







 文章介绍了DDPG算法,一种基于actor-critic模型的深度强化学习方法,它在连续动作空间中引入了BatchNorm等技术以提升训练稳定性。与DQN和传统的离散动作空间方法相比,DDPG在处理高维连续空间问题上更具优势,并且与物理规划算法进行了性能比较。
文章介绍了DDPG算法,一种基于actor-critic模型的深度强化学习方法,它在连续动作空间中引入了BatchNorm等技术以提升训练稳定性。与DQN和传统的离散动作空间方法相比,DDPG在处理高维连续空间问题上更具优势,并且与物理规划算法进行了性能比较。
DDPG
Deep Deterministic Policy Gradient,基于actor-critic模型提出了一个有效的value based连续型空间的RL算法,引入了一些帮助训练稳定的技术。
基础:DQN,Batchnormm,Discretize,微积分
-
background
DQN改进的推广
Policy based方法(TRPO)已经在action space取得突破
传统discretize action space无法拓展到高维空间,阻碍了value based在连续型空间发展
Ornstein-Uhhlenbeck process(OUN),是一种回归均值的随机过程
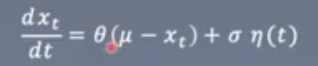
η(t)是白噪声white noise
-
核心
推广了DQN到连续action space
使用同样的网络结构和超参数,这个agent能robust的学习解决20多个环境
该算法学习到的策略接近甚至超过知道物理模型的planing算法
-
DDPG and DQN
-
DDPG:replay buffer,critic Q网络(s,a|θ^Q) and actor μ(s|θ^μ) 参数: θ^Q and θ^μ、目标Q网络
DQN:replay buffer 、Q function with random weights θ、目标Q网络
-
DDPG:在连续性act
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









