







任务2.1 数据分析与可视化
数据探索性分析,是通过了解数据集,了解变量间的相互关系以及变量与预测值之间的关系,对已有数据在尽量少的先验假设下通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法,从而帮助我们后期更好地进行特征工程和建立模型,是机器学习中十分重要的一步。
【听了同学讲解后,明白可视化的意思是帮助我们理解数据,进而去探究数据背后的意义,比如与target之间的关系】
编写代码回答下面的问题:
-
字段x1至x8为用户相关的属性,为匿名处理字段。添加代码对这些数据字段的取值分析,那些字段为数值类型?那些字段为类别类型?
-
对于数值类型的字段,考虑绘制在标签分组下的箱线图。
-
从common_ts中提取小时,绘制每小时下标签分布的变化。
-
对udmap进行onehot,统计每个key对应的标签均值,绘制直方图。
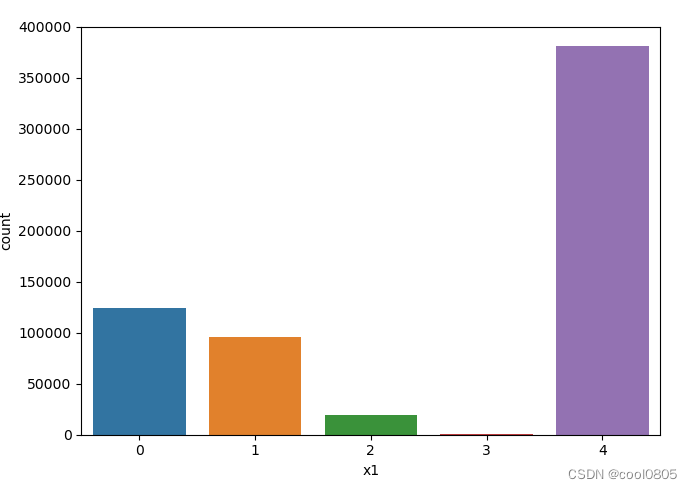
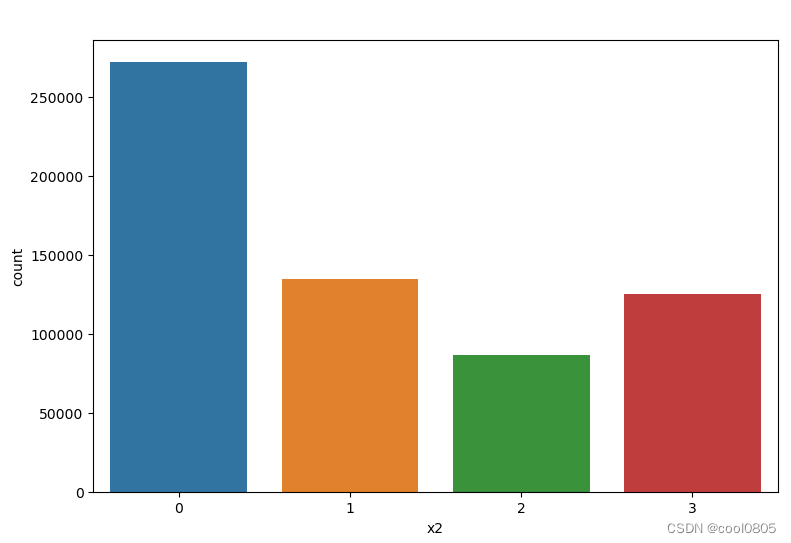
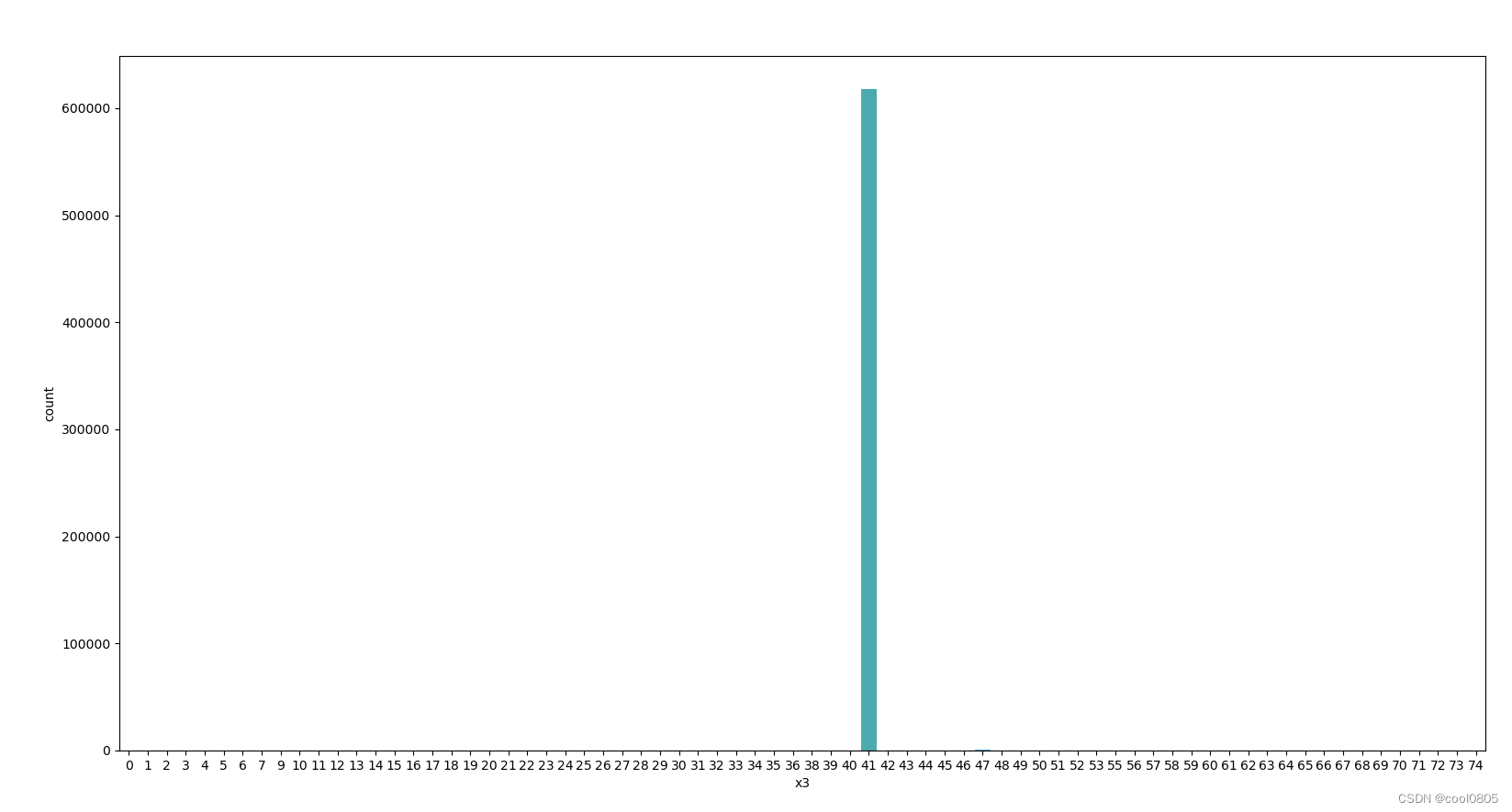
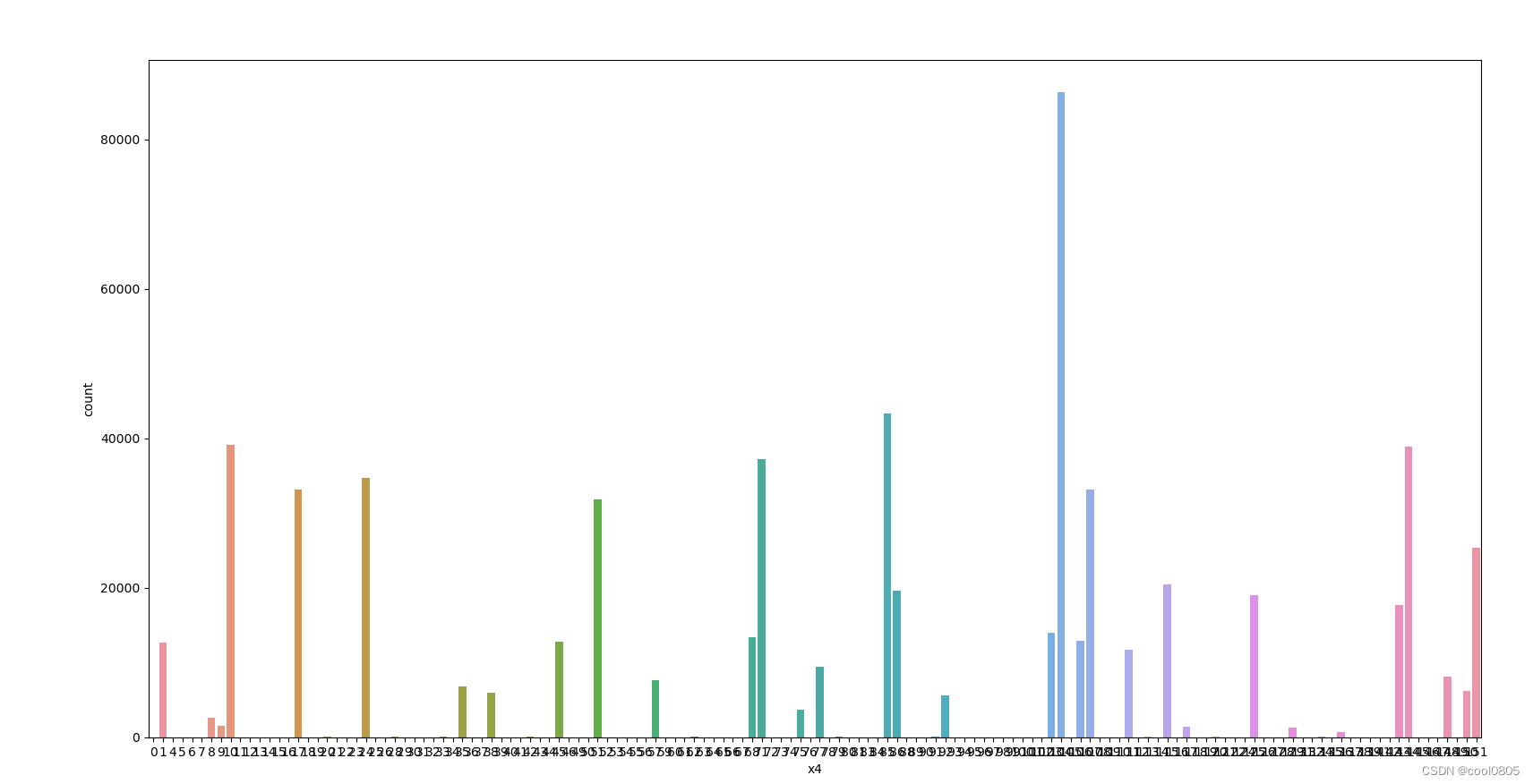
