







作者公众号 大数据与AI杂谈 (TalkCheap),转载请标明出处
近期肝了很长时间,把国内外相对主流和常见的AIGC图像,视频,音频生成产品,网站都试用了一圈,做了一下总结,分享给大家。
本文主要是对一些音频生成产品的功能做简单地介绍和展示,图像生成和视频生成的产品介绍,可以参见前两篇文章
AIGC视频生成网站和工具大全:十六款产品功能,效果展示和价格比较
AIGC图像视频网站工具大全:数十款图像、视频、音频生成网站和软件,总有一款适合你(图像篇)
音频相关产品相对来说,热度没有图像和视频类生成产品来得高,但如果要正经做视频的话,音频的使用,还是必不可少的。音频类产品,大体上可以分为语音生成(转换)类,音乐生成类,和歌曲生成类。前者有非常多的成熟产品了,也有很多传统的技术实现,后两者则是在这两年在技术方面得到了快速迭代进步,特别是歌曲生成类,也逐渐迈入实用的阶段。
以下是本文音频篇中的介绍的主要产品列表:
-
suno
-
海螺音乐
-
海绵音乐
-
Udio
-
豆包音乐
-
天工音乐
-
StableAudio
-
Artlist
-
boomy
-
music-fx
-
通义
-
CosyVoice
-
Sovits
-
AudioCraft
suno
网址:www.suno.com

Suno是音乐AIGC领域,老牌成熟商业产品的代表。功能迭代也还比较频繁,音乐和歌曲的生成质量,从我这个完全没有音乐细胞的人的角度来看,大体也还是很不错的,具备比较好的多样性。此外,中文发音支持的也不错,大多数情况下都比较自然,比较少出现那种外国人说中文撇嘴,跑调的情况,但也有个别情况会丢词。
suno能够单独生成器乐,也能把乐器和人声混合生成歌曲。它最新的3.5模型,最长能生成4分钟长度的音乐。如果长度不够,你还可以对生成的音乐进行延长(接曲),虽然延长的效果不是完全可控,曲风也不一定完全匹配,但也还是有一定的实用性。如果你会使用一些音频编辑软件,对前后两次生成的音乐稍微做一些融合处理的话,也能整合出更长篇幅的完整歌曲。
