









原文:arxiv
出版源:《Computer Science》, 2015, 14(7):38-39
问题摘要:
在几乎所有的机器学习算法当中,我们都可以通过对同一数据集进行多次学习得到数个不同的模型,并将各模型的预测结果作以加权作为最终输出这一简单的方式来提高任务性能。然而显然这一方法在计算代价上经常过于昂贵。而在这篇文献当中作者提出了一种所谓的“蒸馏”法,将大规模的训练模型中的细粒度知识迁移至小规模模型的训练当中,使其学习的速度效率提高了很多,并且在小粒度的任务当中对于容易引起困惑的实例的分类效果得到了加强。
关键方法介绍:
在传统的机器学习任务当中,我们在训练模型和将模型配置到用户端当中往往使用相似的模型,然而实际上这两种场景是具有很大的区别的。而作者提出,我们可以训练这种更为普适的复杂模型,并且通过复杂模型的知识迁移,在小规模的specialized任务上大规模地减少训练代价地得到高性能模型。简言之,将整体训练的知识迁移到专门的小模型之中。
在具有大量类别标签的训练任务中,一个复杂度很高的大模型地做法是为这些大量的标签分配概率分布。然而这种处理方式存在一个负作用:与正确标签相比,模型为所有的误标签都分配了很小的概率;然而实际上对于不同的错误标签,其被分配的概率仍然可能存在数个量级的悬殊差距。作者举了一个例子:在识别一辆宝马汽车的图片时,分类器将该图片识别为垃圾车的概率是很小的,然而这种概率比起将其识别为胡萝卜的可能是会大出很多。然而由于在宏观上由于这些概率都很小,这一部分的知识很容易在训练过程中淹没。另一方面,复杂的训练模型的训练过程中,所有的参数都经过了很强的正则化,通过这样的“蒸馏”方法,小模型的训练会模仿大模型的训练方式调整参数,效果要比从头开始训练的效果要好得多。
为了实现上述的知识迁移,作者提出了在训练小模型的时候,将训练目标由传统的ground truth的标签更新为所谓的soft target。soft target在训练过程中可以提供更大的信息熵,将已训练模型地知识更好地传递给新模型;并且由于在此目标之下不同训练实例之间的梯度方差更小,小模型学习所需要的训练数据将会大量减少,并且可以使用更高的学习率,模型的迭代速度将会显著加快。
本文中所提出的上述soft target实际上就是已经训练好的复杂模型的softmax层的输出概率,而其中所提出的“蒸馏”方法在softmax层中引入了一个”温度”参数T:
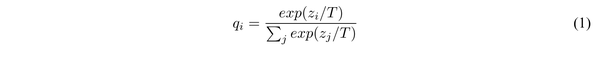 通过上述温度参数的调整,softmax层的映射曲线更加平缓,因而实例的概率映射将更为集中,便使得目标更加地"soft"。并且指出,当transfer set中的标签可得时,将soft target和实际标签的两个目标共同使用作为目标函数将使得其性能更加提高。在训练过程中,作者将迁移样本集中样例输入原复杂模型并通过上述蒸馏softmax得到soft target,并将其作为目标,并在迭代过程中更新温度,训练出细粒度的模型。通过上述温度参数的调整,softmax层的映射曲线更加平缓,因而实例的概率映射将更为集中,便使得目标更加地”soft”。并且指出,当transfer set中的标签可得时,将soft target和实际标签的两个目标共同使用作为目标函数将使得其性能更加提高。在训练过程中,作者将迁移样本集中样例输入原复杂模型并通过上述蒸馏softmax得到soft target,并将其作为目标,并在迭代过程中更新温度,训练出细粒度的模型。
通过上述温度参数的调整,softmax层的映射曲线更加平缓,因而实例的概率映射将更为集中,便使得目标更加地"soft"。并且指出,当transfer set中的标签可得时,将soft target和实际标签的两个目标共同使用作为目标函数将使得其性能更加提高。在训练过程中,作者将迁移样本集中样例输入原复杂模型并通过上述蒸馏softmax得到soft target,并将其作为目标,并在迭代过程中更新温度,训练出细粒度的模型。通过上述温度参数的调整,softmax层的映射曲线更加平缓,因而实例的概率映射将更为集中,便使得目标更加地”soft”。并且指出,当transfer set中的标签可得时,将soft target和实际标签的两个目标共同使用作为目标函数将使得其性能更加提高。在训练过程中,作者将迁移样本集中样例输入原复杂模型并通过上述蒸馏softmax得到soft target,并将其作为目标,并在迭代过程中更新温度,训练出细粒度的模型。
在该论文之前,有研究提出了一种基于匹配softmax层之前的输出层的方法进行知识迁移。而作者论证了这种logit匹配是上述蒸馏法的变异:
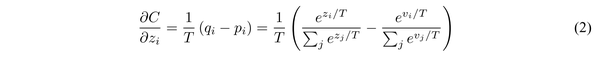
上述是基于soft target的交叉熵代价函数对于某一维度logit的梯度,当温度较高时,对上式可以近似得到:
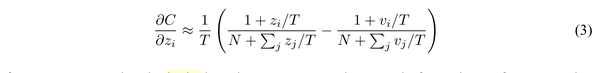 在T相对于logit数量较大的时候(T越大,分类的概率分布越“软”),可以进一步简化为:
在T相对于logit数量较大的时候(T越大,分类的概率分布越“软”),可以进一步简化为:
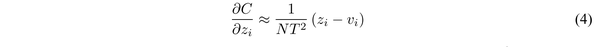 在该情形下,目标函数就变成了优化zi和vi之间的平方误差,这与上述介绍的方法是一致的。
在该情形下,目标函数就变成了优化zi和vi之间的平方误差,这与上述介绍的方法是一致的。
实验:
作者分别在MNIST数据集和ASR数据集上测试了上述方法。在MNIST数据集中,作者在大规模地减少网络规模并且没有做任何正则处理进行训练时的情况下依然得到了很可观的分类效果。而作者尝试在训练小网络时没有输入任何含有3的输入,而模型在训练后依然能分类出相当数量的3的样本。而当训练集只取了7和8两种输入时,通过调整偏置,错误率依然控制在13.2%。而如下表所示,在语音识别当中使用蒸馏法的效果与同时训练十个分类模型的效果相当。
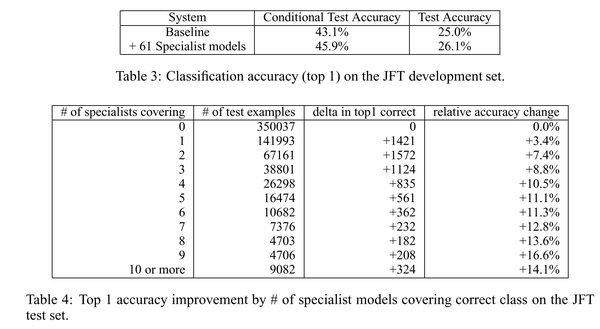
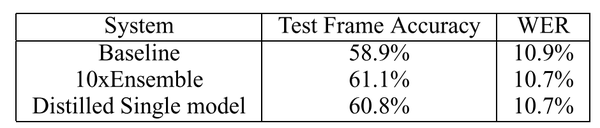 同时,作者还在JFT数据集上测试了在规模巨大的数据样本上训练的generalized模型上通过蒸馏法训练specialized的小模型地情况。通过分布式计算的方式,这些细粒度小样本的计算时间从数周迅速地缩短为几天,并且在粒度更细的任务中对于难以分类的样本产生了更好地效果。在这一部分的配置在原文中有很多细节,如有兴趣可以参考原文。下图给出了蒸馏法对于细粒度任务的性能提升。同时,作者还在JFT数据集上测试了在规模巨大的数据样本上训练的generalized模型上通过蒸馏法训练specialized的小模型地情况。通过分布式计算的方式,这些细粒度小样本的计算时间从数周迅速地缩短为几天,并且在粒度更细的任务中对于难以分类的样本产生了更好地效果。在这一部分的配置在原文中有很多细节,如有兴趣可以参考原文。下图给出了蒸馏法对于细粒度任务的性能提升。
同时,作者还在JFT数据集上测试了在规模巨大的数据样本上训练的generalized模型上通过蒸馏法训练specialized的小模型地情况。通过分布式计算的方式,这些细粒度小样本的计算时间从数周迅速地缩短为几天,并且在粒度更细的任务中对于难以分类的样本产生了更好地效果。在这一部分的配置在原文中有很多细节,如有兴趣可以参考原文。下图给出了蒸馏法对于细粒度任务的性能提升。同时,作者还在JFT数据集上测试了在规模巨大的数据样本上训练的generalized模型上通过蒸馏法训练specialized的小模型地情况。通过分布式计算的方式,这些细粒度小样本的计算时间从数周迅速地缩短为几天,并且在粒度更细的任务中对于难以分类的样本产生了更好地效果。在这一部分的配置在原文中有很多细节,如有兴趣可以参考原文。下图给出了蒸馏法对于细粒度任务的性能提升。
 简评:
简评:
这篇文章的出发点虽然颇为工程,旨在通过这种方式提高深度学习模型在不同具体的用户应用配置和部署的速度和效果。然而最值得参考的思想还是提出了一种将已有知识迁移到新任务中的方式。尽管在文章当中使用的源分布域和目标域来源于同一数据分布,但是其提出的知识迁移和模型正则化和抗过拟合能力的迁移是在Source Domain和Target Domain不同的情况下的迁移方法也有借鉴作用。
Reference
http://blog.csdn.net/zhongshaoyy/article/details/53582048
http://luofanghao.github.io/2016/07/20/%E8%AE%BA%E6%96%87%E7%AC%94%E8%AE%B0%20%E3%80%8ADistilling%20the%20Knowledge%20in%20a%20Neural%20Network%E3%80%8B/
https://zhuanlan.zhihu.com/p/24894102















 5139
5139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