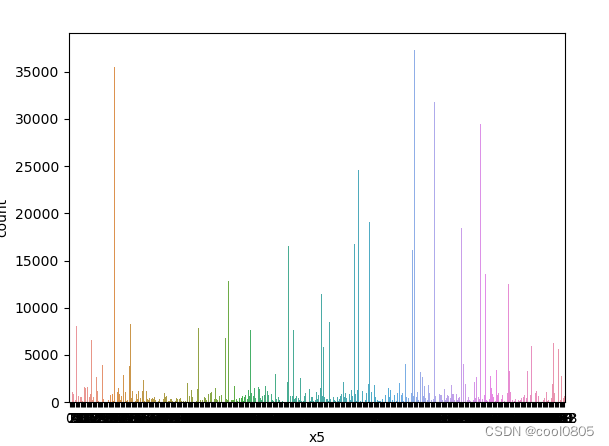
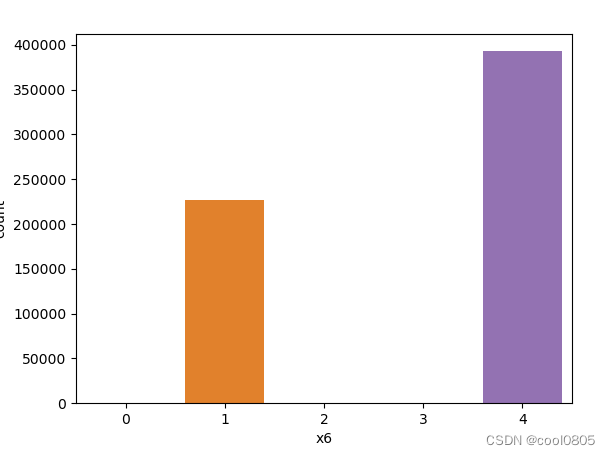
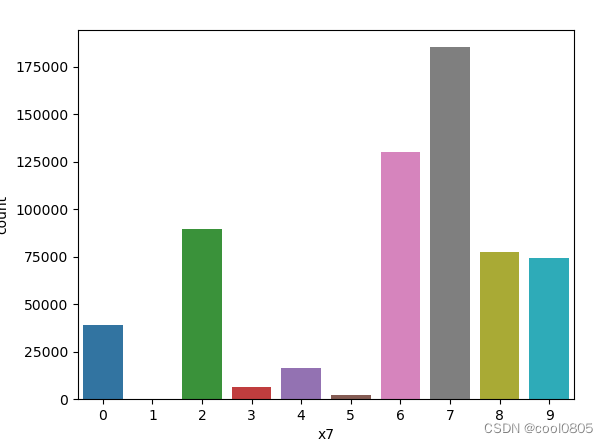
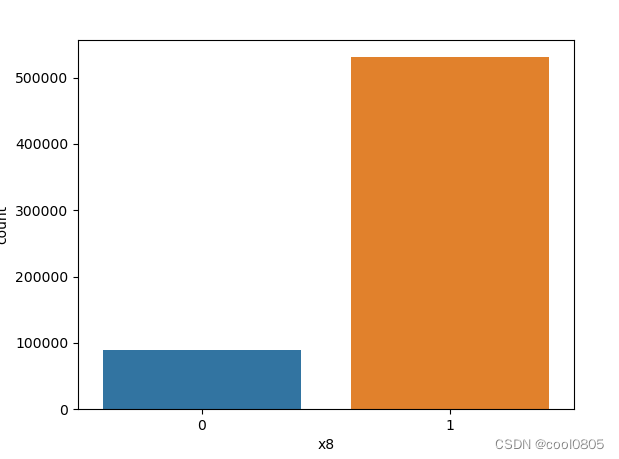
# 添加代码对这些数据字段的取值分析,那些字段为数值类型?那些字段为类别类型?
# sns.distplot(train_data['x1'])
for i in range(1, 9):
sns.countplot(x='x'+str(i), data=train_data)
plt.show()
判断:
x1 x2 x3 x6 x7 x8为类别类型 【是不是离散的就是类别类型?这个定义没有找到】
x4 x5为数值类型 【大胆猜测,连续的就是数值类型】
问题:对于数值类型的字段,考虑绘制在标签分组下的箱线图。
箱线图:
因为箱线图(包含其变体小提琴图、Bean-plot)可以看离群值,更真实的反应数据的分布。
可视化之为什么要使用箱线图? - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/272175756
https://zhuanlan.zhihu.com/p/272175756