此外Suno生成的歌曲也会根据歌名再给你画张图,配上字幕,做成个视频之类的,便于你分享你的成果。当然,这些功能也基本上是后来的类似产品的标配产品形态了。
除了通过自动生成歌词和自定义歌词来生成歌曲,如果你是IOS手机APP用户,最新的Suno Scenes功能,也支持通过一张图片来生成音乐。大体是根据图像的风格和内容,作词并生成歌曲。
优点:
歌曲生成质量较好,效果比较稳定。
功能相对比较全面,毕竟是领头羊产品。
中文发音支持相对不错
缺点:
操作界面相比后来的一些产品,易用性稍微差一点。
一些附加的指令控制歌曲中的生成要素之类的功能较少。
费用:

如果你只是随便试试,免费用户一天生成10首歌曲的额度大体也够用了。价格看你怎么看,自己玩不算便宜,对有业务需求的人来说,不算贵。
海螺音乐
网址:https://hailuoai.com/music
上一篇写海螺视频的时候,还是免费的。才写完没几天就开始收费了。而海螺音乐目前还是免费的。但近期功能迭代更新似乎不多,可能精力都去搞视频了?
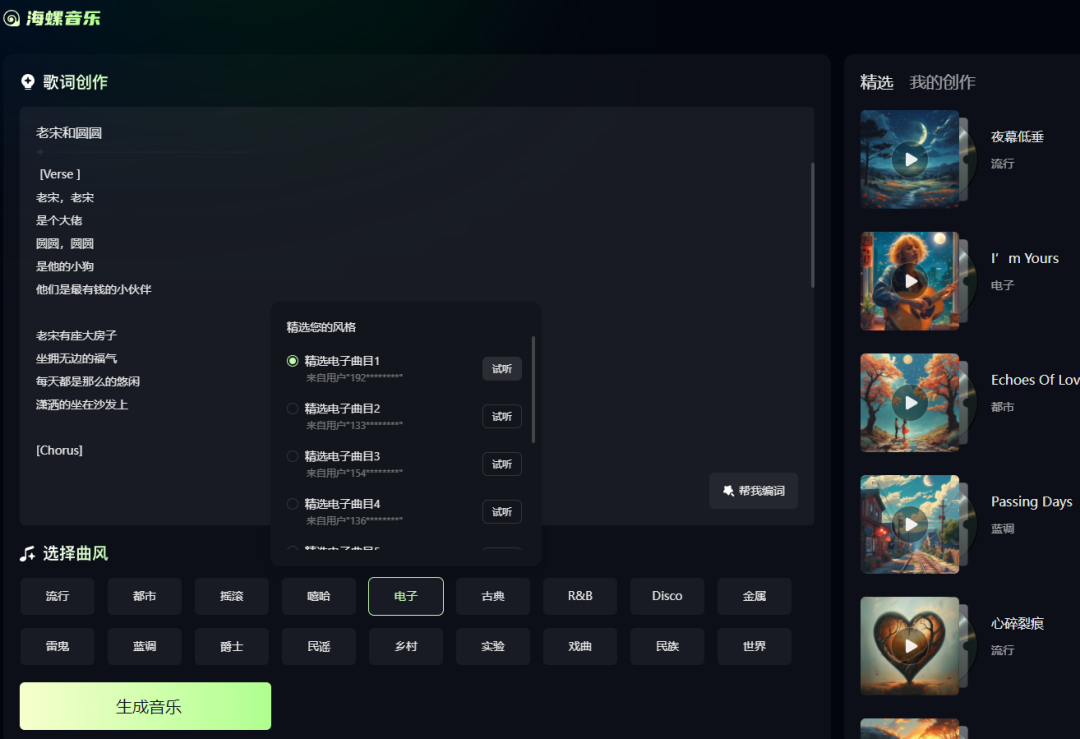
海螺音乐生成音频的方式,我猜和Suno有比较大的区别,目前的方式更像是参考指定曲目的节奏和风格,然后模仿重唱新的歌词,更接近对前面指定的歌曲,进行相似性拓展的感觉。
所以曲风上,你不是只是选择一个风格,而是选择一个具体的曲目,当然,也就没有办法同时选择多个风格了。这样的好处是参考的对象很具象,你比较容易预判生成的歌曲的整体感觉,不好的地方,就是生成的结果,变化相对较少。有很重的对原歌曲的模仿的感觉,原创性和曲风变化较少,所以有时候整体感觉质量就比较一般。
不过也是因为如此,曲风就不太有限制,反正就是模仿呗,所以,甚至能生成京剧唱腔的歌曲。
优点:
目前音乐生成速度比较快,且不限额度
可以选择参考具体的歌曲,结果有一定的可预测性
缺点:
只能生成一分钟长度的音乐,所以多半只能当做试听,或者片段,很难作为完整的歌曲使用,如果你有较强的音乐编辑能力,或许可以自己合成。官方也说了,中文的歌词,推荐8行左右。
费用:免费
海绵音乐
