






一,介绍布隆过滤器:
布隆过滤器是一种高效的概率型数据结构,主要用于判断某个元素是否存在于集合中。与传统的数据结构相比,布隆过滤器在空间效率和查询速度上具有显著优势,但其代价是存在一定的误判率。
布隆过滤器最早由 Burton Howard Bloom 在1970年提出,广泛应用于网络爬虫、数据库系统、缓存系统等领域。例如,Google Chrome 浏览器就曾使用布隆过滤器来检测恶意网址,而 Redis 也通过布隆过滤器插件支持高效的去重查询。
二,布隆过滤器原理:
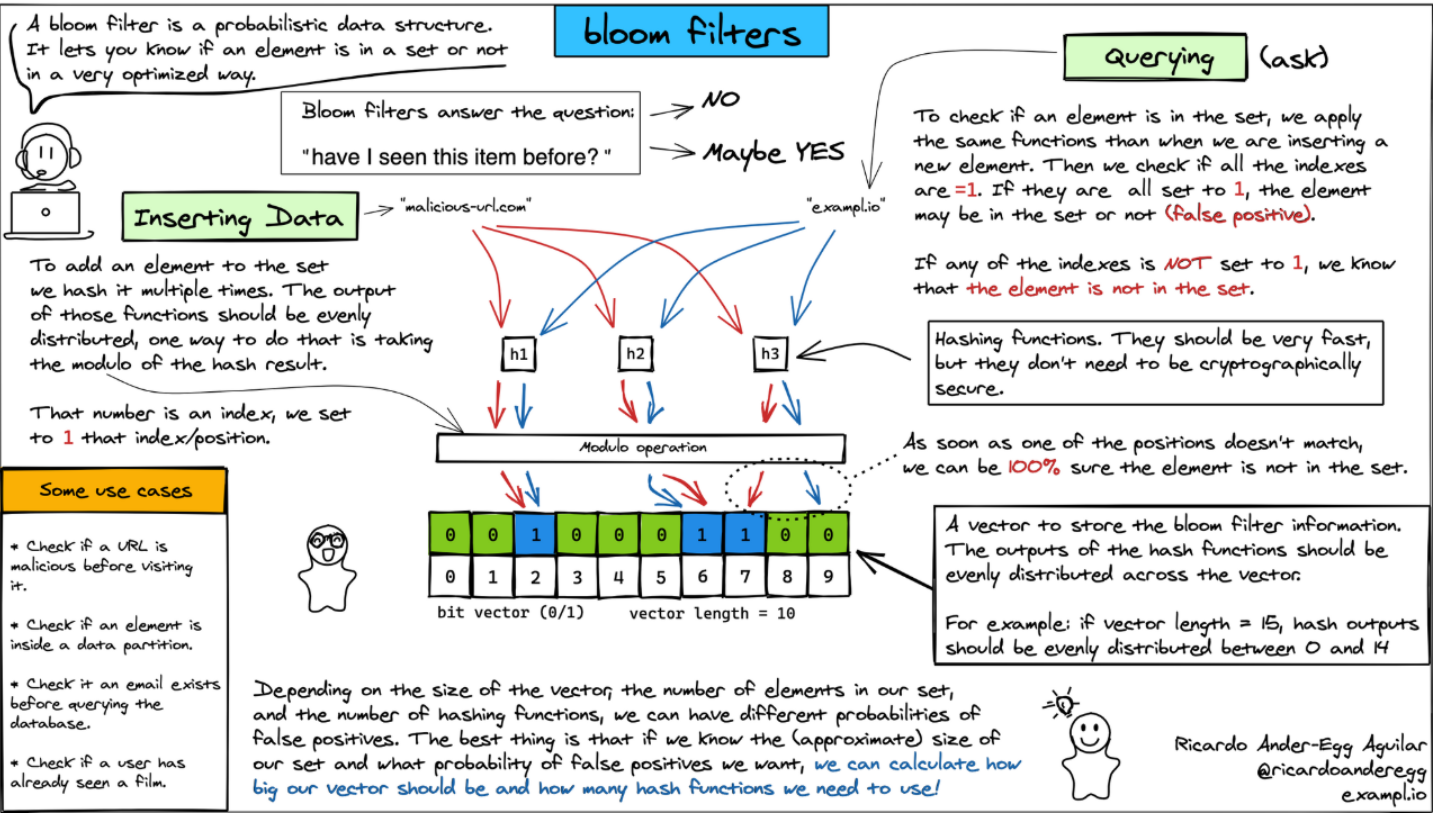
布隆过滤器的核心思想是利用多个哈希函数和位数组来存储数据的存在性信息。具体来说,它的实现可以分为以下几个步骤:
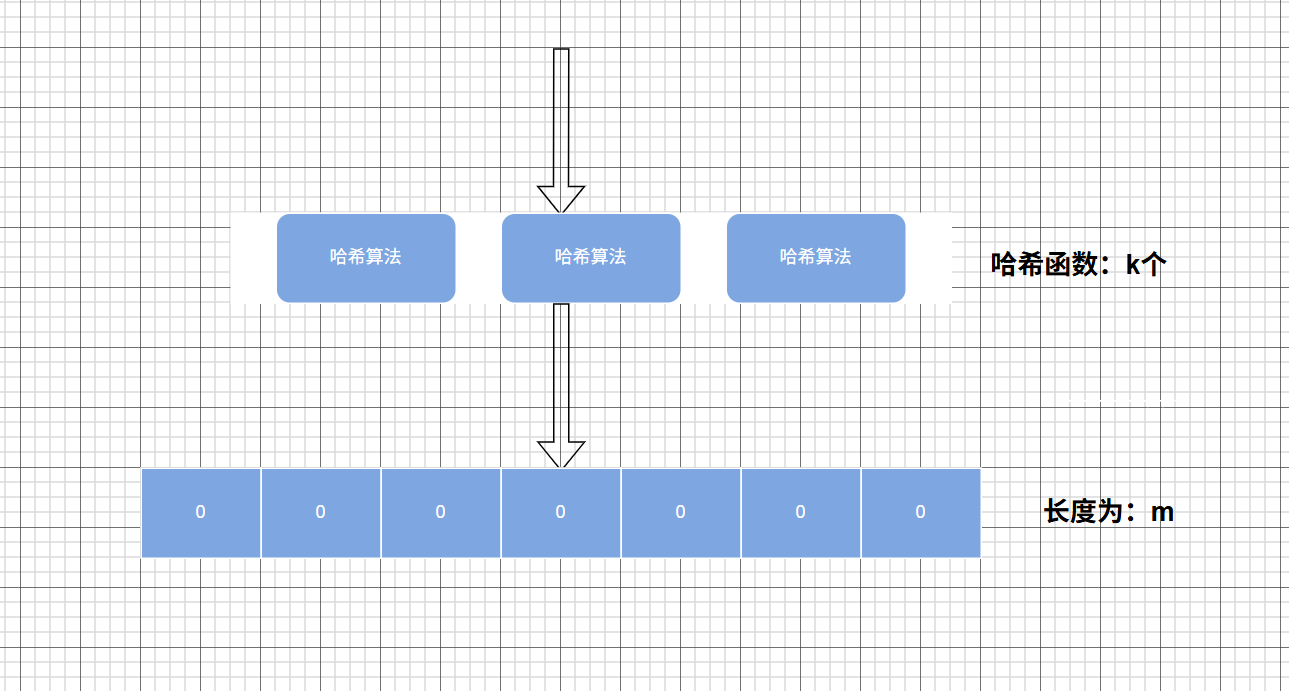
1,位数组初始化 布隆过滤器首先需要一个长度为 m 的位数组,初始时所有位均置为 0。
2,哈希函数映射 当向布隆过滤器中添加一个元素时,会使用 k 个不同的哈希函数对该元素进行计算,得到k个哈希值。这些哈希值会对 m 取模,从而在位数组上标记对应的位置为 1。
3,查询元素是否存在 查询时,同样使用这 k 个哈希函数计算待查元素的哈希值,并检查位数组中对应的位是否均为 1。如果所有位均为 1,则认为该元素可能存在于集合中;如果有任意一位为 0,则可以确定该元素一定不存在。
大致图片如下:
这里借鉴了一下别人的图:
三,优点及局限性
优点:
1,极高的空间效率:由于仅使用位数组存储信息,布隆过滤器相比传统哈希表节省了大量内存。
2,常数时间的查询:无论存储多少元素,查询操作的时间复杂度始终是 O(k),其中 k 是哈希函数的数量。
3,天然支持高并发:由于位数组的原子性操作,布隆过滤器可以轻松应用于多线程环境。
局限性:
1,存在误判:由于哈希冲突,布隆过滤器可能会误判某些不存在的元素为存在。
2,无法删除元素:传统的布隆过滤器不支持删除操作,因为多个元素可能共享相同的位。
3,哈希函数的选择影响性能:如果哈希函数分布不均匀,可能导致误判率上升。
四,布隆过滤器实战
首先先引入依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.25.0</version>
</dependency>实战代码:
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonBloomFilterExample {
public static void main(String[] args) {
// 1. 配置 Redisson 客户端
Config config = new Config();
config.useSingleServer()
.setAddress("redis://127.0.0.1:6379")
// 2. 创建 Redisson 客户端
RedissonClient redisson = Redisson.create(config);
try {
// 3. 获取布隆过滤器实例
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("myBloomFilter");
// falseProbability - 误判率(0.0 < falseProbability < 1.0)
