









 深度压缩技术是一种用于大幅减小神经网络模型大小的方法,包括剪枝、量化及霍夫曼编码三个步骤。通过这些步骤,该技术能显著降低模型的存储需求并提高计算效率。
深度压缩技术是一种用于大幅减小神经网络模型大小的方法,包括剪枝、量化及霍夫曼编码三个步骤。通过这些步骤,该技术能显著降低模型的存储需求并提高计算效率。
本次介绍的方法为“深度压缩”,文章来自2016ICLR最佳论文 《Deep Compression: Compression Deep Neural Networks With Pruning, Trained Quantization And Huffman Coding
这篇论文是Stanford的Song Han的 ICLR2016 的 best paper,Song Han写了一系列网络压缩的论文,这是其中一篇。
另外还可以参考2015年的一篇(主要提出的是prune操作)
Learning both Weights and Connections for Efficient Neural Networks
Song Han, Jeff Pool, John Tran, and William J.Dally: http://arxiv.org/abs/1506.02626
作者给出了AlexNet的一个简易model: https://github.com/songhan/Deep-Compression-AlexNet
,不过这model没什么软用
Introduction
神经网络功能强大。但是,其巨大的存储和计算代价也使得其实用性特别是在移动设备上的应用受到了很大限制。
所以,本文的目标就是:降低大型神经网络其存储和计算消耗,使得其可以在移动设备上得以运行,即要实现 “深度压缩”。
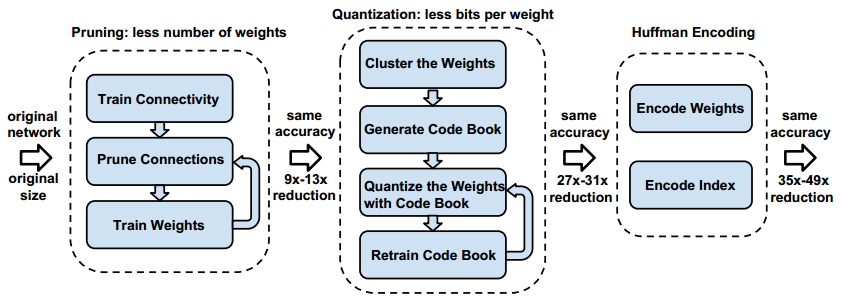
实现的过程主要有三步:
(1) 通过移除不重要的连接来对网络进行剪枝——Prunes the network:只保留一些重要的连接;
(2) 对权重进行量化,使得许多连接共享同一权重,并且只需要存储码本(有效的权重)和索引——Quantize the weights:通过权值量化来共享一些weights;
(3) 进行霍夫曼编码以利用有效权重的有偏分布——Huffman coding:通过霍夫曼编码进一步压缩;
具体如下图:
实验的效果如何?
Pruning:把连接数减少到原来的 1/13~1/9;
