







Structure Preserving Object Tracking
碎碎念
一直在博客上获取知识,一年多的研究僧学习让我从各位博主处学到了很多关于多目标追踪、粒子滤波等算法,正所谓投桃报李,这将是我的第一篇,之后还会和大家分享粒子滤波用于相似外形多目标追踪方面的心得,如行人、斑马鱼、蚂蚁等。
下面说说这篇文章:
文章发表于2013年的CVPR ,号称用model-free的方法追踪任何目标,但是读后发现,其还是具有很大局限性的,大家细心体会。其方法还是基于的Tracking by detection 的框架:
其中detection 部分使用参考文献【7】中2005 CVPR 的经典之作HOG +SVM 行人检测算法实现的,大家可以参考博客
http://blog.csdn.net/masibuaa/article/details/14056807
http://blog.sina.com.cn/s/blog_60e6e3d50101bkpn.html
前一篇写的是这篇文章很好的翻译。
tracking 部分:作者使用structure preserving 即结构保留的方法,个人感觉器局限性就在这里,器借鉴参考文献【8】的方法,其是一个单目标的方法,参考博客:
http://zhangliliang.com/2014/09/01/paper-note-dpm/
还有直接用必应搜一下可以找到作者的英文PPT 解释的较为清楚。
学习前面两部分知识之后就可以去理解这篇文章了,吐槽一下,可能之前先验知识比较少,直接读这类文章真的很困难,公式没有说明,看了大量参考文献才理解。下面是我对这篇文章的翻译加自己的一些体会,到实验部分为止。解释部分用%标注。
- Abstract
模型自由追踪器可以基于对被追踪目标的一个矩形框注释追踪任何目标。在如今对相似外形的目标进行多目标追踪依旧面临巨大挑战时,提高对模型自由追踪器的性能具有很重要的意义。本文中我们通过目标间的空间约束建立一个基于检测-追踪的模型自由追踪器来解决这个难题。空间约束通过使用一个在线的SVM分类算法学习目标的检测值。实验证明我们取得了重大的性能改进。我们还展示SPOT可以通过同时追踪单目标的不同部位,提高对单目标追踪的性能。
- Introduction
目标追踪是计算机视觉的一个重要应用领域。对于追踪特定的目标已经取得了重大的研究成果,(如,人脸[22],人类[11],刚体[15]),但追踪全部对象依旧困难。而人工标定的方法即费时又费力,使得提高模型自由追踪器的性能具有重要的意义[2,12]。在模型自由追踪中我们在第一帧中用矩形框手动标定目标位置,在之后的视频中自动追踪手动标定的目标。研发模型自由追踪器是一个重大的挑战,原因如下:
(1)被追踪目标仅仅提供很少的信息。
(2)因为一开始矩形框只是近似区分目标和背景,所以这种提供的目标是模糊不清的。
(3)目标外形在追踪整个视频中可能会完全改变。
大多是追踪系统包含一下三个方面:
(1)一个外观模型预测似然函数–目标在特定位置在观察图像上的外观。
(2)一个位置模型预测先验概率–目标可能存在的位置。
(3)一个全局收索方法找出目标最可能的位置。
在我们的模型自由追踪器中,外观模型是用HOG特征产生的【7】。位置模型基于目标的相对位置,搜索策略是变化窗口的全局搜索。
在许多应用中追踪多个目标是很有意义的。一个简单的追踪多个的方法是同时应用多个简单的模型自由追踪器。在本文中,我们认为这种方法并不是最好的,因为其没有应用目标间的空间限制。例如:花和风的运动方向相同,车辆朝着一个方向行驶,当相机抖动时所有目标朝着一个方向抖动。我们表明在模型自由追踪器中加入目标间的空间限制是有意义的,这种结构保留目标追踪器是基于目标间空间限制研发的,空间限制是通过一个形象的结构框架(pictorial-structures framework)【8】。我们使用一个SVM分类器训练个体目标分类器和结构限制。实验表明空间约束极大的提高的SPOT的性能。SPOT在使相机移动,目标剧烈运动,目标外形变化和遮挡具有良好的表现,并且在单目标追踪也有很好的表现。
总之,我们的主要贡献在于:(1)将目标间的空间约束合并到模型自由追踪器中改善了多目标追踪的性能。(2)通过对单目标部分应用模型自由追踪器提高的单目标追踪的性能。相关工作在第二部分中。第三部分介绍我们的追踪器。第四部分是实验结果,第五部分是结论。
- 2、Related Work
模型自由追踪器可以被分为两类,(1)目标自身的外观模型【20】(2)目标和背景的外观模型【2,9,12】。现在研究结果建议使用后者,训练一种区分背景和目标的分类器胜过使用前者。这种理论被文献【17】支持。在本文中我们使用一种有识别能力的目标外观模型。
大多数模型自由追踪器试图找到被追踪目标的个体特征:之前研究中曾使用积分直方图【1】,子空间学习【20】,稀疏表达【16】,局部二值模式【12】。在本文中我们使用HOG特征。
现在模型自由追踪器依旧关注于找到一种方法将目标从背景中区分出来。之前的方法有boosting[9],随机森林[12],多重事例学习[2],组织输出学习预测目标转移[10]。我们的追踪器和这些方法相同点是在线更新目标的外观模型。我们追踪器和这些方法不同的地方在于,其使用一个学习器去确定目标或者目标部分的参数;例如,一个在线结构SVM[3].