bloomFilter.tryInit(100000L, 0.03);
// 5. 添加元素
bloomFilter.add("element1");
bloomFilter.add("element2");
bloomFilter.add("element3");
// 6. 检查元素是否存在
System.out.println("Contains element1: " + bloomFilter.contains("element1")); // true
System.out.println("Contains element2: " + bloomFilter.contains("element2")); // true
System.out.println("Contains element4: " + bloomFilter.contains("element4")); // false
// 7. 统计功能
System.out.println("Expected insertions: " + bloomFilter.getExpectedInsertions());
System.out.println("False probability: " + bloomFilter.getFalseProbability());
System.out.println("Hash iterations: " + bloomFilter.getHashIterations());
System.out.println("Current size: " + bloomFilter.getSize());
} finally {
//关闭连接
redisson.shutdown();
}
}
}五,手写布隆过滤器
手写代码:
import java.util.BitSet;
public class SimpleBloomFilter {
private BitSet bitSet;
private int bitSetSize;
private int numHashFunctions = 3; // 固定使用3个哈希函数
/**
* 简化的布隆过滤器构造方法
* @param expectedNumItems 预期要存储的元素数量
*/
public SimpleBloomFilter(int expectedNumItems) {
// 简化版:每个元素分配10个bit位
this.bitSetSize = expectedNumItems * 10;
this.bitSet = new BitSet(bitSetSize);
}
/**
* 添加元素到布隆过滤器
* @param item 要添加的元素
*/
public void add(String item) {
// 使用3种不同的哈希方式
int hash1 = hash1(item);
int hash2 = hash2(item);
int hash3 = hash3(item);
bitSet.set(hash1 % bitSetSize, true);
bitSet.set(hash2 % bitSetSize, true);
bitSet.set(hash3 % bitSetSize, true);
}
