







前言
场景化数据需求是激活数据价值的唯一通道,只有重塑数据要素架构,才能释放数据的生产力。多源、异构、冗余、隐匿是目前数据的现状,如何将数据快速价值化是数据从业人员急需解决的问题。
数由科技主张数据处理的平民化,倡导数据的自由应用。通过搭建低代码的数据科学平台,实现增强性的数据流动,以求达到数据快速价值化的能力。数据科学平台实现了非结构化数据(“平民化”非结构数据处理)和半结构化数据(“平民化”半结构数据处理)的低代码化快速处理,以帮助更多的数据从业者处理和分析数据。
在项目实践过程中,数据科学平台已经具备几十种数据格式的接入,并且在此时间内已经结合项目开发出针对各种场景化数据需求的处理能力。本篇文章将聚焦于网络安全领域中的威胁情报获取,提取公开渠道的IOC数据情报来提升组织的威胁情报能力。
一、威胁情报现状
在当前的市场上,众多的安全厂商或者安全服务商通过互联网来共享威胁情报。各个需求组织一般通过订阅的方式来获取服务商提供的威胁情报,但提供的方式多数需要以购买或者独立订阅的方式才能获取。
而公开的威胁情报数据大多以报告、图片、网页等形式存在与网络中,对于各个需求组织来说,如果将这些数据快速转化为有价值的情报数据,一方面可以弥补不同服务商间的情报数据差距,快速补齐威胁情报数据,另一方面也节省一部分开支。
在国内外来看,这些公开的渠道包括服务商的网站、技术论坛、微信公众号、技术网站、Twitter、INS等,这些情报的表征形式包括HTML、PDF、图片等数据格式。
二、IOC的特征