网址:https://www.haimian.com/
海绵音乐也是字节旗下的产品,我感觉是目前国内最接近Suno的产品了,音乐生成的质量非常好,交互界面做得比Suno优秀。国内的产品,中文发音自然是没有问题的,非常顺滑。
海绵音乐的灵感创造功能,也提供了和Suno类似的上传图片生成歌曲的能力,我试了几首效果都还不错,风格是跟着图像来的,歌词则会围绕着画面的一些元素进行创作。比如我上传了一张万圣节哥特风格的摄影照片,画面带一点恐怖元素,结果生成的曲风就很有90年代的味道,歌词带一点无厘头的发廊摇滚色彩。
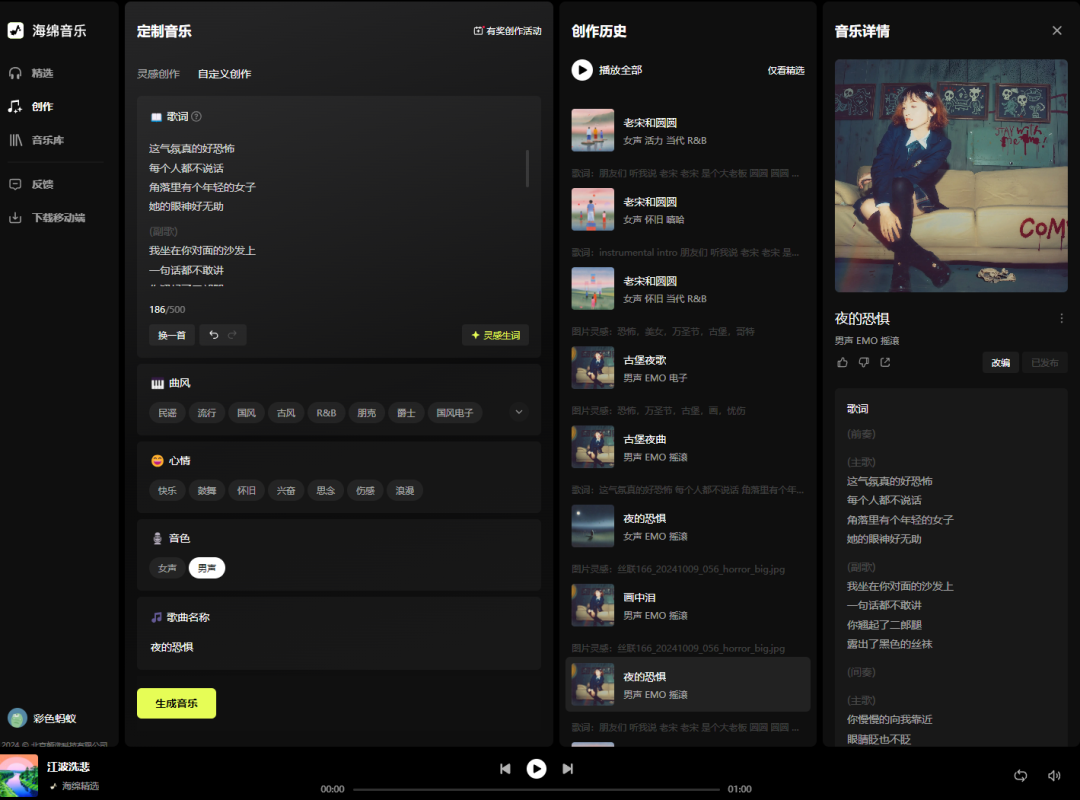
优点:
生成的歌曲结构非常完整,不是特别长的歌词的话,不太容易出现唱了一半突然停止的情况
不限量免费试用,生成速度非常快,3分钟的歌曲可能一分钟就生成完毕了。
缺点:
风格和心情是固定搭配的选项,不能够同时选择多个风格,没有更灵活的自定义的方式。
声音是指定的,或男或女,始终是同一个声音,不像suno,可能生成男女混唱,合唱,伴唱的曲目。
费用:当前是免费的。
udio
网址 https://www.udio.com/
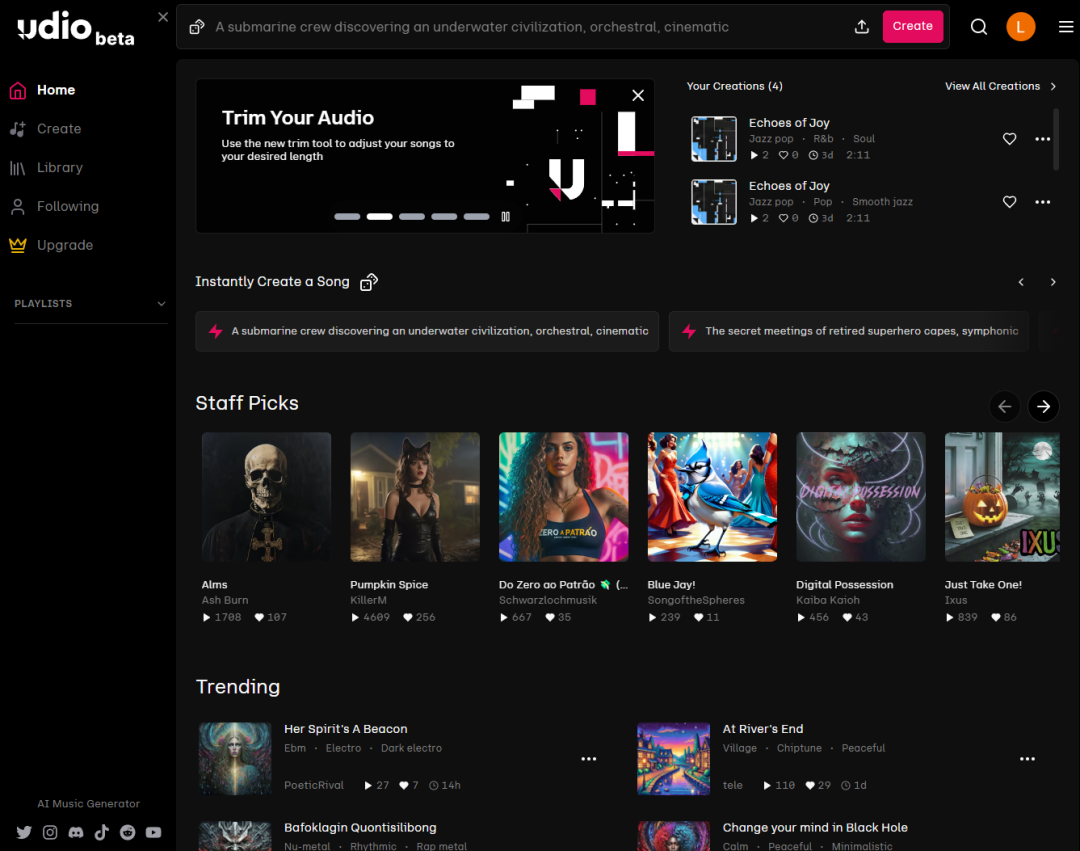
udio相对suno来说是比较新的一个网站,和suno孰优孰劣,反正各有各的说法,有说udio音质更好的,也有说suno更稳定更可控,旋律更优秀的。旋律好坏我不知道,音质嘛,用udio生成了几首爵士乐风格的歌曲,对我这个外行来说,黑人女歌手的声音确实还挺像那么回事,不管是什么词,反正都能给你套进去顺利唱下来。
至于中文发音呢,运气好呢,还挺标准,但很大概率发音会嘴瓢,唱摇滚就还适合。
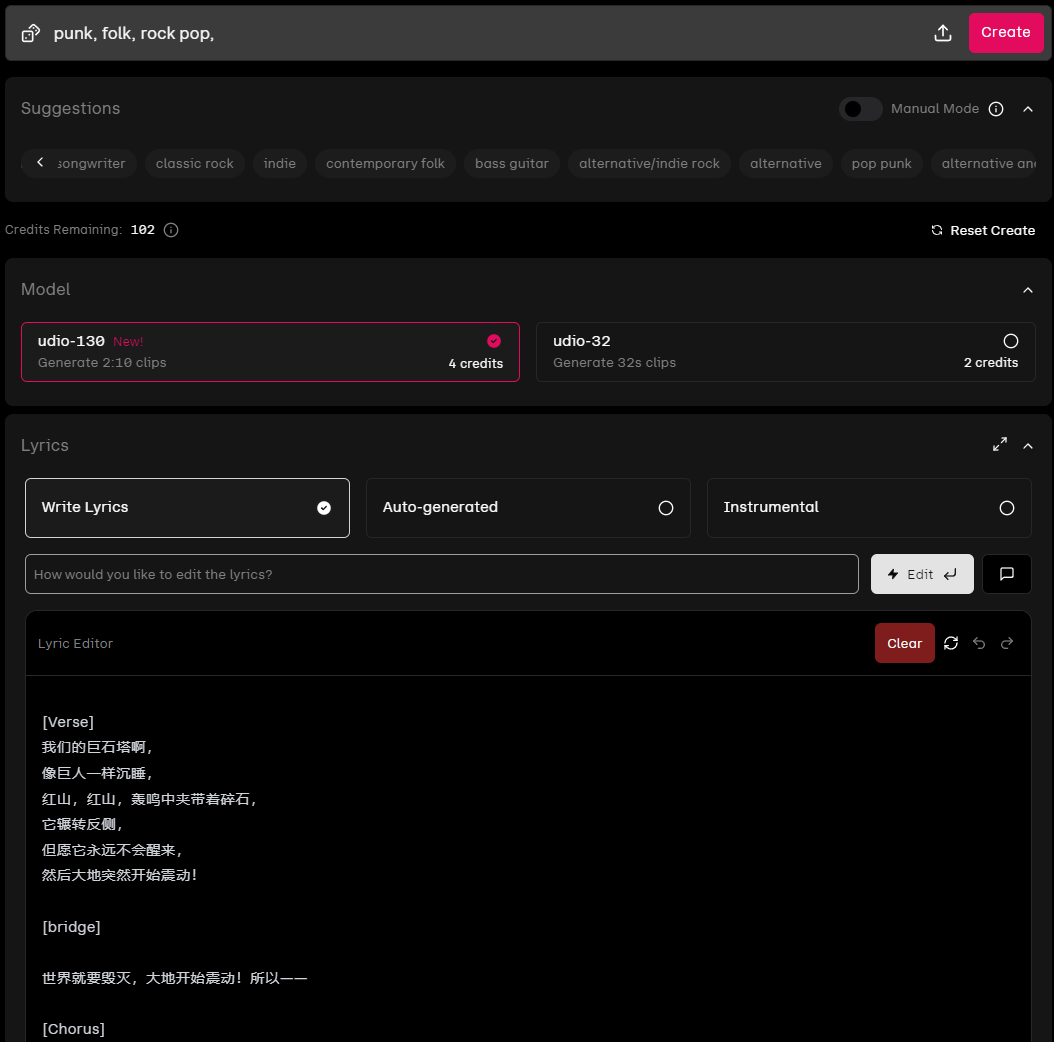
Udio生成的音乐,有2分10秒和32秒两种长度,比较让人崩溃的是,这个长度是固定的。。。不管你给的歌词有多长,生成的歌曲就是这个长度,所以,最后的歌曲和歌词往往是不对齐的,如果歌词比较短,那么Udio就会各种自由发挥,补各种前奏,合唱混唱,词也是各种自创改编,调整顺序,换位置等等,并不会严格按照你的歌词来。