Quantization:每一个连接从原来的 32bits 减少到 5bits;
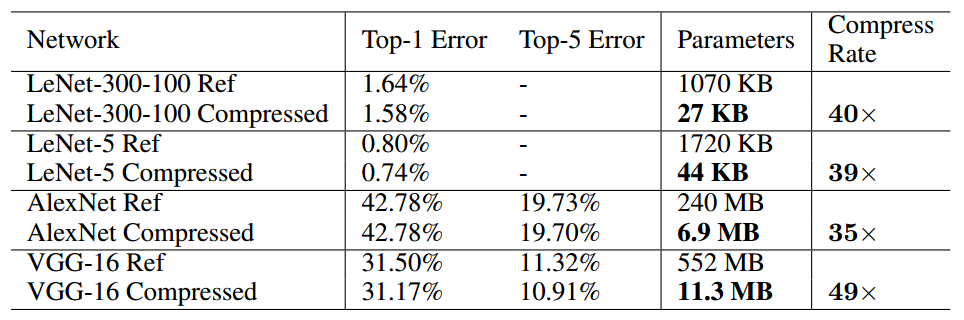
最终效果:
- 把AlextNet压缩了35倍,从 240MB,减小到 6.9MB;
- 把VGG-16压缩了49北,从 552MB 减小到 11.3MB;
- 计算速度是原来的3~4倍,能源消耗是原来的3~7倍;
Network Pruning
“剪枝”详细点说也可以分为3步:
(1) 进行正常的网络训练;
(2) 删除所有权重小于一定阈值的连接;
(3) 对上面得到的稀疏连接网络再训练;
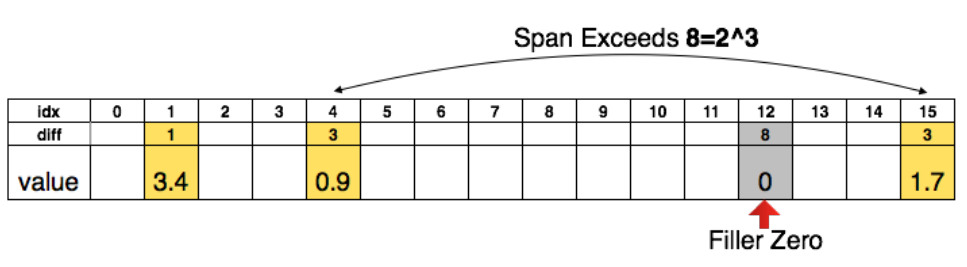
存储稀疏结构时采用的是稀疏压缩行CSR或者稀疏压缩列CSC,假设非0元素个数为a,行或者列数为n,那么我们需要存储的数据量为 2a+n+1。
以CSR为例,我们存储时采用的是3元组结构,即:行优先存储a个非零数,记为A;a个非零数所在列的列号;每一行第一个元素在A中的位置+非零数个数。
为了进一步压缩,这里不存储绝对位置的索引,而是存储相对位置索引。如果相对索引超过了8,那么我们就人为补0。如下图:
Trained Quantization And Weight Sharing
这一部分通过对权重进行量化来进一步压缩网络(量化可以降低表示数据所用的位数)。
通过下图,我们来说明如何对权重进行量化,以及后续又如何对量化网络进行再训练。
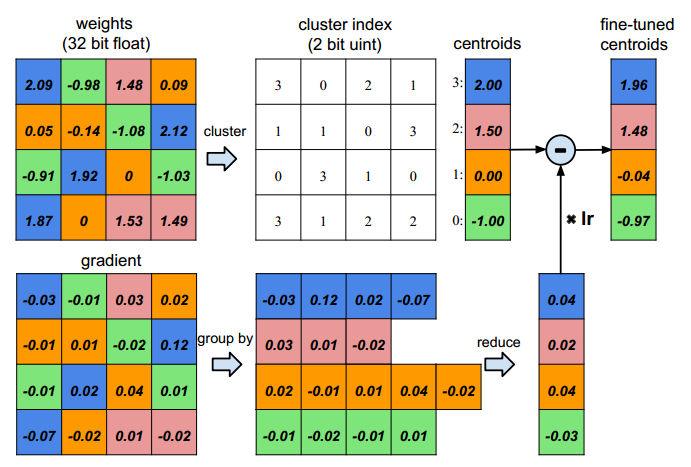
首先,假设我们输入神经元有4个,输出神经元也是4个,那么我们的weight应该是4x4,同样梯度也是。
然后,我们量化权重为4阶,即上图用4种不同颜色表示。这样的话我们就只需要存储4个码字以及16个2bit的索引。
最后,我们应该如何再训练,即如何对量化值进行更新。事实上,我们仅对码字进行更新。具体如上图的下部分:计算相同索引处的梯度之和,然后乘以学习率,对相应的码字进行更新。
实际当中,对于AlexNet,作者对卷积层使用了8bit量化(即有256个码字),对全连接层使用了5bit量化(即有32个码字),但是却不损失性能。
关于如何确定码字:
作者对训练好网络的每一层(即不同层之间权重不共享)的权重进行K-means,聚类中心便是要求的码字。有一点需要注意,K-means聚类时需要初始化聚类中心,不同的初始化方法对最后的聚类结果影响很大,从而也会影响网络的预测精度。这里比较了Forgy(random), density-based, and linear initialization这三种初始化方法。
下图画出了AlexNet中conv3层的权重分布,其中红色线表示概率密度分布PDF,蓝色线表示CDF。显然,剪枝后的网络权重符合双峰分布。图的下方,显示了3种不同初始化方法最后收敛到的聚类中心。
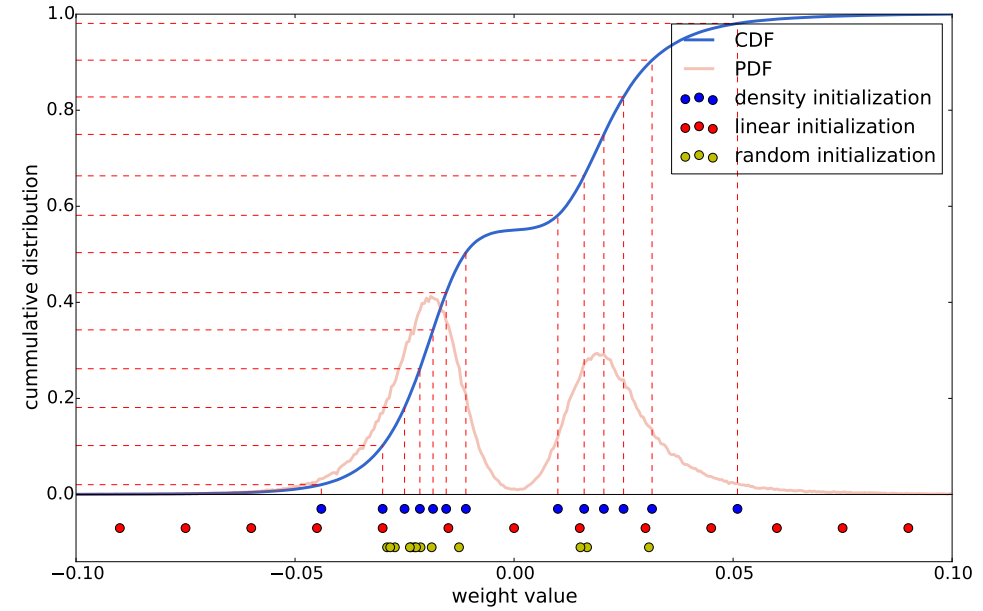
有一点我们需要注意:大权重比小权重的作用要大。因此,从上图来看虽然Forgy(random), density-based方法比较好的拟合了数据分布,但是它们忽略了那些绝对值较大的权重,而linear initialization就不会有这个问题。
因此,文章采用线性初始化,实验也证明了其正确性。
下图是finetune前后的码字分布:
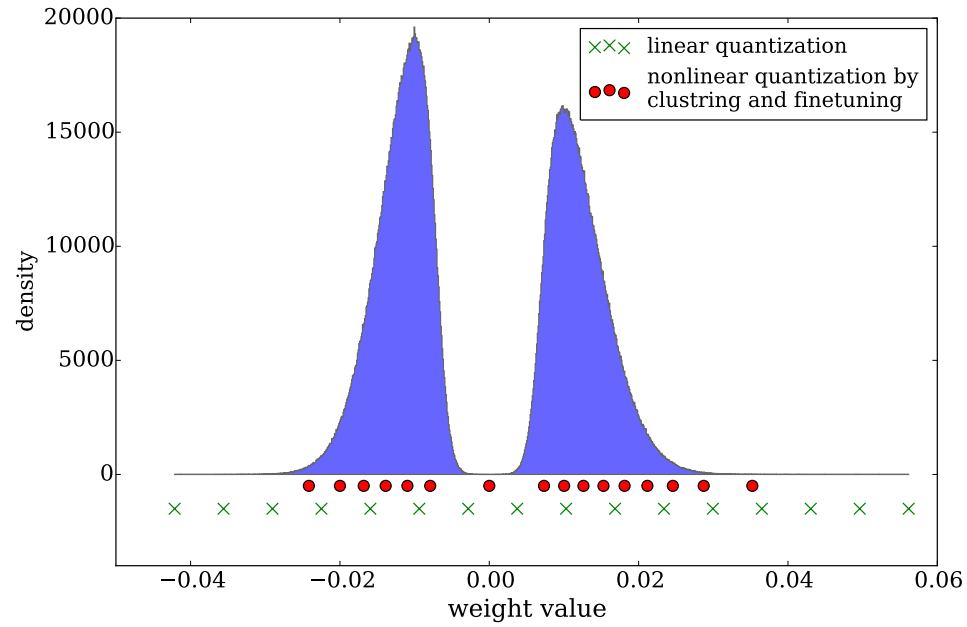
Huffman Coding
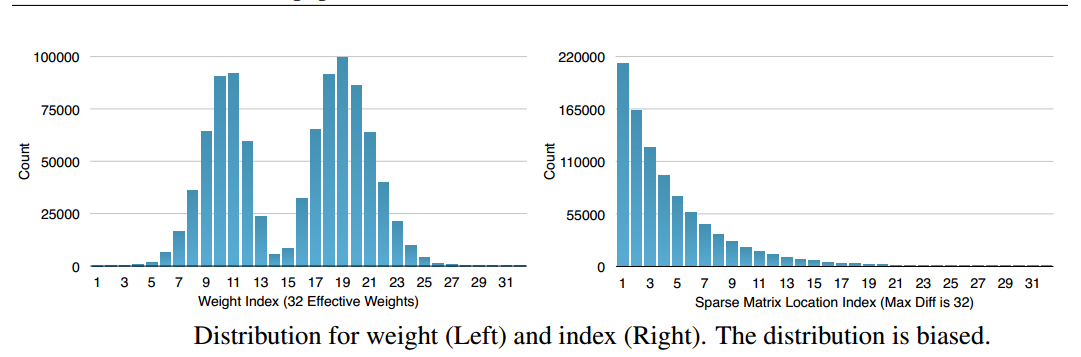
Huffman编码按照符号出现的概率来进行变长编码。下面的权重以及索引分布来自于AlexNet的最后一个全连接层。由图可以看出,其分布是非均匀的,因此我们可以利用Huffman编码来对其进行处理,最终可以使的网络的存储减少20%~30%。
Experiment Results
文章主要在LeNet、AlexNet和VGGNet上做的实验,我这里只列出一部分。
更多对比和论证实验可以阅读原文。
Reference:
** http://lib.csdn.net/article/deeplearning/50854?knId=1741
http://blog.csdn.net/boon_228/article/details/51718521
http://it.sohu.com/20161223/n476741019.shtml
http://jikaichen.com/2016/06/15/notes-on-deep-compression/
较完整论述,DSD训练: http://it.sohu.com/20161223/n476741019.shtml

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









