件归因分析
在做一些运营活动,广告投放后,都需要去评估活动或者广告的效应;
我们的销量、拉新等业务目标,在广告投放或者运营活动组织后,有了明显的提升,但是这些提升是否是因为广告、运营活动导致的,需要有数据支撑!
这些数据分析,就属于 事件归因分析 的范畴!
而归因分析,又是一件非常复杂的运算;
有如下计算策略(模型):
- 首次触点归因:待归因事件中,最先发生的事,被认为是导致业务结果的唯一因素
- 末次触点归因:待归因事件中,最近发生的事,被认为是导致业务结果的唯一因素
- 线性归因:待归因事件中,每一个事件都被认为对业务结果产生了影响,影响力平均分摊
- 位置归因:定义一个规则,比如最早、最晚事件占40%影响力,中间事件平摊影响力
- 时间衰减归因:越晚发生的待归因事件,对业务结果的影响力越大

11事件间隔分析

12用户行为画像
12.1用户活跃概况属性标签
(近30日)

12.2用户交互事件属性标签
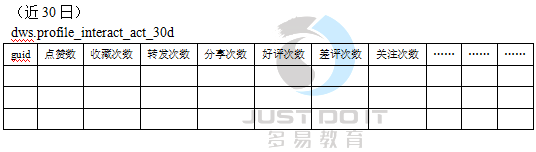
计算方法:
首先,从事件明细表中,按照 用户+事件 分组,count出事件的次数,得到如下结果
g01,dz,5
g01,sc,10
g01,zf,20
g01,hp,10
g01,cp,8
然后,将上面的竖表,转成横表(利用collect_list和str_to_map)
with tmp as (
select
guid,
str_to_map(concat_ws(',',collect_list(concat_ws(':',eventid,cnt))),',',':') as mp
from (
select
guid,
eventid,
count(1) as cnt
from 明细表
group by guid,eventid
) o
group by guid
然后在这个结果上,去按照目标表的字段顺序取值即可:
select
guid,
mp['点赞'] as 点赞,
mp['收藏'] as 收藏,
mp['转发'] as 转发,
mp['分享'] as 分享,
……
from tmp
12.3用户购物事件属性标签
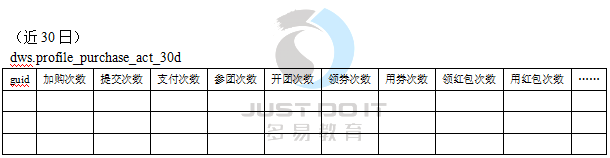
12.4用户运营位事件属性标签















 2316
2316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