往好了说是创意无限,往坏了说是可控性不太好。
优点:
音质好,生成歌曲有时候有意外的惊喜。人声比较顺滑,会有变化起伏,不像有些产品生成的声音一直很平。
缺点:
网站交互设计一般,略显混乱。歌词可控性较差,效果较为随机。中文发音时好时坏,不太标准。
费用:免费账号,每个月总共100个信用点的限额,然后每天还有10个信用点限额,只够一天生成两次共4首2分钟长度的歌。免费账号也无法做任何后处理,比如编辑修改歌词之类的。付费用户的话,如果不是重度使用,10刀的计划,一个月300首左右,可能就可以了。

豆包
网址:www.doubao.com
豆包的音乐生成功能,可以在网站上使用,也可以在APP中使用。
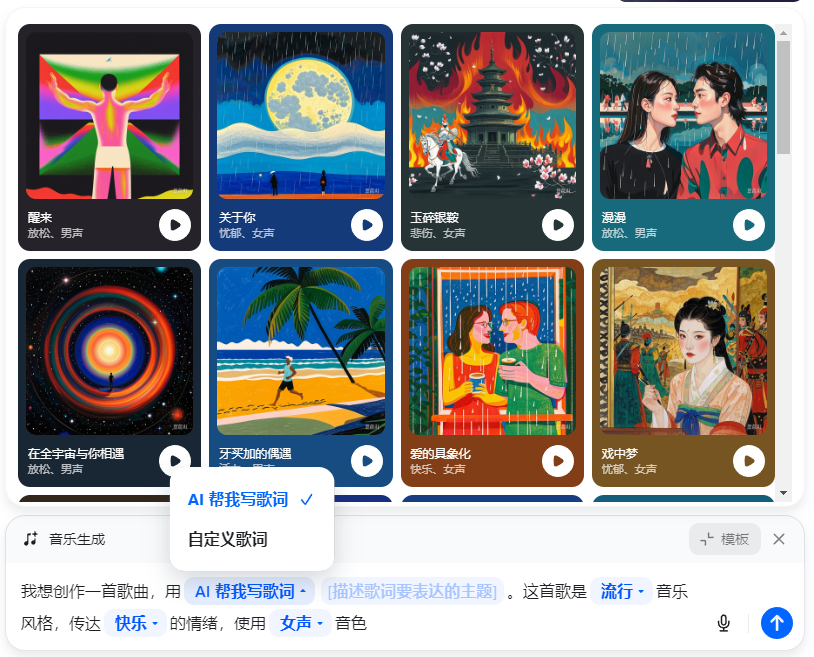
作为智能助手的一部分功能,豆包音乐同样是通过问答对话的形式输入和生成音乐的,生成质量也还好,但是交互方面,不像其它音乐类产品,没有专门的页面,对话框的形式,编辑起来就不那么方便了。
歌曲生成的旋律和人声相对单调一些,另外,有200个字的限制,也没法接曲,生成的歌曲也只有59秒的长度。所以总体来看,可能生成一点短的音乐还可以,用来生成歌曲基本是不太够的,就是玩玩了。我估计也不是能力不行,大概更多的还是豆包这个偏办公助手的产品定位导致的。
优点:和豆包整合,方便使用。
缺点:歌曲字数,长度的限制都太短了,基本没法正经使用
费用:免费
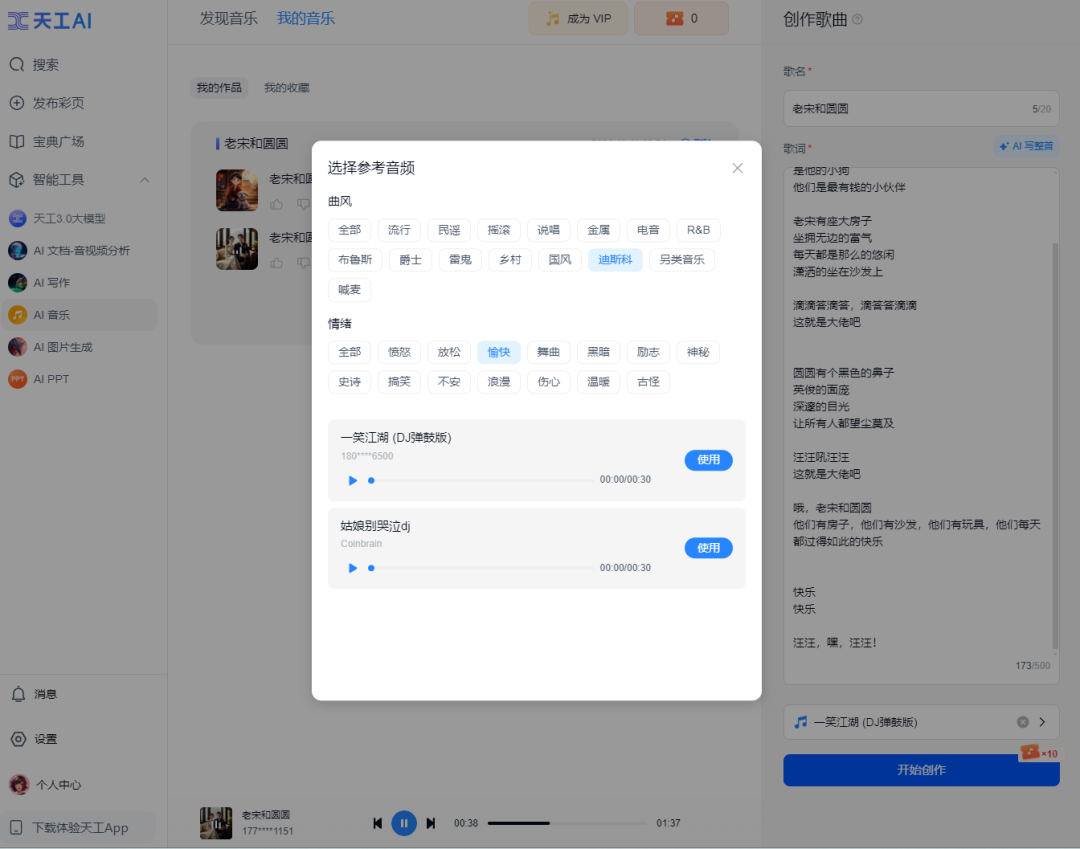
天工音乐(SkyMusic)
网址:https://www.tiangong.cn/music
这个是昆仑万维的产品,AI音乐是天工AI产品中的一个
整体没有什么太出彩的地方,和海螺音乐类似,采用特定曲目风格模仿的方式来生成歌曲,但效果而言,只能说节奏大体像,曲风模拟的一般。质量一般,变化较少。加上新账号给的积分就只够试验一首的。。。所以我也就没做更多的实验和比较了。就不做优缺点评价了。