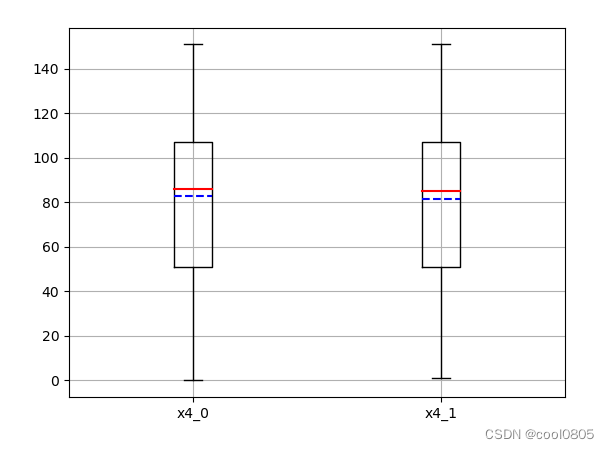
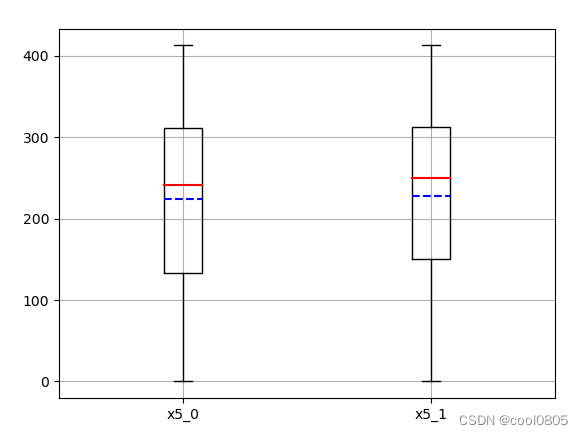
对于标签target : 0 和 1 的分布相近?【不知道有什么用?】【应该是不存在分布不均匀的情况】
问题:从common_ts中提取小时,绘制每小时下标签分布的变化。
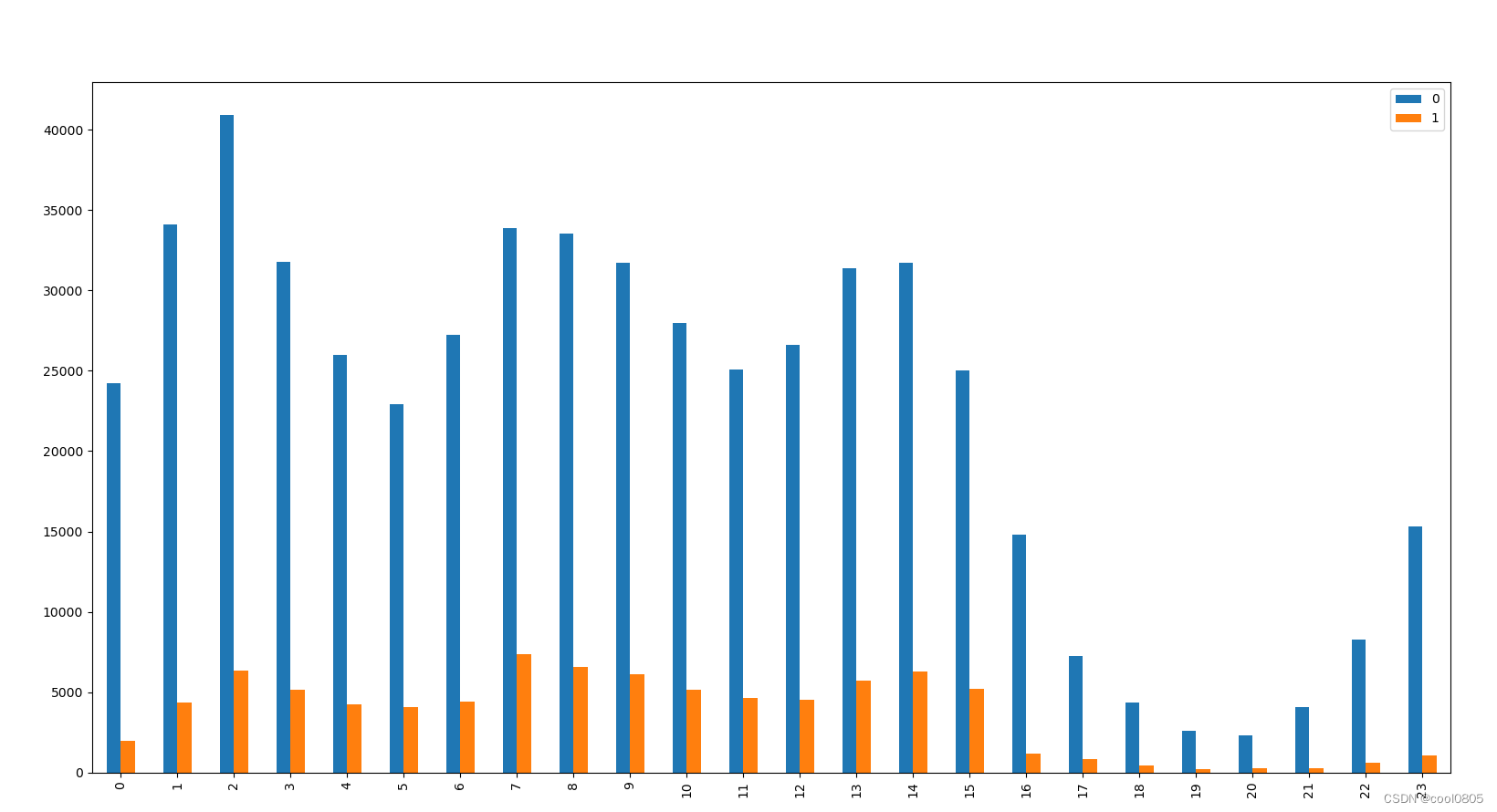
可以看出:用户的访问时间?【不知道有什么用】【某些时间访问,更容易成为新增用户?】
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
test_data['common_ts'] = pd.to_datetime(test_data['common_ts'], unit='ms')
# 使用 dt.hour 属性从 datetime 列中提取小时信息,并将提取的小时信息存储在新的列 'common_ts_hour'
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
test_data['common_ts_hour'] = test_data['common_ts'].dt.hour
