







指定位移消费
试想一下,当一个新的消费组建立的时候,它根本没有可以查找的消费位移。或者消费组内的一个新消费者订阅了一个新的主题,它也没有可以查找的消费位移。当consumer offsets主题中有关这个消费组的位移信息过期而被删除后,它也没有可以查找的消费位移。
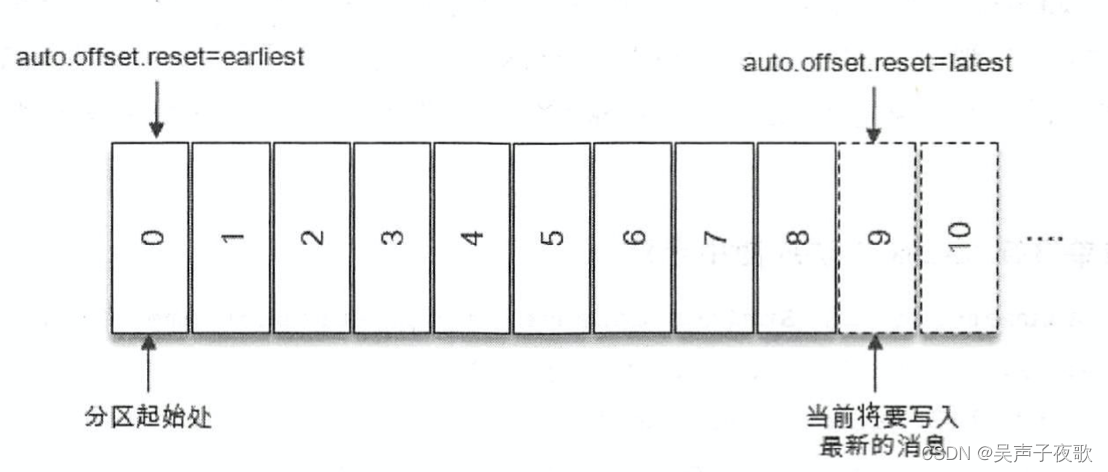
在Kafka中每当消费者查找不到所记录的消费位移时,就会根据消费者客户端参数auto.offset.reset的配置来决定从何处开始进行消费,这个参数的默认值为“latest”,表示从分区末尾开始消费消息。参考下图,按照默认的配置,消费者会从9开始进行消费(9是下一条要写入消息的位置),更加确切地说是从9开始拉取消息。如果将auto.offset,reset
参数配置为“earliest”,那么消费者会从起始处,也就是0开始消费。
举个例子,在auto.offset.reset参数默认的配置下,用一个新的消费组来消费主题topic-demo时,客户端会报出重置位移的提示信息,参考如下:
Resetting offset for partition xxxxxx
除了查找不到消费位移,位移越界也会触发auto.offset.reset参数的执行。auto.offset.reset参数还有一个可配置的值一“none”,配置为此值就意味着出现查到不到消费位移的时候,既不从最新的消息位置处开始消费,也不从最早的消息位置处开始消费,此时会报出NoOffsetForPartitionException异常,示例如下:
org.apache.kafka.clients.consumer.NooffsetForPartitionException:Undefined offset with no reset policy for partitions:[topic-demo-3,topic-demo-0,topic-demo-2,topic-demo-1].
如果能够找到消费位移,那么配置为“none”不会出现任何异常。如果配置的不是“latest”、“earliest”和“none”,则会报出ConfigException异常,示例如下:
org.apache.kafka.common.config.ConfigException:Invalid value any for configuration auto.offset.reset:String must be one of:latest,earliest,none.