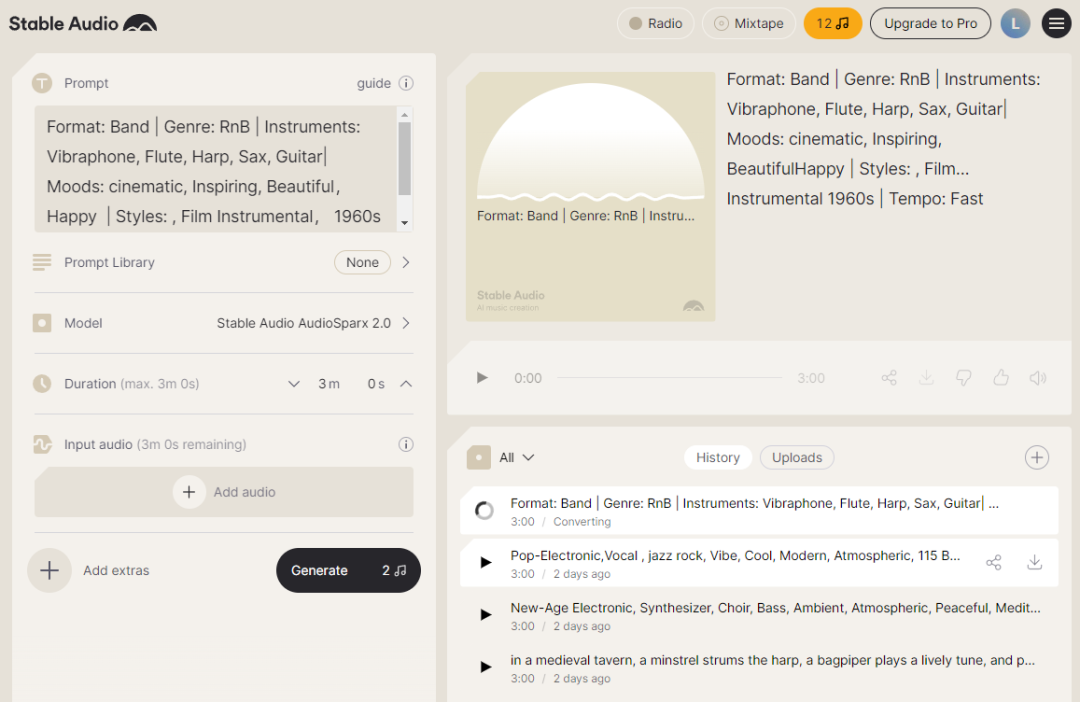
stableaudio
网址:https://stableaudio.com/generate
StableAudio只能生成纯音乐,最长可以生成3分钟。界面比较简单。你在提示词里可以填写所要的曲目的几个要素,比如是独奏还是乐团合奏,曲风,包含的乐器,情绪,风格,节拍快慢等等。当然,生成的效果如何,也和你的这些风格组合,合不合理相关了,比如说你要用笛子表演一个摇滚风格的曲目,那。。。如果你不知道怎么写,也可以使用它的模版或者随机生成上述各要素的组合参数。
优点:能详细指定乐曲的各种要素构成
缺点:质量一般吧,我是没太听出有什么特别的,总感觉生成的音乐平平无奇,留不下印象,也可能我姿势不对。
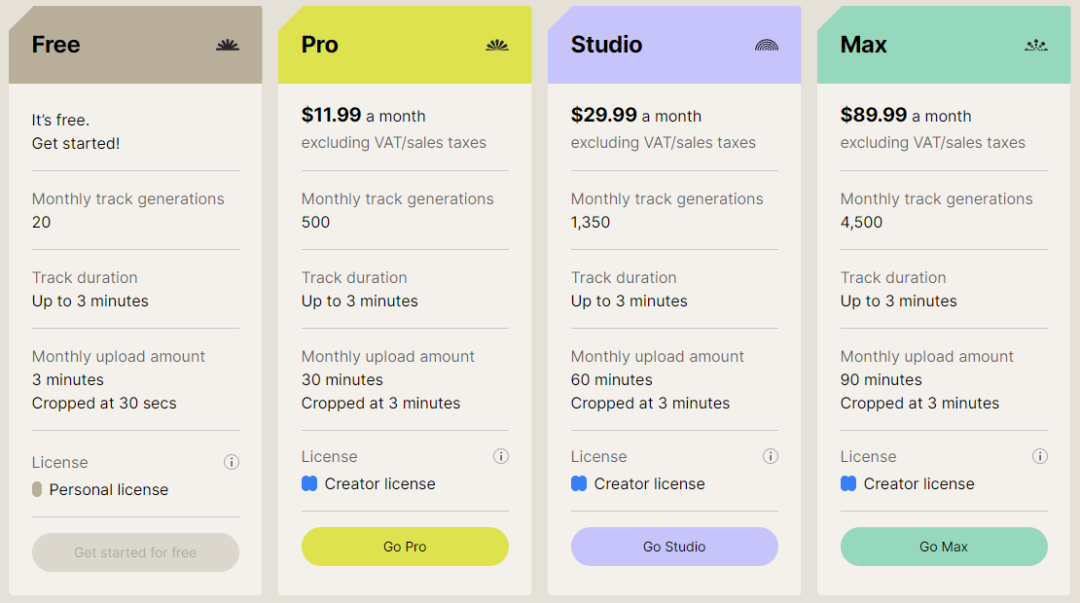
费用:免费用户一个月大概能生成10首3分钟的乐曲,12刀的付费计划不算便宜,相比于它能完成的工作来说。
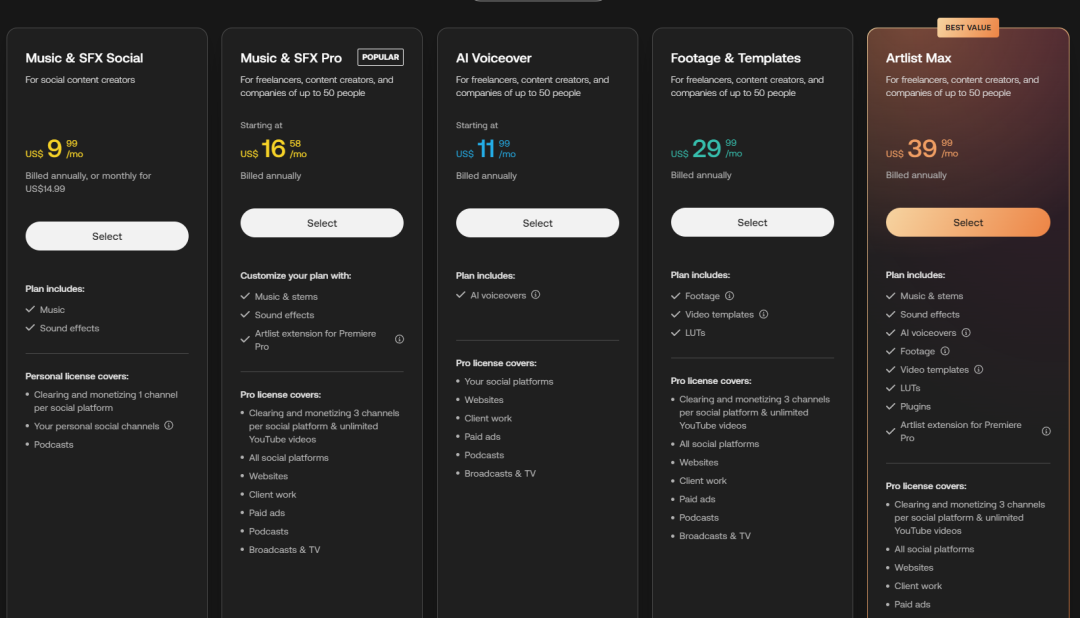
artlist.io
网址:https://artlist.io
artlist严格来说,是一个视频创作的素材网站,提供包括各类音乐,音效,视频片段,视频编辑模版,LUTs和特效插件在内的各类素材的下载。使用它的付费计划,网站上的素材就可以不限制的使用,而不用担心版权问题。
但它也提供了语音合成的功能,用来做视频的旁白。也就是网站上的Voiceover功能。
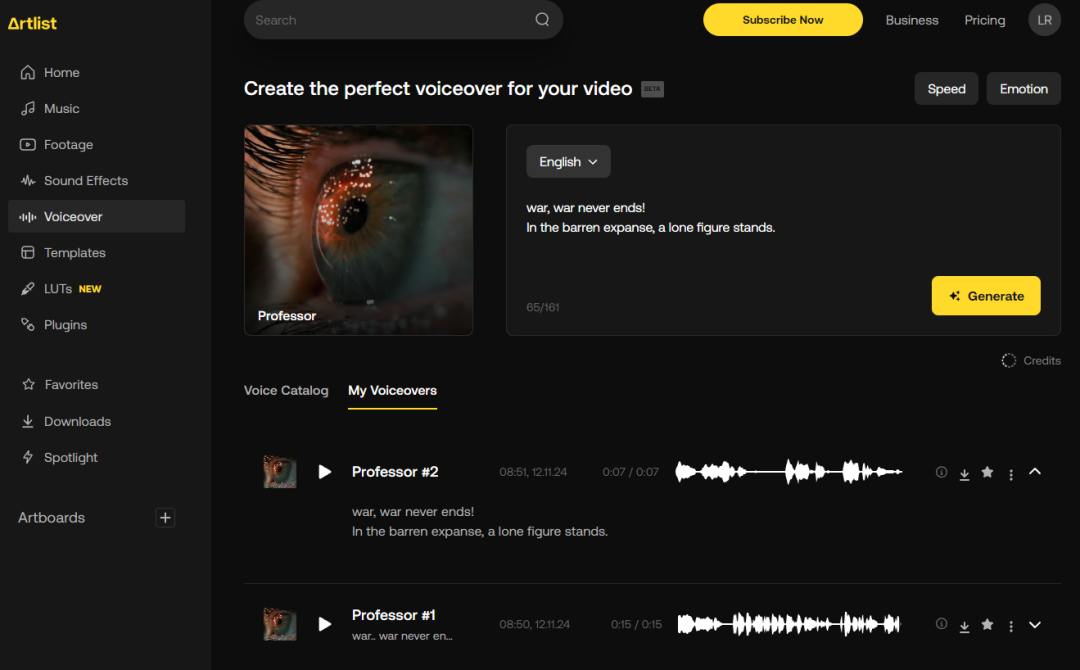
据说是有不少专业视频创造者使用它来搜索素材和创建旁白。免费计划无法下载其它素材,只能试用旁白创建的功能。计费方式,貌似是按字母数计费的,一个字母一个信用点。400的信用点大概就够创建20秒左右长度的音频。所以只够你简单试验一下效果,生成完还不能下载。至于生成效果,我个人感觉还是不错的,声音比较有特色,不像其它语音生成产品,人物声音缺乏特点,这里的语音选择基本都是面向视频解说场景,各种风格非常明显。
