







作者公众号 大数据与AI杂谈 (TalkCheap),转载请标明出处
年底果然各家AI视频厂商扎堆更新,昨天才写了一篇Vidu2.0版本更新的测评文章,同天通义也更新了他的文生视频模型,最新版本是2.1版
和我两个月前做的测试相比,2.1版文生视频模型能力明显得到了大幅的提升,效果拔群,我总体甚至感觉这个版本可称当前(2025年1月10日)国内最强文生视频模型。那下面那我们来看看它的实际表现
注:通义是阿里的大模型家族的通用代号,包括各种大语言和图像视频模型,本文介绍的是其视频生成模型通义万象
网址: https://tongyi.aliyun.com/wanxiang/videoCreation
也可以在通义APP里使用
相比两个月前,网站和APP的设计一如既往的糟糕,但没关系,我们还是看模型产品自身能力
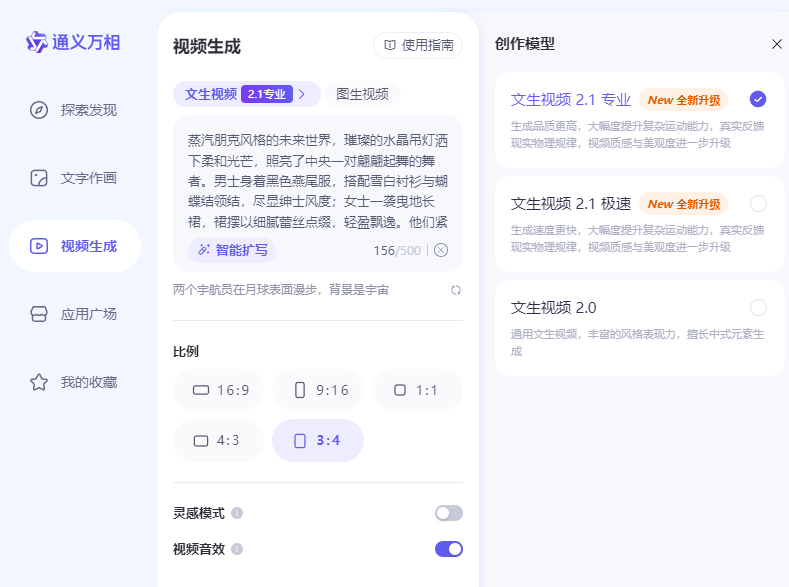
测试
首先测试一段跳舞的视频,跳舞类的视频一直也是视频生成的难点,因为动作,手,脚都不在常规的位置上,相互交叉错位的情况也很复杂,过往大多数产品生成的舞蹈视频基本都是各种肢体扭曲,又或者动作非常僵硬不自然
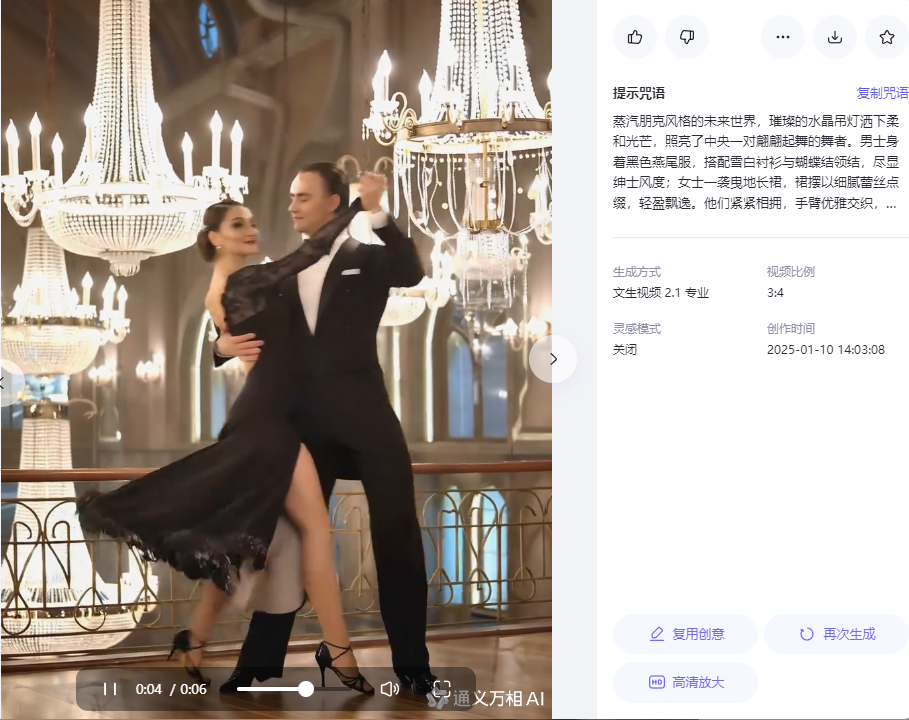
提示词:“蒸汽朋克风格的未来世界,璀璨的水晶吊灯洒下柔和光芒,照亮了中央一对翩翩起舞的舞者。男士身着黑色燕尾服,搭配雪白衬衫与蝴蝶结领结,尽显绅士风度;女士一袭曳地长裙,裙摆以细腻蕾丝点缀,轻盈飘逸。他们紧紧相拥,手臂优雅交织,随着华尔兹旋律旋转跳跃,每一步都诠释着浪漫与激情。中景,采用稳定跟随拍摄,捕捉每一个旋转瞬间。”
类似的提示词我生成了五六个视频,大体上都还不错,产出质量比较稳定,图像也非常写实,除了有少量瑕疵和个别肢体错误,整体动作都非常流畅,舞蹈动作的肢体非常到位,非常好的体现了华尔兹舞蹈的优美韵律。 下面的视频,我不做任何删减编辑(包括错误部分也都保留了),简单编排在一起,大家自己可以看看实际效果
【这里是GIF】(好了,这里看不到视频,要看完整视频请去公众号。。。下同)