我们目的是发展一种模型自由追踪器可以只应用一个简单的注释而不应用其他先验知识去追踪任意的目标。至今为止,前无古人。
- 3、Structure-Preserving Object Tracker
我们的追踪器是以Dalal-Triggs检测器为基础建立的[7],其使用HOG特征描述图片同时使用SVM分类器提取目标。HOG在8*8像素点的图片中测量图像梯度的大小和方向(无符号)。随后,在block中应用对比度归一化,每个block中包含4个cell。对所有block中的直方图应用L2-norm标准归一化。HOG特征的优点如下:
1)他们比仅仅的垂直或者水平更有方向性。
2)他们将很小的图像区域联合在一起。
3)当光照条件变化时他们较为稳定。
这些优点使得HOG特征对空间位置变化更加敏感[7],这一点很重要,因为被鉴定的目标位置将被用于更新滤波器参数:小的空间误差总会变多,从而使得追踪器的漂移。而且,高效率的使用可以在高帧率中提取HOG特征。
我们使用bounding box表示目标个体 i∈V(V是我们追踪的目标),用Bi={Xi,Wi,Hi}表示矩形框,其中Xi表示矩形中心位置(x,y),Wi和Hi表示矩形宽度和高度,并且宽度和高度数值是固定的。
Step1:从图片I中的矩形框内获取HOG特征向量ф(I;Bi)。
Step2:随后,我们对所有目标定义图G=(V,E),其目的是确定目标间的形变参数e_ij∈E。在图模型中的边界被看作是具有行变量的,用这种形变参数表示目标间的空间约束。
Step3:下一步,我们定义参数C={B1,..BV}的得分规则,其由两部分组成:(1)外观得分,图像特征与目标分类器权重的相似性。(2)形变得分,被追踪目标间的形状压缩或者伸长的弹性,公式如下:
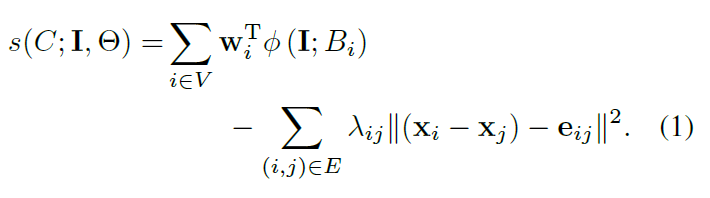
%%这个公式第一部分即滤波器得分,后面是形变损失。eij应该是根据第一帧手动标定的相对位置确定的相对位置关系。
1.ω_i是目标i的HOG特征的线性权重。
2.C={B1,..BV},ф(I;Bi) 图片I中的矩形框内获取HOG特征向量
3.e_ij是表示目标i和目标j之间弹性的方向和大小的向量。》
4.⊝表示所有参数:⊝={ω_1 〖…ω〗_v,e_1…e_E}。
5.λ_ij是一个超级参数,因为我们想学习e_ij的弹性系数。例如,我们设置,∀i,j : λ_ij=λ。
超级参数λ决定外观和形变之间的权衡分数。我们使用Platt scaling[19]去实现配置似然函数的结构分数。
推理:在给出模型参数的基础上,找到和被追踪目标最相似的参数相当于在C的基础上最大化公式(1)。因为需要搜索以指数增长的参数,所以这个最大化过程是困难的,但是对于树形结构的图G,可以使用动态的参数去执行最大化过程,每部分是线性的,如文献【8】。
学习:就如其他自由模型追踪器一样[2,9,12],我们使用之前的图片作为正样本训练模型。在观测图片I并且推理目标参数C(通过最大化公式1得到)之后,我们执行一个参数更新参数C更新,目的在于减少SVM分类器结构l[21]。