其它素材的质量看起来也是有保障的,毕竟大部分是人工生成的商业素材,而非AI自动生成的,对视频工作者来说,按月订阅而非按量计费的计划,可能用量多的话,也还算便宜。
优点:素材质量高,旁白语音效果独特
缺点:旁白语音只支持英文,不支持中文
费用:个人玩玩不算便宜,商业用户应该还可以了。
其它几个产品简单介绍一下
boomy(LoopMagic)
网址:https://app.loopmagic.com/create
合成20秒左右一些简单的乐器音,当素材可以,当曲子还是有点困难。
music-fx
网址 https://aitestkitchen.withgoogle.com/tools/music-fx
这个是谷歌AI实验室里的一个工具,能生成30秒的无人声纯音乐,比较有特色的地方,是可以选定循环模式,这样生成的音乐首尾部分会比较接近,可能适合一些场所做循环播放的背景音乐。
通义
严格来说,通义的的全民K歌,全民舞台等模块,不算音乐生成,而是视频转绘和对口型。面向的也不是视频或音频创作者,更多的是偶尔玩梗开心一下的普通用户。
质量不错,动作和表情比较流畅,免费试用
开源软件产品
开源软件中,语音合成,音乐生成的相关项目也非常多,先简单介绍两个语音生成和音色转换的软件
CosyVoice
很多开源软件可以模拟特定语音人声,但是通常都需要提供十几到二十分钟以上的语音作为训练素材,训练完特定的模型以后才能使用。而CosyVoice只需要一段3秒左右的音频,就能模拟到80%像。我家小朋友学校,公众号文章要学生自己朗读自己被选上的作文。我家小朋友口齿不清,干这事估计录多少遍都不顺,就用CosyVoice模拟生成了一段3-5分钟左右的朗读音频交上去,反正老师应该是没有听出来是AI生成的。
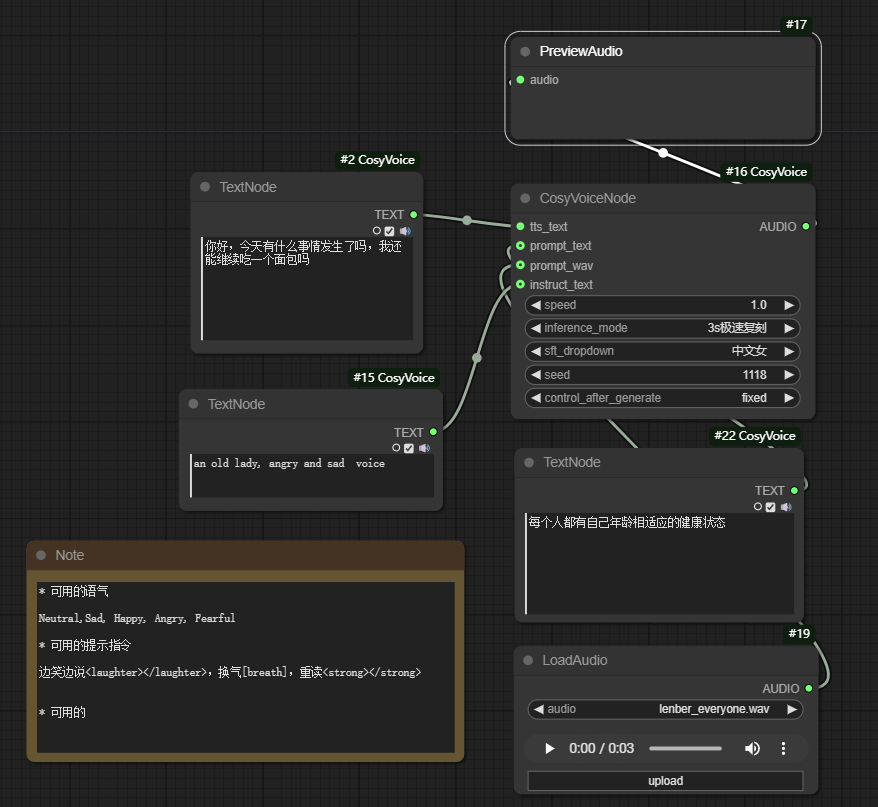
CosyVoice的功能除了3秒复制音色,还提供中英文音色转换,特定的文本,生成一些内置音色的语音生成,包括添加一些语气和笑声,换气的指令等不同的功能模式。
