







NameNode:
server:ClientProtocol
serviceRpcServer: DatanodeProtocol、NamenodeProtocol
DataNode:
ipcServer: InterDataNodeProtocol / ClientDataNodeProtocol
JobTracker :
interTrackerServer : InterTrackerProtocol / JobSubmissionProtocol
TaskTracker :
taskReportServer : TaskUmbilicalProtocol
-Dhadoop.log.dir=/home/shengbao/hadoop/log 指定JVM系统属性hadoop.log.dir(本地文件系统日志目录)
简介
Hadoop 的可靠性 ---因为Hadoop假设 计算元素和存储会出现异常,因为它维护多个工作数据副本,在失败时候可以对失败的节点重新分布处理
Hadoop 的高效性 ---在MapReuce的思想下,Hadoop 是并行工作的,以加快任务处理速度
Hadoop 的可扩展 ---依赖于部署Hadoop 软件框架计算集群的规模,Hadoop的运算是可扩展的,具有处理PB级别的能力
Hadoop的组成
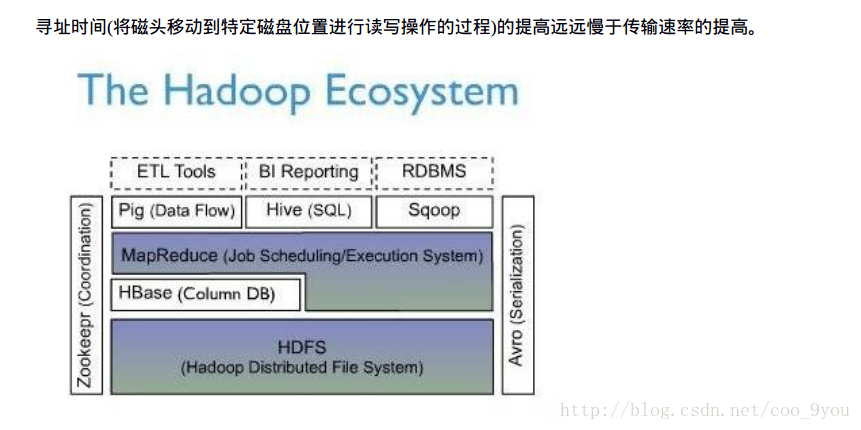
Hadoop Core 是Hadoop 的核心,提供了一个分布式文件系统(HDFS) ,并支持MapReduce分布式计算框架
Hbase 构造在Hadoop Core 之上,提供一个可扩展、分布式的数据库系统
ZooKeeper 是一个高可用、高可靠的协同工作系统、分布式程序可以用ZooKeeper保存并更新关键共享状态
Common 包括FileSystem 、RPC 和串行库
Avro 用于数据序列化
MapReduce 大规模数据集的并行运算
HDFS 分布式文件系统,检测盒快速回复硬件故障、流式的数据访问、简化一致性模型、通信协议TCP/IP
Chukwa
Pig
Hive
Sqoop
Job 客户端需要执行的一个工作单位,包括输入数据、MapReduce程序和配置信息
源代码目录结构:
hadoop-common-project
--hadoop-annotations
--hadoop-auth
-- *hadoop-common
hadoop-hdfs-project
-- *hadoop-hdfs
-- hadoophdfs-httpfs
hadoop-mapreduce-project
-- bin/conf
-- hadoop-mapreduce-client
--hadoop-mapreduce-client-app
-- *hadoop-mapreduce-client-common
-- *hadoop-mapreduce-client-core
-- hadoop-mapreduce-client-hs
-- hadoop-mapreduce-client-jobclient
-- hadoop-mapreduct-client-shuffle
hadoop-yarn-project
--hadoop-yarn
-- bin/conf
-- *hadoop-yarn-api
-- *hadoop-yarn- common
-- hadoop-yarn-server
-- *hadoop-yarn-server-common
-- *hadoop-yarn-server-nodemanager
-- hadoop-yarn-server-web-proxy
-- *hadoop-yarn-server-resourcemanager
-- hadoop-yarn-applications
-- hadoop-yarn-applications-distributedshell
-- hadoop-yarn-applications-unmanaged-am-launcher
-- *hadoop-yarn-client















 3222
3222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