威胁情报中最重要的就是指征数据就是妥协的指标(Indicators of Compromise, IOC),简单来说攻击事件发生后,被捕捉到的攻击特征信息。威胁情报的有效性取决于情报数据的广度和深度,主流的服务商会及时更新和同步最新的威胁分析过程,并提供相关的IOC数据,这些数据分散在不同的公众号、网页、博客、微博等平台上。而我们的目标就是收集和汇聚这些数据,转化为一种情报资源。IOC的具体类型包括:
1.IP
2.域名
3.URL
4.MD5
5.注册文件
6.下载地址
其中前四个为目前主流的IOC指标共享标准,也是目前各个服务商提供的最多和最有价值的数据。
三、IOC的提取
对于IOC的数据处理思路一般来说包括数据的接入、数据转化、特征数据抽取、格式转化、结果输出几个过程。数据接入和转化面临的主要问题就是不同数据格式,如对HTML文件的读取、图片内容的识别、PDF内容的转化和识别等。特征数据抽取面临的主要问题是如何准确识别IP、域名、URL、MD5、注册文件、下载地址,并且要确保数据的完整性以及格式的准确性,如在图片或者PDF中嵌入的空格或者特殊符号等。
以某平台发布的攻击事件分析为例,来提取下有价值的IOC数据。如下图所示:

针对本次攻击相关的分析到的IOC数据会在文中有公开,我们需要提取的就是这些关键信息。

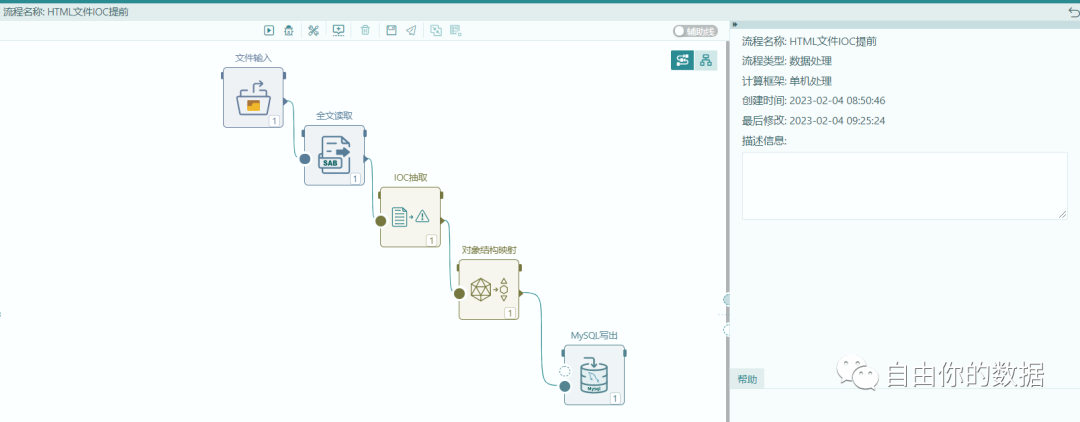
首先需要将需要提取的目标转化为离线的html文件,通过导入的方式导入到本地处理平台,如下图所示。
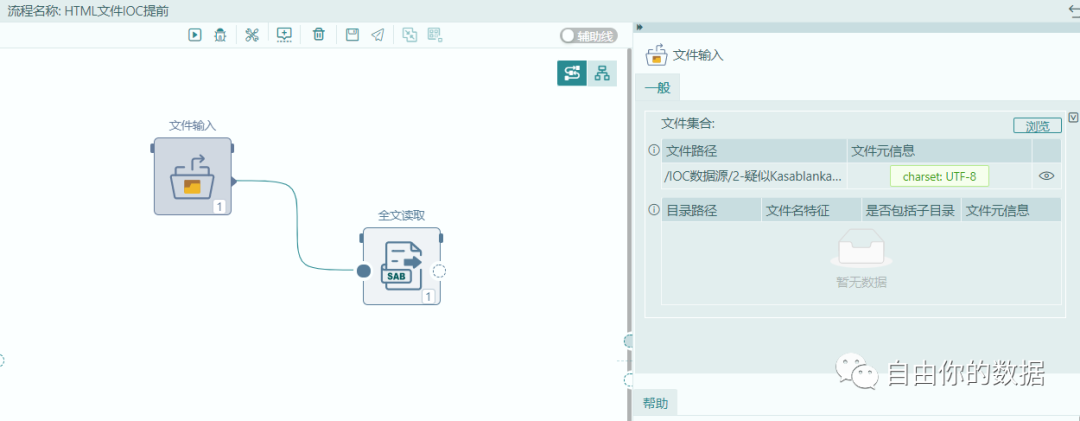
文件输入的类型不限制格式,并且可以扩展输入的格式。