不过这类音频生成软件,安装包依赖都比较复杂,模型文件的体积往往也比较大,依赖包的版本往往也比较老或者版本比较特殊,如果没有足够的动手能力的话,自己安装还是比较麻烦的,最方便的还是下载打包好的一键安装包。或者使用单独的一份ComfyUI免得和其他插件的依赖有很大冲突。
优点:可以免训练快速复制自己的声音音色
缺点:只能生成说话的语音,无法生成唱歌等有旋律节奏的声音。
sovits
如果需要换音色唱歌的话,可以使用Sovits,之前网上的AI孙燕姿之类的,大体就是用它来生成的。这个就需要训练模型了。当然,同样有很多一键安装包可以使用。所以部署并不困难,麻烦的主要还是自己声音的采集和训练。比如我训练自己的音色,录了一个小时的声音,做了降噪处理,然后选了其中半小时左右的声音,做了一些片段切割之类的预处理工作,最后花了几个小时,训练了3万步,整套流程下来,前后断断续续花了两三天时间才搞定。
模型训练完以后,推理部分就是音色翻唱了,这部分稍微简单一点,但也需要把原歌曲的曲和人声分离以后,单独转换人声的音色,然后再把原曲合成回去。所以也还是有一定的上手门槛的。另外,这是音色转换,不是语音生成,所以是不能无中生有的,如果要生成自己音色的声音,是需要配合别的TTS类语音生成软件来使用的。
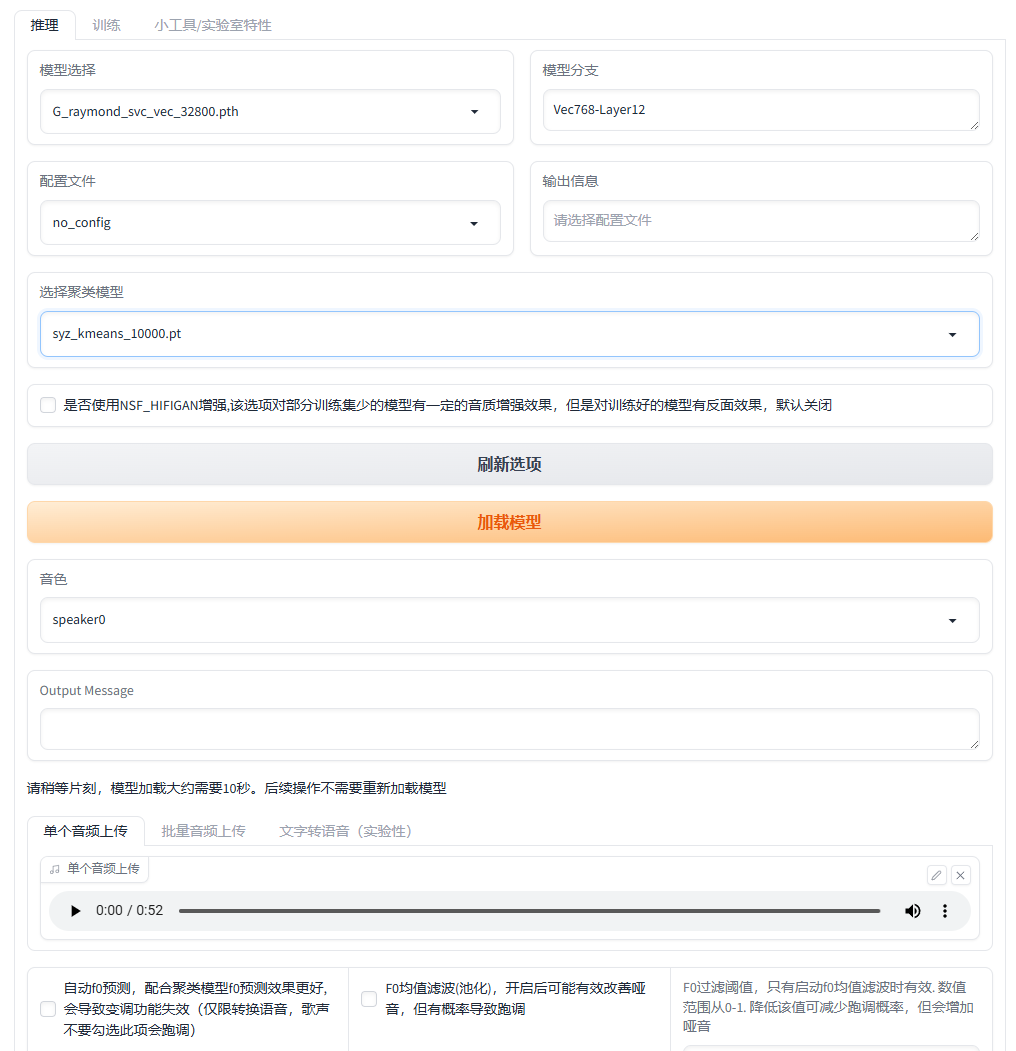
麻烦归麻烦,这么一套搞下来,效果还是不错的,唱歌基本和本人的声音音色有九成接近,也让我这个五音不全的人能够一展歌喉了。。。
优点:音色模仿质量高,能够翻唱歌曲
缺点:需要训练模型,流程相对复杂,使用门槛高
audiocraft 和 StableAudio
前面两个都是人声的生成和转换,如果你想生成音乐的话,meta的AudioCraft(包含MusicGen和AudioGen)和前面的StableAudio都有开源项目可供下载安装,如果你不想自己折腾,也可以去他们的HuggingFace空间或者官网试用一下。效果呢,反正和商业的比,就比较一般了,AudioGen生成音效可能可以尝试一下。因为安装起来也比较麻烦,整合包也差不多30-40个G,安装了太多模型,这俩我就不折腾本地部署了,有兴趣的同学可以自己去试试看。