值得一提的是,通义万象能够直接生成视频的声音,所以视频里的所有声音都是通义生成的,我没有添加后期音乐,大家可以感觉一下,是不是大部分和视频内容搭配的都比较恰当
华尔兹可能难度还不够大,那么让我们来画一下钢管舞,高难度的动作扭曲,挑战一下极限能力。这回2.1模型也没能很好的完成任务,出现了一些肢体穿帮的动作,但一段视频也有50%左右的部分是可用的,如果多抽几次卡,也能凑出一些可用的片段。下面同样无删减剪辑在一起,大家自己看效果和问题自己判断一下

忍不住又测试了一下同样困难的芭蕾舞。“视频展示了在一个宽敞明亮的舞蹈室里,一位美丽的女孩穿着经典的芭蕾舞裙,伴随着悠扬的音乐,优雅地跳起了芭蕾舞。她的每一个旋转、跳跃和伸展都充满了力量与美感,仿佛在空中划出了完美的弧线。视频通过多角度的拍摄,捕捉了女孩每一个精致的动作,展现了芭蕾舞的精髓和女孩卓越的舞蹈技巧。”
没想到居然接近完美,转了好几圈,手,腿,脸,基本都没有穿帮,除了手运动太快有些糊,其它都很清楚。估计训练的时候喂了不少类似的训练素材?

其它再展示几个不同内容的视频,提示词就不详细说明了,看视频内容就明白了
吃面,主要看一下物理效果,面是不是真的能吃下去

男女小丑撑着伞,拎着棒球棍,走在下雨的上海街头,看一下正常全景人物和指令的遵守能力

喀纳斯雪地航拍,看一下非人物风景视频的效果

恐怖的阁楼,惊恐的女孩,看一下光影和表情

小结
2.1版本的模型,语义理解能力和人物动作流畅性,运动的自然性都有了巨大的提升,对一些比较复杂的肢体运动也有很大的概率能较好的生成,不太容易出现明显的崩坏情况,真的是让我有些意外。
毕竟之前通义万象的视频,语义理解能力和视频整体结构质量也就在第一梯队末尾到第二梯队之间,而在大幅度动作和运动流畅性方面,则明显不如其他国内领头羊产品。但这次升级之后,除了画质相比其它产品在伯仲之间,还有提升的空间以外,视频的语义理解和人物动作控制等方面,我认为目前暂时是第一的
而视频配套的声音生成,也不再像以前,很多情况下是毫不相关的噪音,有部分已经快达到直接可用的水准了(不谈背景声音和音乐是否优美,只说和内容的相关性),不知道什么时候可以把糟糕图生视频模型也更新了。

















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









