






在之前的案例视频中我们演示了使用Milvus向量数据库和腾讯向量数据库实现RAG的场景应用。今天我们演示下利用ES的向量数据存储能力来实现RAG,包括三个部分:连接ES数据库并建表;数据写入ES向量数据库流程;问答对话流程。具体操作可参照下面的视频:
《玩转数据之使用ElasticSearch搭建RAG》 https://www.bilibili.com/video/BV1mZ421E7ki/
https://www.bilibili.com/video/BV1mZ421E7ki/
【连接ES数据库并建表】
这里我们没有展示连接ES数据库的过程,直接使用已经连接创建的ES7数据库03-es,相关操作可查看已发布的信息。
进入数据库操作页面,点
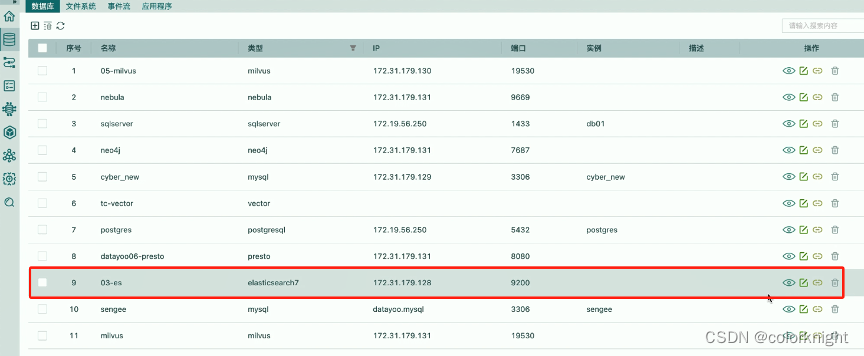
新建一个支持向量数据的数据表knnword3,分别添加两个字段:
- 名称=text,类型=keyword;
- 名称=embeddings,类型=Dense_vector,dims=1024,intex=true,similarity=I2_norm(相似度算法)。
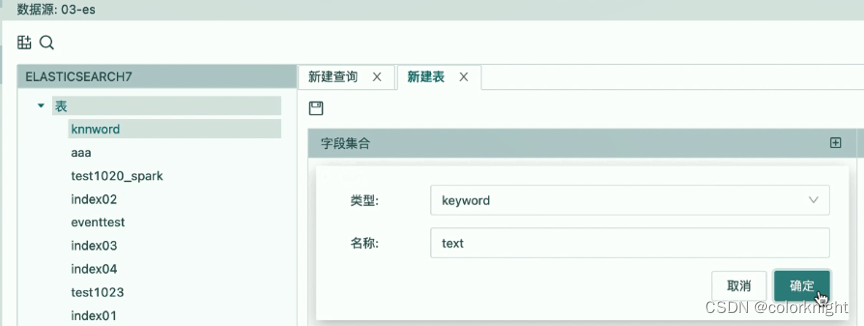
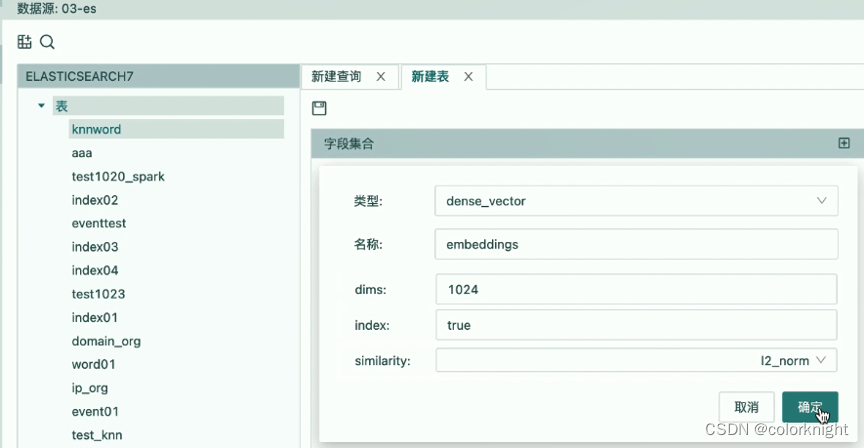 将dims设置为1024是因为Lucene最大支持长度是1024,若超过1024的长度会引发插入数据错误。
将dims设置为1024是因为Lucene最大支持长度是1024,若超过1024的长度会引发插入数据错误。