然后通过全文读取的方式进行内容提取和分类,这里需要说明的是,我们已经将对文件内容识别和分类的能力封装在特定的工具算子里面,直接通过辅助线的方式,建立自动的数据读取过程,如下图所示:
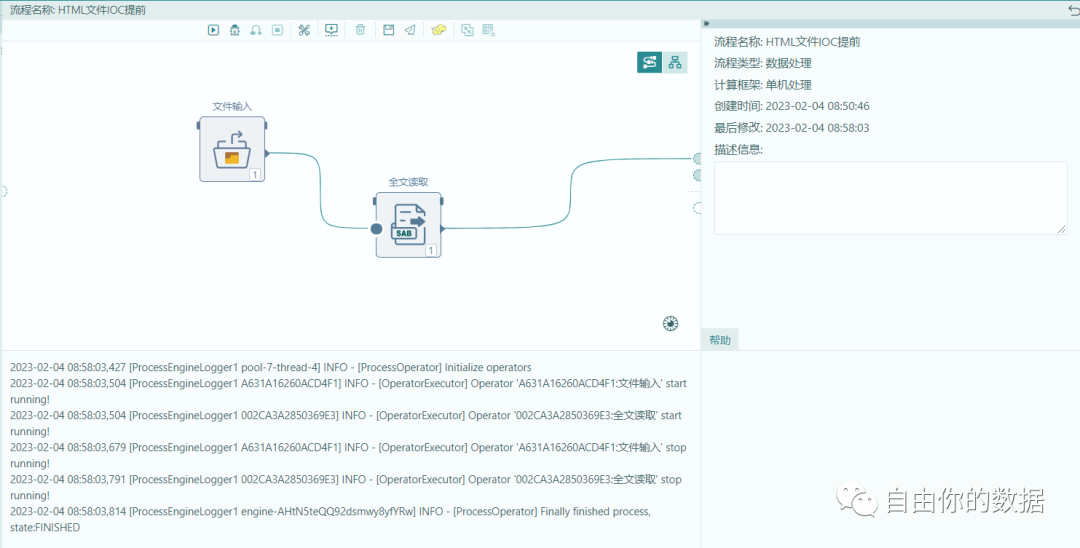
在数据处理过程中,可以按照步骤实现过程化的调试,以上过程是对内容抽取的过程调试,可以正常读取源文件。
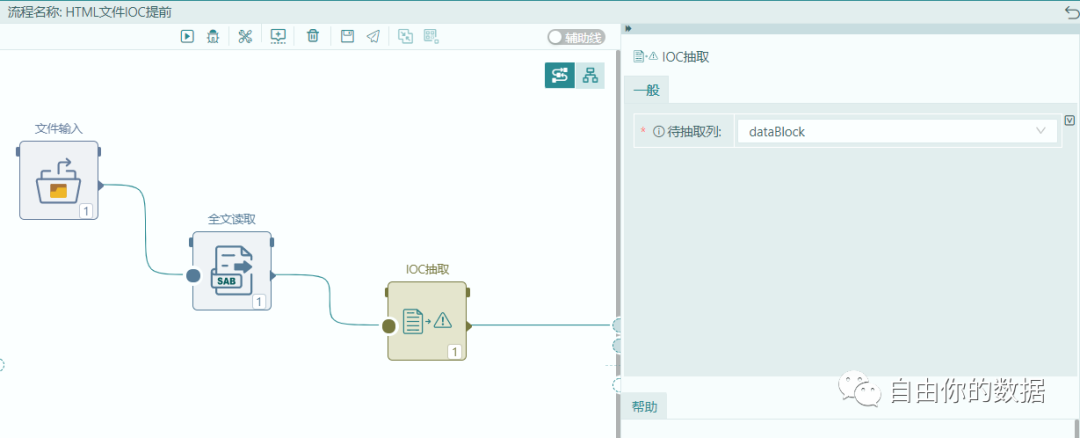
对于IOC的提取,使用封装好的IOC抽取算子来处理,处理完成后将IOC数据会转化为结构化的数据,并通过对象结构映射转化结构化的数据,以映射到目标输出格式。
IOC的抽取结果通过列名格式为:columnName+"_iocs"的列输出,输出结构如下:
{
String iocType; // ioc的类型
String ioc; // ioc
int offset; // 时间在文本串中的位置
}
对于对象结构映射的映射规则,将对象的结构映射为以表格形式表达的结构化结构。数据对象一般采用半结构化描述方式,允许内嵌属性、子对象及数组。当进行对象的结构化映射时,允许将不同子对象内的属性信息映射为一层,即不管对象的结构的子对象嵌套多少层,最终都可被映射为一层,实现对象数据的结构化表达。若对象中内嵌数组对象,且被视为一个数据集,允许将数组中的每个对象映射为结果集的一行进行输出。但该类映射每次只允许映射出一种集合结构。即,若对象中存在两种或两种以上没有嵌套关系的数组,则无法通过一次结构化映射同时输出。
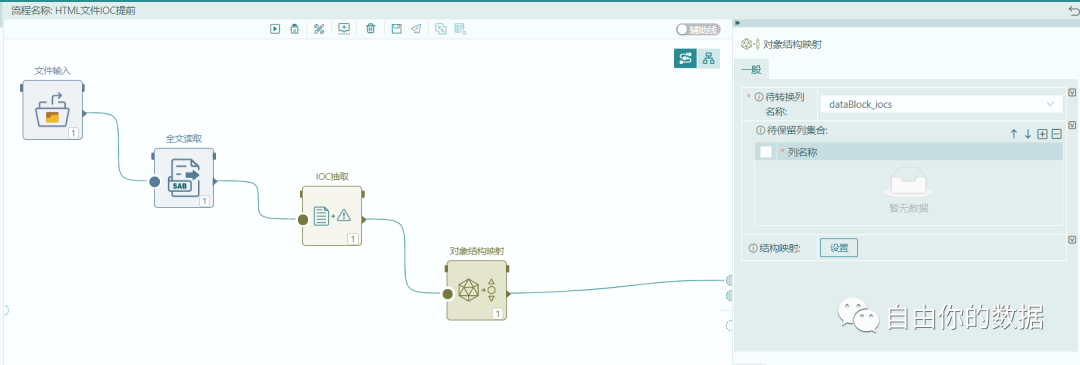