1、指定位移消费
到目前为止,我们知道消息的拉取是根据poll方法中的逻辑来处理的,这个poll方法中的逻辑对于普通的开发人员而言是一个黑盒,无法精确地掌控其消费的起始位置。提供的
auto.offset.reset参数也只能在找不到消费位移或位移越界的情况下粗粒度地从开头或末尾开始消费。有些时候,我们需要一种更细粒度的掌控,可以让我们从特定的位移处开始拉取消息,而KafkaConsumer中的seek()方法正好提供了这个功能,让我们得以追前消费或回溯消费。seek()方法的具体定义如下:
public void seek(TopicPartition partition, long offset)
seek()方法中的参数partition表示分区,而offset参数用来指定从分区的哪个位置开始消费。seek()方法只能重置消费者分配到的分区的消费位置,而分区的分配是在poll()方
法的调用过程中实现的。也就是说,在执行seek()方法之前需要先执行一次poll()方法,等到分配到分区之后才可以重置消费位置。seek()方法的使用示例如代码所示(只列出关键代码):
consumer.subscribe(Collections.singleton("testTopic"));
consumer.poll(Duration.ofMillis(10000));
//获取消费者所分配到的分区信息
Set<TopicPartition> assignment = consumer.assignment();
//设置每个分区的消费位置为10
for (TopicPartition tp : assignment) {
consumer.seek(tp, 10);
}
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
//consume the record
}
如果我们将poll()方法的参数设置为0,即这一行替换为:
consumer.poll(Duration.ofMillis(0));
在此之后,会发现seek()方法并未有任何作用。因为当poll()方法中的参数为0时,此方法立刻返回,那么poll()方法内部进行分区分配的逻辑就会来不及实施。也就是说,消费者此时并未分配到任何分区,assignment便是一个空列表,后续代码也不会执行。那么这里的timeout参数设置为多少合适呢?太短会使分配分区的动作失败,太长又有可能造成一些不必要的等待。我们可以通过KafkaConsumer的assignment()方法来判定是否分配到了相应的分区,参考下面的代码:
consumer.subscribe(Collections.singleton("testTopic"));
Set<TopicPartition> assignment = new HashSet<>();
while (assignment.size() == 0) {
consumer.poll(Duration.ofMillis(100));
assignment = consumer.assignment();
}
for (TopicPartition tp : assignment) {
consumer.seek(tp, 10);
}
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
//consume the record
}
如果对未分配到的分区执行seek()方法,那么会报出IllegalStateException的异常。类似在调用subscribe()方法之后直接调用seek()方法:
consumer.subscribe(Arrays.asList (topic));
consumer.seek(new TopicPartition (topic,0),10);
会报出如下的异常:
java.lang.IllegalStateException:No current assignment for partition topic-demo-0
如果消费组内的消费者在启动的时候能够找到消费位移,除非发生位移越界,否则auto.offset.reset参数并不会奏效,此时如果想指定从开头或末尾开始消费,就需要seek0
方法的帮助了,代码清单用来指定从分区末尾开始消费。
consumer.subscribe(Collections.singleton("testTopic"));
Set<TopicPartition> assignment = new HashSet<>();
while (assignment.size() == 0) {
consumer.poll(Duration.ofMillis(100));
assignment = consumer.assignment();
}
//获取给分区的末尾的消息位置
Map<TopicPartition, Long> offsets = consumer.endOffsets(assignment);
for (TopicPartition tp : assignment) {
consumer.seek(tp, offsets.get(tp));
}
代码中的endOffsets()方法用来获取指定分区的末尾的消息位置,参考图中9的位置,注意这里获取的不是8,是将要写入最新消息的位置。endOffsets的具体方法定义如下:
public Map<TopicPartition,Long>endoffsets(
Collection<TopicPartition> partitions)
public Map<TopicPartition,Long>endoffsets(
Collection<TopicPartition> partitions,
Duration timeout)
其中partitions参数表示分区集合,而timeout参数用来设置等待获取的超时时间。如果没有指定timeout参数的值,那么endOffsets()方法的等待时间由客户端参数
request.timeout.ms来设置,默认值为30000。与endOffsets对应的是beginningOffsets()方法,一个分区的起始位置起初是0,但并不代表每时每刻都为0,因为日志清理的动作会清理旧的数据,所以分区的起始位置会自然而然地增加。