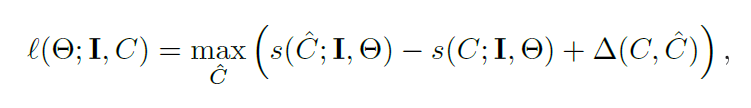
这里 被定义如下:
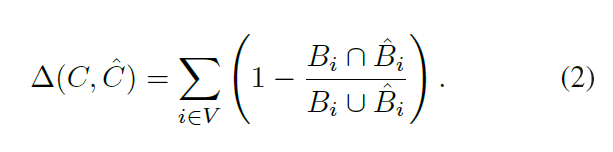
%%这个公式让我理解了好久,主要还是因为之前没有接触过相关知识,从公式(2)可以这样理解:以知一个矩形框,再选一个矩形框.后面公式可理解为当两个矩形框重叠时其值为0,当完全分离时其值为1,也即奖励两个矩形框完全分开。然后上面的公式用同样的方法理解,当两个矩形框重叠时HOG特征相同其值为0,不重叠时HOG特征才有差异,而第二是根据公式优化得到的,也即是当前图像中当前滤波的可选矩形框的最大值,无论前一个矩形框选什么第一项得到的都是一个小于零的负数,并且最大值为重叠时的零。整个公式可表示为:第一项和第二项是相互矛盾的,也即要选一个和当前最优框不重叠的又最相似的样本,也就是找一个相当于hard example 的负样本,也就是支持向量,这样哪怕每一帧只找到一个这样的难例,也可以有效更新SVM分类器的参数了。
通过像素点测量两个矩形框间的交叉部分,减少的部分可以写为:
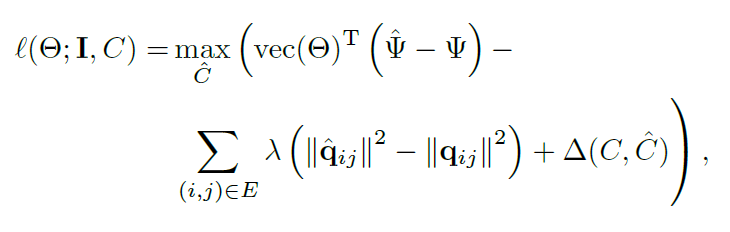
vec(.)表示在一个列向量中连接所有参数
q_ij=X_i 〖-X〗_j。这些方程是通过⊝的最大化过程得到的,丢失方程是凸函数。
SVM结构丢失的梯度可以相当于 通过以下公式给出。
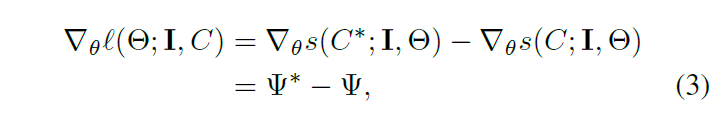
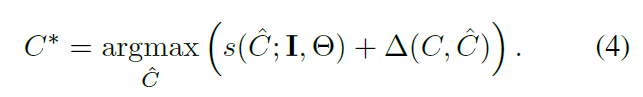
可以通过以下方法高效的计算 :(1)对每一个目标滤波器增加一个当前位置矩形框和检测矩形框像素的重叠率。(2)使用一个是公式1最大化推断过程一个样的过程。我们使用一个消极的算法执行参数更新【5】,参数更行公式:
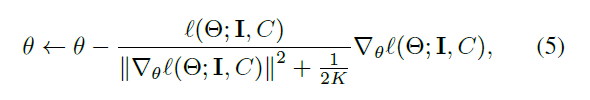
其中K属于0到正无穷,是一个超级参数控制消极参数更新率。
初始化:在第一帧中不和标定矩形框重叠的部分选择50个负样本,用负样本和正样本训练SVM分类器。初始化参数边界弹性参数eij表示
图形结构:剩下的问题是我们怎么确定图G的结构,例如,我们如何知道哪些目标间的边界和相互连接的。理想的情况下,我们应该使用一个全联通图,但是这样会使推断变得困难。因此我们使用两种方法在目标间建立两种近似树。
1)一个星型模型的【8】。
2)最小生成树模型【24】。
星形模型中使用一个位于所有目标中心的虚拟目标连接所有被追踪目标。例如,目标之间没有直接联系,这样就需要稍微改写记分方程:
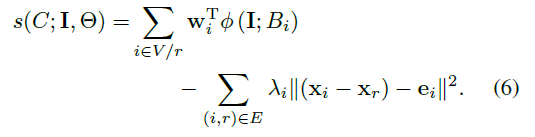
最小生成树模型通过第一帧标定的目标间的相对位置进行构造。它通过搜索树中所有可能的完全连接的树模型构造的:















 1402
1402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