通过对象结构映射将按照已经定义的dataBlock_iocs的格式进行结果输出(注:IOC的格式和命名可以通过设置自行定义)。结果输出的格式如下:
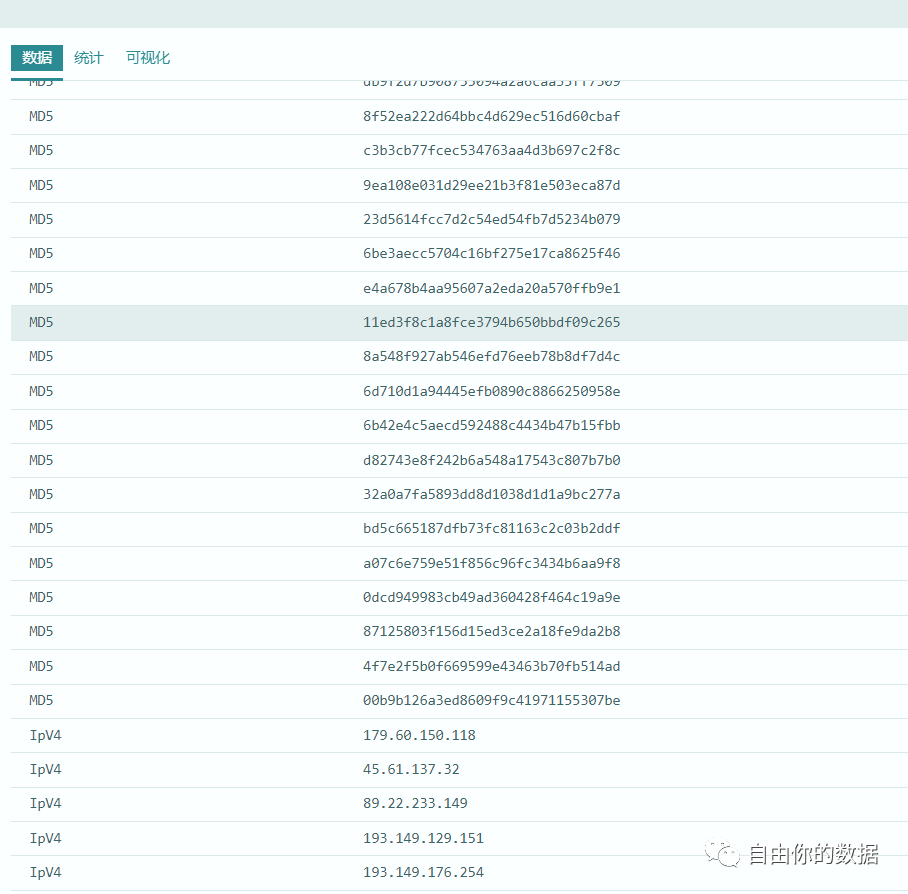
IOC结果的结果输出可以包括多种形式,若以文件形式写出的,包括excel、csv、xml、json、Avro、ProtoBUF、commonWriter等。若以数据库形式写出的,包括Hive、SQLserver、达梦、ES、Mysql、MongoDB等十几种数据库格式。

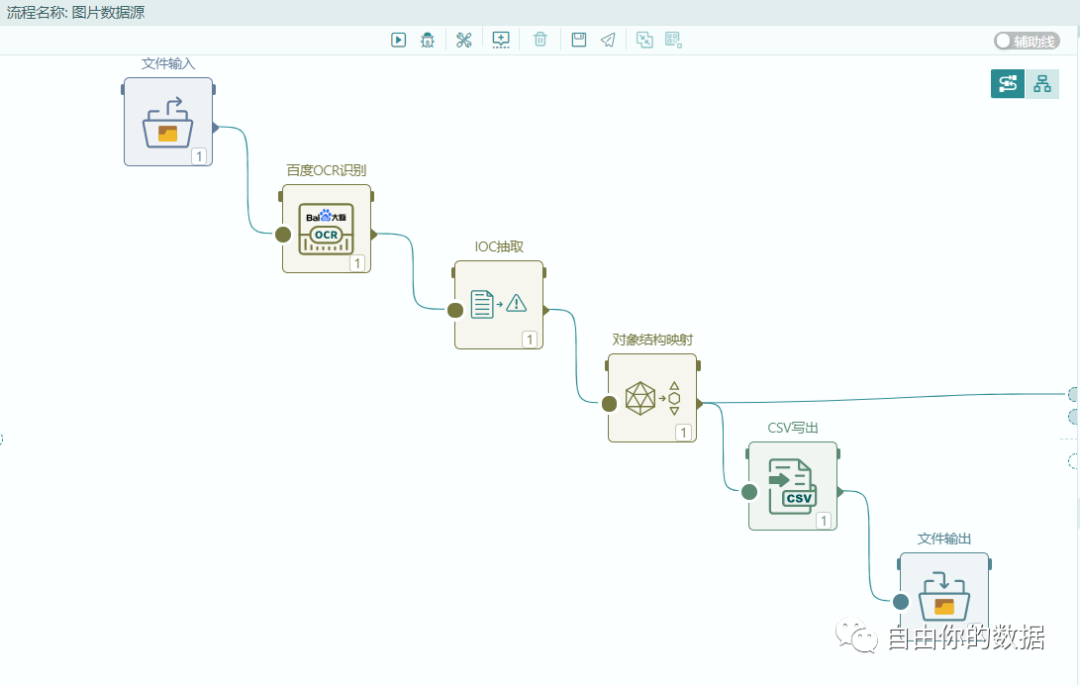
对于不能转化为html的数据源,可以通过截图获取相关的图片,通过提取图片中的数据,完成IOC获取。图片数据源的处理流程如下:
以上是对于互联网侧公开的源数据进行提取、加工、处理的整个处理过程,可以批量处理含有IOC数据的HTML、图片、PDF等文件。同时可以对该过程进行保存,在使用过程中导入相应的源数据就可以实现快速处理。
数由科技团队提供的数据科学平台中的每个工具算子具备可视化编辑的能力,可以通过配置相应的工具算子来达到输出格式的设计,大大提升了威胁情报管理人员从公开渠道获取IOC数据的能力。
写在最后
万物数字化的时代,唯有平民化,才能重塑数据价值。数由科技将陆续推出场景化数据的处理思路,来践行数据的平民化之路,欢迎各位提出场景化数据处理需求。















 3427
3427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









