







基础知识
什么是聚类
在“无监督学习”(unsupervised learning)中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。此类学习任务中研究最多、应用最广的是“聚类”(clustering)。
对聚类算法而言,样本簇亦称“类”。
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”(cluster)。通过这样的划分,每个簇可能对应于一些潜在的概念(类别),如“浅色瓜”“深色瓜”,“有籽瓜”“无籽瓜”,甚至“本地瓜”“外地瓜”等;需说明的是,这些概念对聚类算法而言事先是未知的,聚类过程仅能自动形成簇结构,簇所对应的概念语义需由使用者来把握和命名。
聚类任务中也可使用有标记训练样本,但样本的类标记与聚类产生的簇有所不同
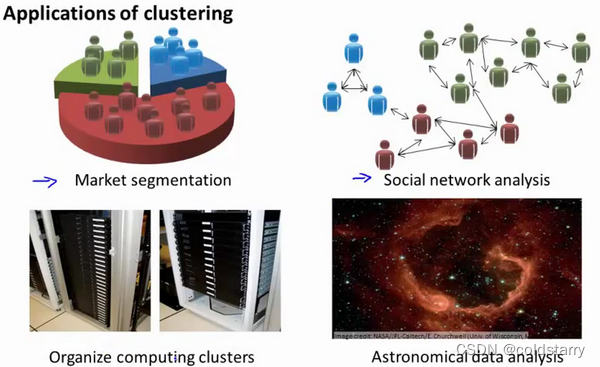
聚类的应用场景
在一些商业应用中需对新用户的类型进行判别,但定义“用户类型”对商家来说却可能不太容易,此时往往可先对用户数据进行聚类,根据聚类结果将每个簇定义为一个类,然后再基于这些类训练分类模型,用于判别新用户的类型
性能度量
-
聚类的性能度量也称作聚类的有效性指标
validity index。 -
直观上看,希望同一簇的样本尽可能彼此相似,不同簇的样本之间尽可能不同。即:簇内相似度
intra-cluster similarity高,且簇间相似度inter-cluster similarity低。 -
聚类的性能度量分两类:
- 聚类结果与某个参考模型
reference model进行比较,称作外部指标external index。 - 直接考察聚类结果而不利用任何参考模型,称作内部指标
internal index。
- 聚类结果与某个参考模型
外部指标