beginningOffsets()方法的具体定义如下:
public Map<TopicPartition, Long> beginningOffsets(Collection<TopicPartition> partitions)
public Map<TopicPartition, Long> beginningOffsets(Collection<TopicPartition> partitions, Duration timeout)
beginningOffsets()方法中的参数内容和含义都与endOffsets()方法中的一样,配合这两个方法我们就可以从分区的开头或末尾开始消费。其实KafkaConsumer中直接提供了seekToBeginning()方法和seekToEnd()方法来实现这两个功能,这两个方法的具体定义如下:
public void seekToBeginning(Collection<TopicPartition> partitions)
public void seekToEnd(Collection<TopicPartition> partitions)
2、指定时间消费
有时候我们并不知道特定的消费位置,却知道一个相关的时间点,比如我们想要消费昨天8点之后的消息,这个需求更符合正常的思维逻辑。此时我们无法直接使用seek()方法来追溯到相应的位置。KafkaConsumer同样考虑到了这种情况,它提供了一个offsetsForTimes()方法,通过timestamp来查询与此对应的分区位置。
public Map<TopicPartition,OffsetAndTimestamp> offsetsForTimes(Map<TopicPartition,Long> timestampsToSearch)
public Map<TopicPartition,OffsetAndTimestamp> offsetsForTimes(Map<TopicPartition,Long> timestampsToSearch, Duration timeout)
offsetsForTimes()方法的参数timestampsToSearch是一个Map类型,key为待查询的分区,而vlue为待查询的时间戳,该方法会返回时间戳大于等于待查询时间的第一条消息对应的位置和时间戳,对应于OffsetAndTimestamp中的offset和timestamp字段。
下面的示例演示了offsetsForTimes()和seek()之间的使用方法,首先通过offsetForTimes()方法获取一天之前的消息位置,然后使用seek()方法追溯到相应位置开始消费,示例中的assignment变量表示消费者分配到的分区集合:
consumer.subscribe(Collections.singleton("testTopic"));
Set<TopicPartition> assignment = new HashSet<>();
while (assignment.size() == 0) {
consumer.poll(Duration.ofMillis(100));
assignment = consumer.assignment();
}
Map<TopicPartition, Long> timestampToSearch = new HashMap<>();
for (TopicPartition tp : assignment) {
timestampToSearch.put(tp, System.currentTimeMillis() - 1 * 24 * 3600 * 1000);
}
Map<TopicPartition, OffsetAndTimestamp> offsets = consumer.offsetsForTimes(timestampToSearch);
for (TopicPartition tp : assignment) {
OffsetAndTimestamp offsetAndTimestamp = offsets.get(tp);
if (offsetAndTimestamp != null) {
consumer.seek(tp, offsetAndTimestamp.offset());
}
}
3、消费位移保存在DB中
consumer.subscribe(Collections.singleton("testTopic"));
Set<TopicPartition> assignment = new HashSet<>();
while (assignment.size() == 0) {
consumer.poll(Duration.ofMillis(100));
assignment = consumer.assignment();
}
for (TopicPartition tp : assignment) {
//congDB中读取消费位移
long offset = getOffsetFromDB(tp);
consumer.seek(tp, offset);
}
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
//process the record.
}
long lastConsumedOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
//将消费位移存储在DB中
storeOffsetToDB(partition, lastConsumedOffset + 1);
}
}
seek()方法为我们提供了从特定位置读取消息的能力,我们可以通过这个方法来向前跳过若干消息,也可以通过这个方法来向后回溯若干消息,这样为消息的消费提供了很大的灵活性。seek()方法也为我们提供了将消费位移保存在外部存储介质中的能力,还可以配合再均衡监听器来提供更加精准的消费能力。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