这样将向量数据表完成后,就可以在流程中使用了。
【数据写入ES向量数据库流程示例】
这里我们将之前用Milvus数据库的流程示例进行改造,将Milvus的向量数据库替换为ES数据库。整个流程的其他创建过程可参考如下视频:
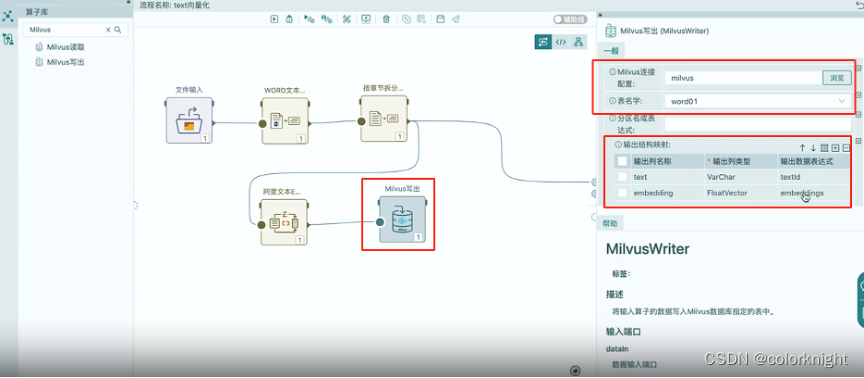
上图是用Milvus数据库实现的,现在将其替换为ES算子,如下
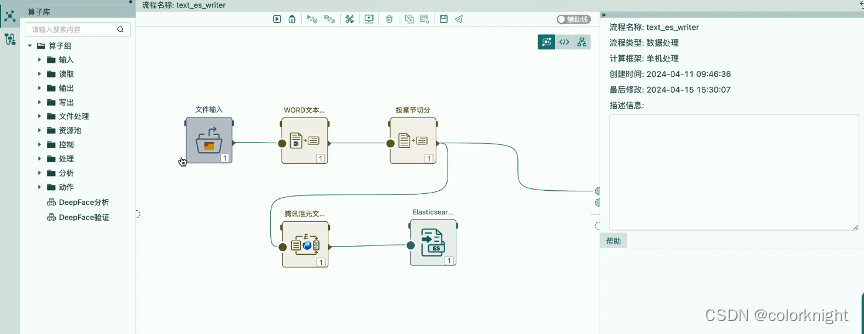
选择ES写出算子替换掉Milvus写出算子后,需要配置下ES数据表的信息,如下:
- es连接配置:03-es;
- 索引名:keyword3;
- 表结构:embeddings=embeddings,text=textId。
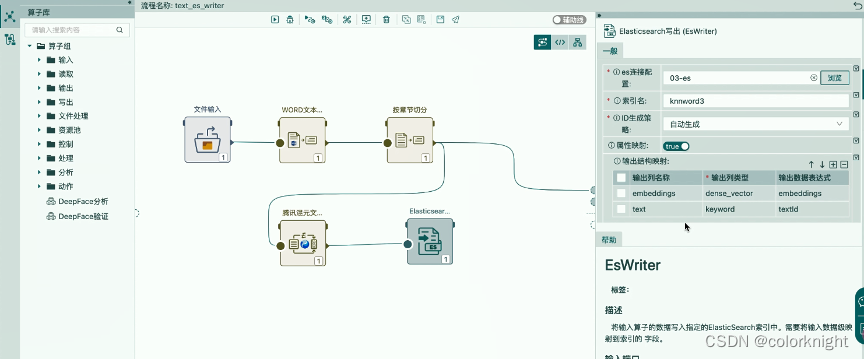
保存并执行流程,查看效果。
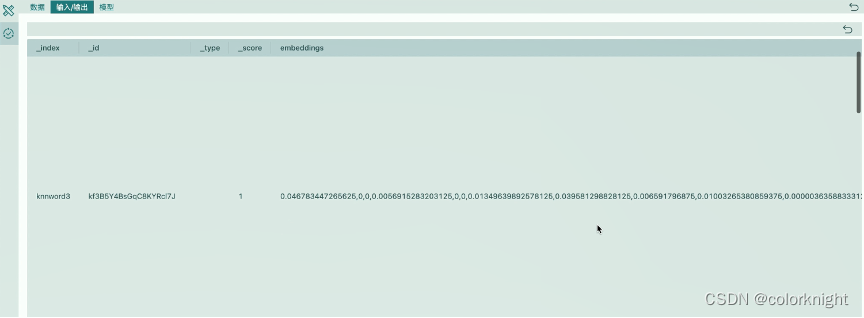 数据处理完成,可以看到我们已经把这个数据插到了向量库中,然后我们基于插入的这些数据进行下面对话示例的演示。
数据处理完成,可以看到我们已经把这个数据插到了向量库中,然后我们基于插入的这些数据进行下面对话示例的演示。
对话应答示例
关于对话应答的示例也请参照如下文章进行流程的设计。
HuggingFists-低代码玩转LLMRAG(2) Query
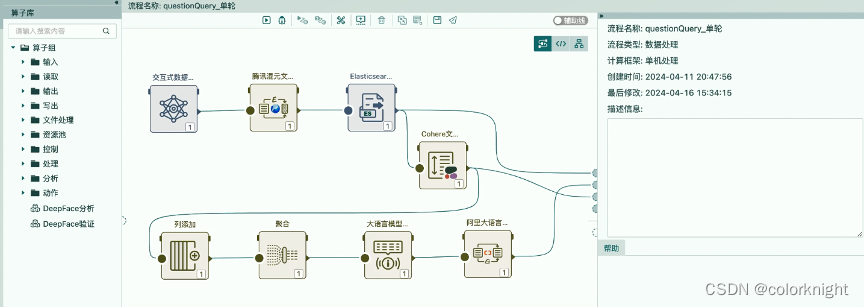
在整个流程中,会用到如下的算子:
- 交互式数据算子用来接受输入的问题,绑定一个真实的问题;