Jaccard系数
FM指数

Rand指数

ARI指数


内部指标

DB指数

Dunn指数

距离度量
常用距离计算

数值和非数值属性混合
当样本的属性为数值属性与非数值属性混合时,可以将闵可夫斯基距离与 VDM 距离混合使用。

加权距离
当样本空间中不同属性的重要性不同时,可以采用加权距离
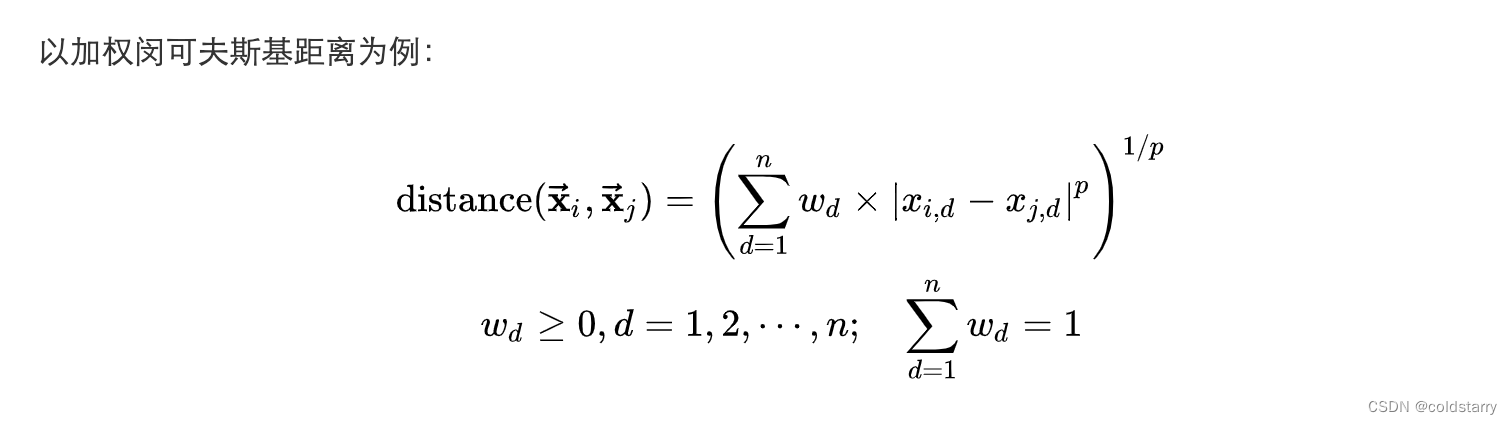 直递性
直递性
直递性常被直接称为“三角不等式”
这里的距离度量满足三角不等式:![]()
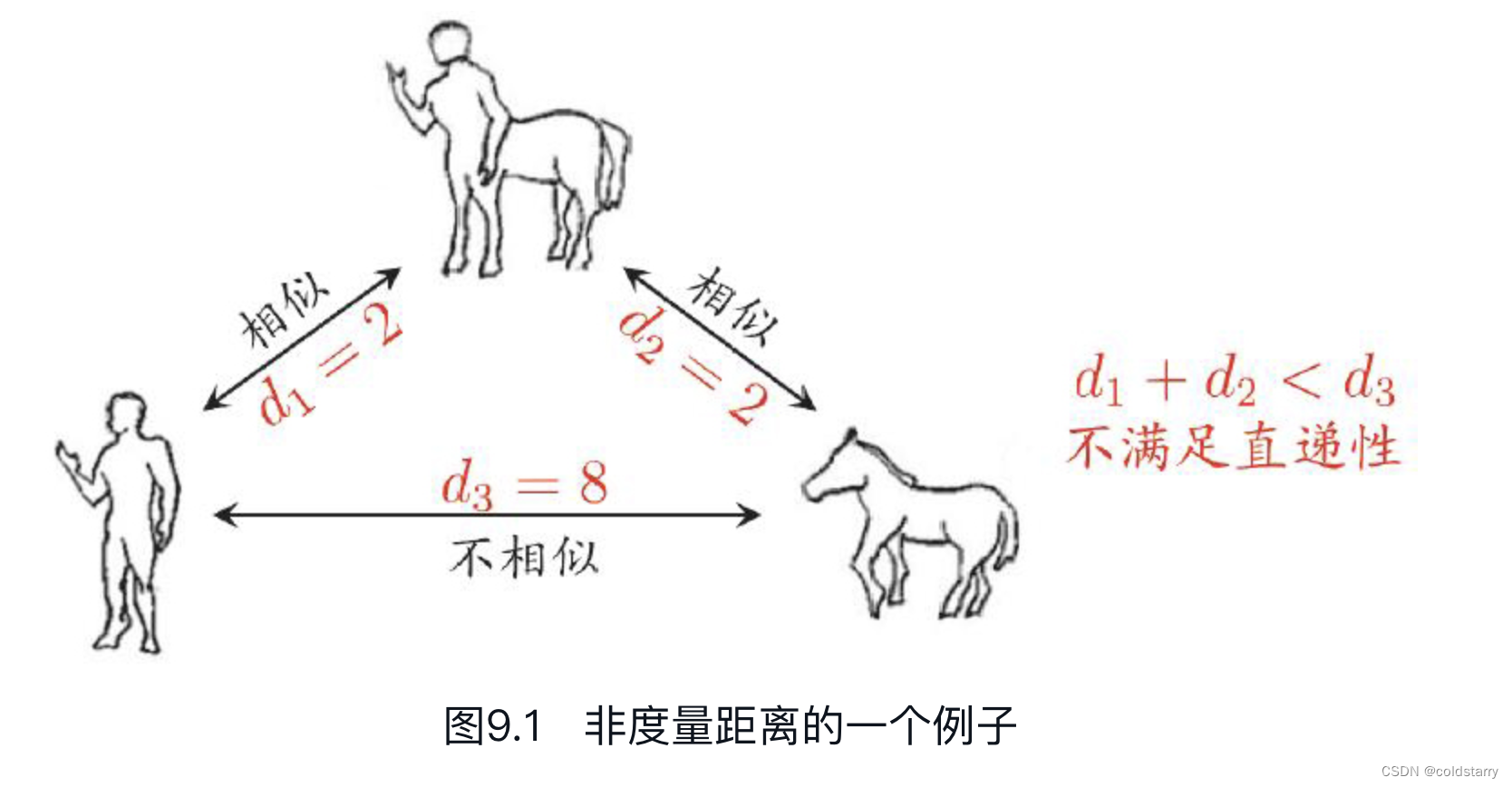
需注意的是,通常我们是基于某种形式的距离来定义“相似度度量”(similarity measure),距离越大,相似度越小。然而,用于相似度度量的距离未必一定要满足距离度量的所有基本性质,尤其是直递性。
例如在某些任务中我们可能希望有这样的相似度度量:“人”“马”分别与“人马”相似,但“人”与“马”很不相似;要达到这个目的,可以令“人”“马”与“人马”之间的距离都比较小,但“人”与“马”之间的距离很大,此时该距离不再满足直递性;这样的距离称为“非度量距离”(non-metric distance)。















 788
788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









