







 本文深入探讨了OpenMP并行编程的核心概念和技术细节,包括其与OpenMPI的区别、并行区域构造、数据依赖性处理、线程管理和调度策略等。通过具体指令和实例,解析了工作共享、数据范围属性、运行时库例程等内容。
本文深入探讨了OpenMP并行编程的核心概念和技术细节,包括其与OpenMPI的区别、并行区域构造、数据依赖性处理、线程管理和调度策略等。通过具体指令和实例,解析了工作共享、数据范围属性、运行时库例程等内容。
OpenMP Outlin

OpenMP不同于OpenMPI
OpenMPI: 是一个MPI的library
注意data dependence
平行使用thread
Parallel Region Construct

Compiler通过Pragma 识别出这是一个OpenMP创建线程的板块
parallel 可以搭配do 或者for ; do 和for不能同时使用
Optional
怎么使用
data
clause 告诉Compile 如何确定 各种变量
OpenMP Directives

Parallel
并行区域必须是不跨越多个例程或代码文件的结构化块
在并行区域中分支(转到)是非法的,但是您可以在并行区域中调用其他函数
不能 jump/goto 到其他部分 ,不能跳出这个block(代码块)
但是可以调用其他函数,不太建议(call 到最后,flow会变得很乱 )
最好执行完,join回block之后

1.if 如果是false 只需要comfose成一个threas 视derection不存在
2.true 时再来判断
3.first : num_threads(n)
4.如果不写, 在程序码中call library function: omp_set_num_threads()
肯定相同,避免出错(设定default值)
(在进入parallel region 之前,调用)
优点:threads是固定的,并不需要每次都call它,在程序码一开始call omp_set_num_threads() ,这个是默认的值,每个parallel region都将默认
5.都不写时:看 OMP_NUM_THREADS Compiler查看系统的环境变数
6.最终,默认询问有多少CPUS

Parallel region 嵌套

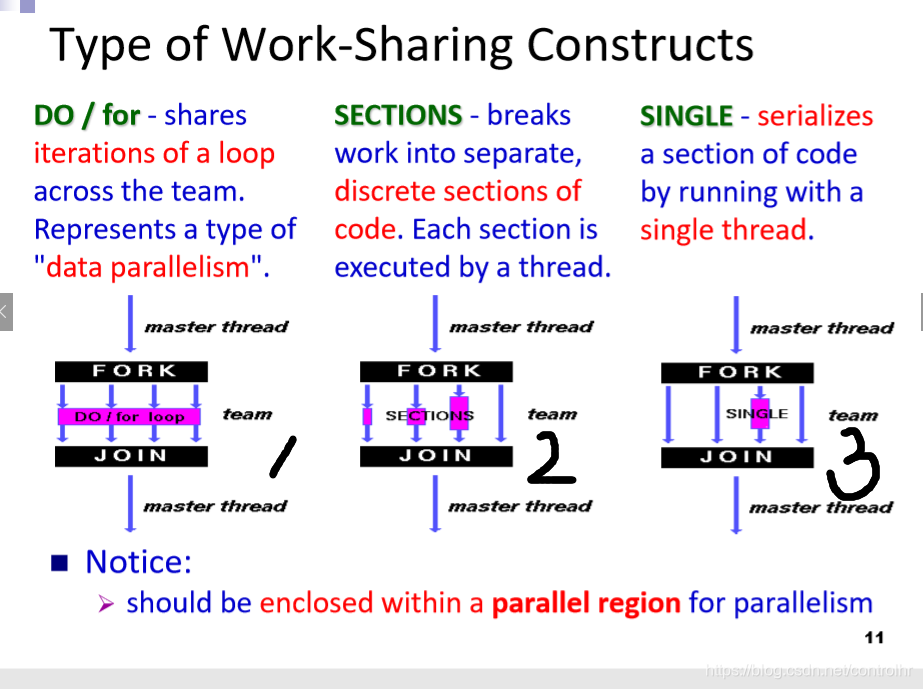
Working_Sharing Construct
定义: 1.工作共享结构将封闭代码区域的执行划分为遇到该代码区域的线程
2.工作共享结构不启动新线程(所以使用parallel for 只有在parallel(已经形成线程组的情况下),才能Working_Sharing Construct)
3.在进入工作共享结构时没有隐含的障碍,但是在工作共享结构的末尾存在隐含的障碍
(join(),是个线程block到同一时间点)
section:可以set不同的function, 在call的这个水平去做平行,一个section就是一个call,分配给一个threads
将各个部分的section一 一写出来,每个section 不会被重复做
SINGLE :是section的特例,只会执行section中的一个
用途:解决同步化的问题:做I/O (会出现 同步化 的问题 所以使用SINGLE)
1.DO/FOR
1.nowait: 空闲进程不必等待,继续执行parallel rection中剩下的代码
2.schedule: 分配线程的算法
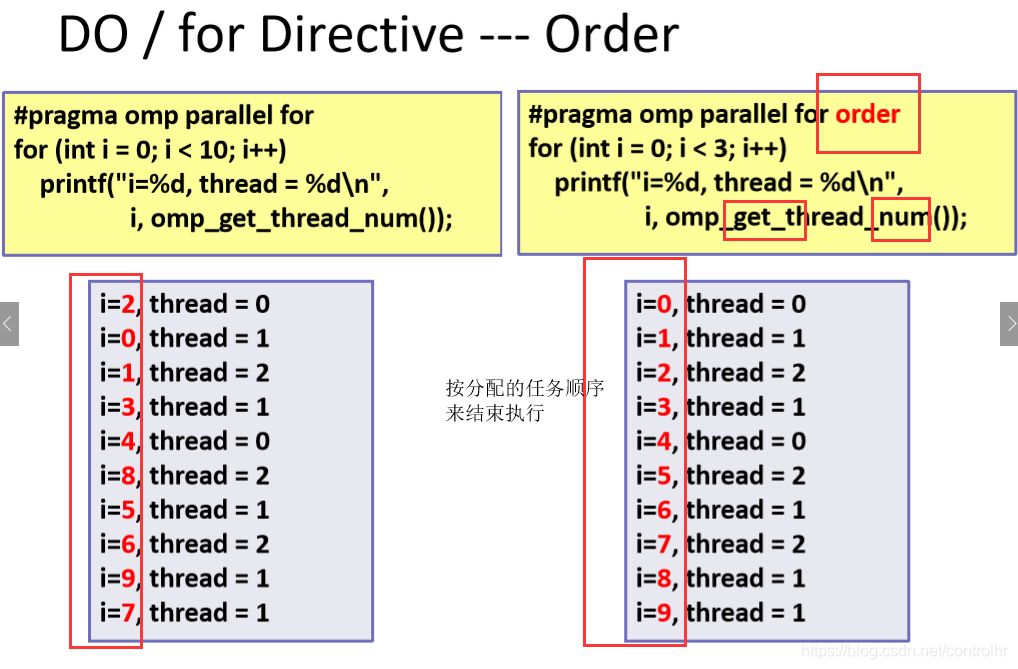
3. order:线程以一定的顺序结束(开始顺序不受影响,结束顺序与serials core相同),order会降低程序的并行程度
4. collapse: 用在nested loop(嵌套循环)上,指定嵌套循环中应将多少个循环折叠成一个大的迭代空间并根据schedule子句进行划分(变成一个一维顺序队列)
DO/for Directive