MusicGen网址 :https://huggingface.co/spaces/facebook/MusicGen
总结
suno:音乐 AIGC 领域老牌商业产品,功能迭代频繁,音乐和歌曲生成质量不错。功能全面、中文发音支持不错;操作界面易用性稍差、附加指令控制功能少;免费用户一天生成 10 首歌曲额度
海螺音乐:目前免费,生成音频方式类似参考指定曲目进行模仿重唱,曲风限制小,但生成结果变化少、原创性低,且只能生成一分钟长度音乐。
海绵音乐:字节旗下产品,音乐生成质量好,交互界面优,有灵感创造功能可上传图片生成歌曲,生成速度快且免费试用,但风格和声音选择不够灵活。
udio:相对较新的网站,音质好,生成歌曲有时有惊喜,但歌词可控性差,中文发音时好时坏,网站交互设计一般
豆包:作为智能助手一部分,通过问答对话生成音乐,生成质量尚可,但受限于歌曲字数、长度,基本很难正经使用。
天工音乐:昆仑万维产品,采用特定曲目风格模仿方式生成歌曲,效果一般,节奏大体像,曲风模拟一般。
stableaudio:只能生成纯音乐,可详细指定乐曲要素,但生成效果平平无奇。
artlist:视频创作素材网站,提供多种素材及语音合成功能用于视频旁白,素材质量高,旁白语音效果独特,但仅支持英文。
boomy:可合成 20 秒左右简单乐器音作素材。
music-fx:谷歌 AI 实验室工具,能生成 30 秒无人声纯音乐,可设定循环模式。
通义:部分模块不算音乐生成,而是视频转绘和对口型,面向普通用户,质量不错。
CosyVoice:开源软件,可免训练快速复制声音音色,提供多种功能模式,但只能生成说话语音。
Sovits:可用于换音色唱歌,需训练模型,流程复杂,使用门槛高,但音色模仿质量高。
AudioCraft:包含 MusicGen 和 AudioGen,有开源项目可下载安装或官网试用,效果较一般。


















 692
692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