# 绘制每小时下标签分布的变化
# 那么就是按小时分组?
group_hour = train_data.groupby(['common_ts_hour'])
# 建立一个空的dataframe
fenbu_counts = pd.DataFrame()
for t in range(0, 24):
fenbu_target = group_hour.get_group(t)['target'] # 获得每个小时的分组
fenbu_counts[t] = fenbu_target.value_counts().to_frame() # 计数,并转成dataframe
print(fenbu_counts)
print(type(fenbu_counts))
# 转置,并画图
fenbu_counts.T.plot.bar()
plt.show()问题:对udmap进行onehot,统计每个key对应的标签均值,绘制直方图。
# 对udmap进行onehot,统计每个key对应的标签均值,绘制直方图。
def udmap_onethot(d):
v = np.zeros(9) # 创建一个长度为 9 的零数组
if d == 'unknown': # 如果 'udmap' 的值是 'unknown'
return v # 返回零数组
d = eval(d) # 将 'udmap' 的值解析为一个字典
for i in range(1, 10): # 遍历 'key1' 到 'key9', 注意, 这里不包括10本身
if 'key' + str(i) in d: # 如果当前键存在于字典中
v[i - 1] = d['key' + str(i)] # 将字典中的值存储在对应的索引位置上,python的索引从0开始
return v # 返回 One-Hot 编码后的数组
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
# 为新的特征 DataFrame 命名列名
train_udmap_df.columns = ['k' + str(i) for i in range(1, 10)]
# 将编码后的 udmap 特征与原始数据进行拼接,沿着列方向拼接
train_data = pd.concat([train_data, train_udmap_df], axis=1)
# print(train_data)
df_k1 = train_data.groupby('k1')['target'].mean()
df_k2 = train_data.groupby('k2')['target'].mean()
df_k3 = train_data.groupby('k3')['target'].mean()