适用情况:
STATIC: 项目的数量很banlance 但是不同task间执行时间大相径庭(会Blocking在执行时间最长的那个thread) 优点: 相当于一开始就对tasks进行了数量上均分,所以schedule 很简单。适用于各task之间差距不大,且总数不小
Dynamic: (动态的): 与STATIC恰好相反,一次分配一个task,他实现了threads之间执行时间相近,但是在不断地分配task, schedule会很复杂。适用于,不同task之间,执行时间差距很大,数量有限
Guided: 综合个前两者
Scheduling Examples


每一个section只会被做到一次
section 量不多,通常3到4个
SECTIONS Directive
 ### SINGLE Directive
### SINGLE Directive
Synchronization Construc



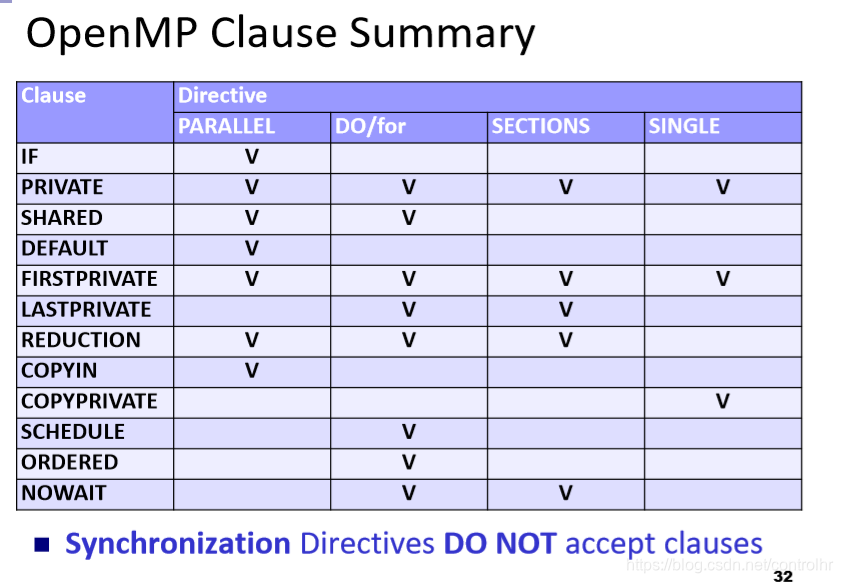
Data Scope Attribute Clauses




Run-Time Library Routines


















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