- 混元文本嵌入算子用于将文本转换为向量数据并关联ES数据表中数据。
- es读取算子用于完成基于输入的向量问题检索向量表。
- Rerank算子用于对原来数据的重排序
- 列添加、聚合算子主要完成数据的整合。
- 大语言提示模型实现提示模版的输出。
- 阿里大语言模型完成问题的应答,
整个流程中我们使用了腾讯的嵌入模型和阿里大语言模型,或者用混元大语言模型也可以。
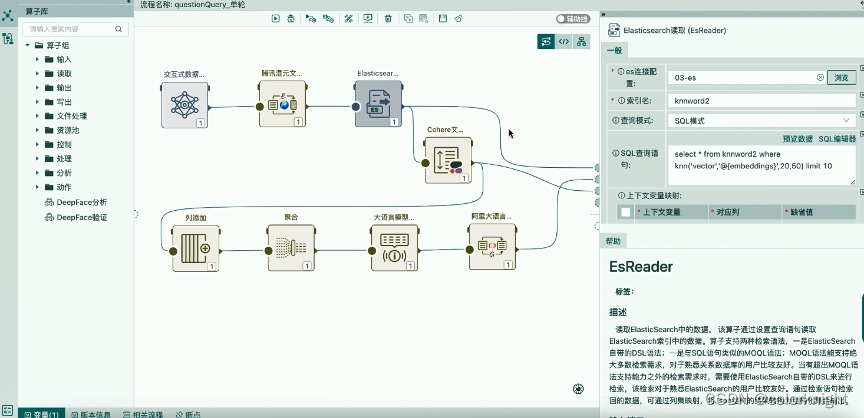
这里需要修改ES的连接配置信息
- es连接配置:03-es;
- 索引名:knnword3;
- 查询模式:SQL模式;
- SQL查询语句:select * from hnnword3 where knn(‘embedding ’,‘@(embeddings)’,20,50) limit 10
配置完成后,先运行下看下效果,
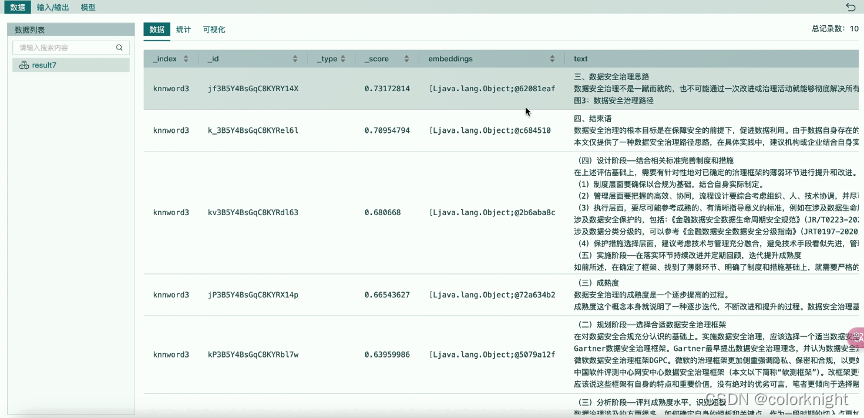
可以看出能够很好回答提示问题的数据排在第五个,假设后续语料增多,后续可能排位更低,所以,设计了这个rerank算子(重排算子)
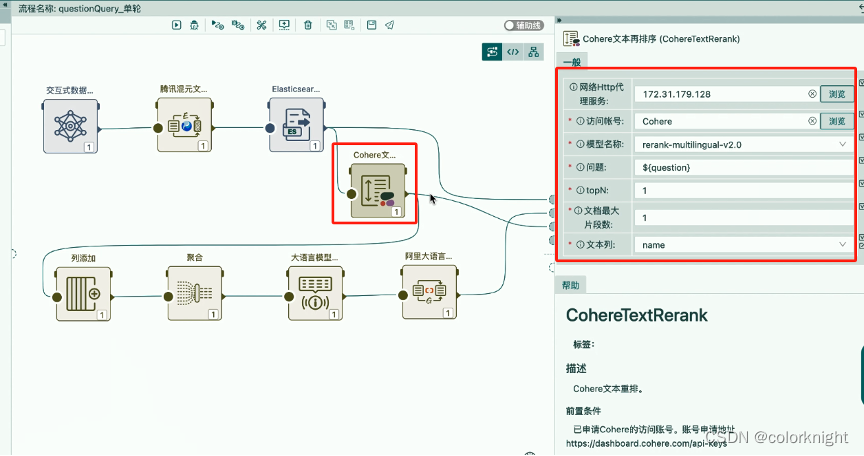
Reank算子的主要作用是语义的重排序,使其能够将跟问题最相关的语料筛选出来。加入这个算子后,重新运行下流程。发现能够准备回答问题的语料可以被筛选出来,通过Rerank算子的重新排序,精准的找到适合回答问题的语料。
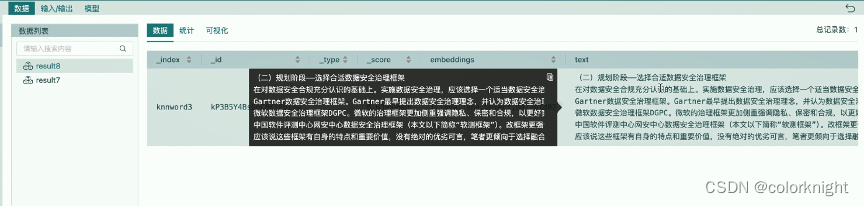