/**
* 检查元素是否可能在布隆过滤器中
* @param item 要检查的元素
* @return 如果返回false,则肯定不存在;如果返回true,则可能存在
*/
public boolean mightContain(String item) {
int hash1 = hash1(item);
int hash2 = hash2(item);
int hash3 = hash3(item);
return bitSet.get(hash1 % bitSetSize)
&& bitSet.get(hash2 % bitSetSize)
&& bitSet.get(hash3 % bitSetSize);
}
// 第一种哈希函数:使用Java默认的hashCode
private int hash1(String item) {
return item.hashCode();
}
// 第二种哈希函数:简单变种
private int hash2(String item) {
return item.hashCode() * 31;
}
// 第三种哈希函数:另一种变种
private int hash3(String item) {
return Math.abs(item.hashCode() ^ (item.hashCode() >>> 16));
}
public static void main(String[] args) {
// 测试简化版布隆过滤器
SimpleBloomFilter filter = new SimpleBloomFilter(1000);
// 添加一些元素
filter.add("apple");
filter.add("banana");
filter.add("orange");
// 测试存在的元素
System.out.println(filter.mightContain("apple")); // true
System.out.println(filter.mightContain("banana")); // true
System.out.println(filter.mightContain("orange")); // true
// 测试不存在的元素
System.out.println(filter.mightContain("grape")); // 可能是false
System.out.println(filter.mightContain("melon")); // 可能是false
}
}
这里说一下我三个哈希算法的设计思路:
第一个hash1的话:hashCode() 是Java对象的基础哈希方法,能快速生成一个初始哈希值。布隆过滤器不要求哈希函数完美无冲突,所以直接用它是可行的。
第二个hash2的话:31 是一个经典素数(HashMap也在用),乘法能扰动哈希分布,减少碰撞。
第三个hash3的话:(hashCode() >>> 16) 是 HashMap的扰动函数,目的是让高位也参与运算,减少冲突。Math.abs 确保结果为正,方便后续取模映射到布隆过滤器位数组。


















 2992
2992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