最后我们整体运行下该流程,
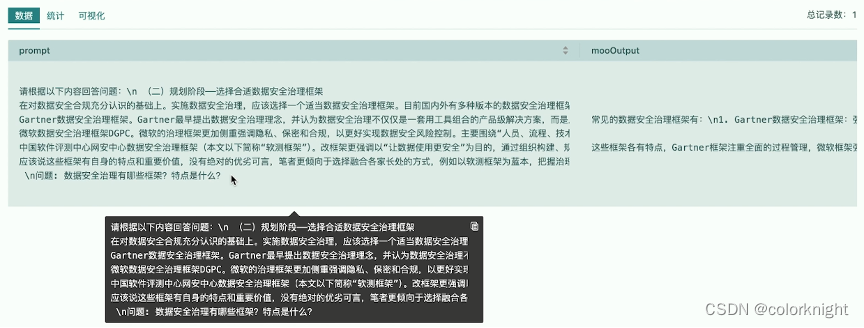
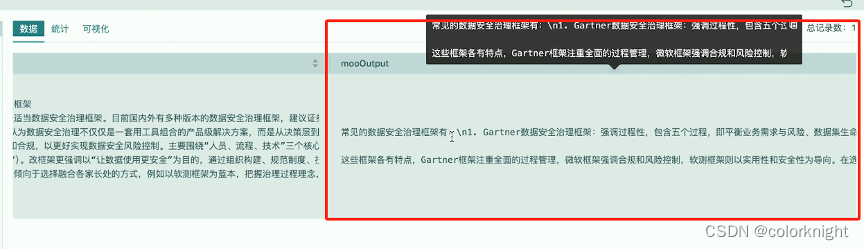
从输出结果来看,当前问题的应答输出与我们的几次测试,基本上这结论都是一致的。
以上就是基于ES向量数据库来实现检索增强生成应用的示例,欢迎下载HuggingFists试用。下载地址如下:
【Linux版】
Github:https://github.com/Datayoo/HuggingFists
百度网盘:https://pan.baidu.com/s/1zV_ScCtLgFQSYEb0wLmXIQ?pwd=2024
【windows版】
Github: https://github.com/Datayoo/HuggingFists4Win/tree/main
百度网盘:百度网盘 请输入提取码
【Mac版】
百度网盘:https://pan.baidu.com/s/12WxZ-2GgMtbQeP7AcmsyHg?pwd=2024
【补充算子】
GitHub: https://github.com/Datayoo/Operators
百度网盘:https://pan.baidu.com/s/1iqX0f8xzCXMWVDA7eaqH6Q?pwd=2024
如果使用过程中遇到问题,可加入我们的交流群:


















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