df_k4 = train_data.groupby('k4')['target'].mean()
df_k5 = train_data.groupby('k5')['target'].mean()
df_k6 = train_data.groupby('k6')['target'].mean()
df_k7 = train_data.groupby('k7')['target'].mean()
df_k8 = train_data.groupby('k8')['target'].mean()
df_k9 = train_data.groupby('k9')['target'].mean()
# print(df_k1)
# print(type(df_k1)) # series 类型的数据
# 求均值
mean_keys = []
mean_keys.append(df_k1.mean())
mean_keys.append(df_k2.mean())
mean_keys.append(df_k3.mean())
mean_keys.append(df_k4.mean())
mean_keys.append(df_k5.mean())
mean_keys.append(df_k6.mean())
mean_keys.append(df_k7.mean())
mean_keys.append(df_k8.mean())
mean_keys.append(df_k8.mean())
mean_keys.append(df_k9.mean())
print(mean_keys)
plt.hist(mean_keys)
plt.show()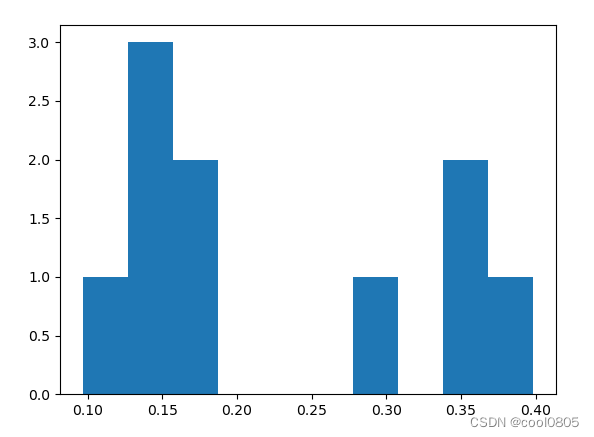
什么是直方图,直方图又有什么作用? - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/407833607
https://zhuanlan.zhihu.com/p/407833607
任务2.2 运行给出的代码
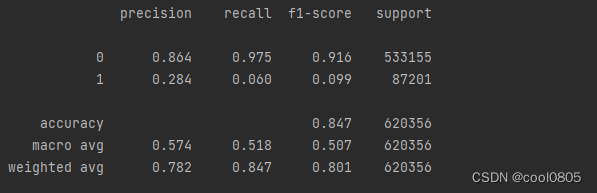
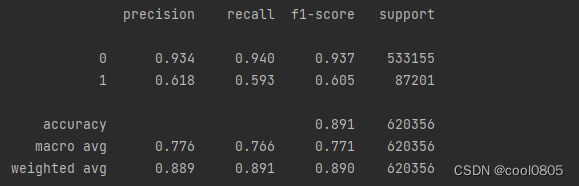
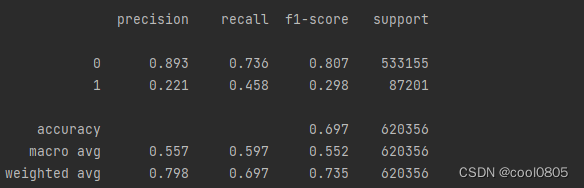
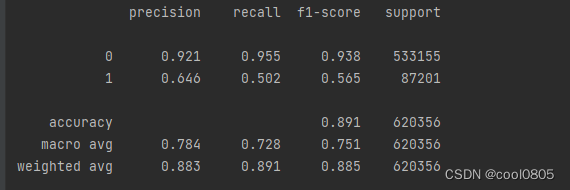
问题:在上面模型中哪一个模型的macro F1效果最好,为什么这个模型效果最好?
答:决策树,0.7741
问题:使用树模型训练,然后对特征重要性进行可视化;
答:
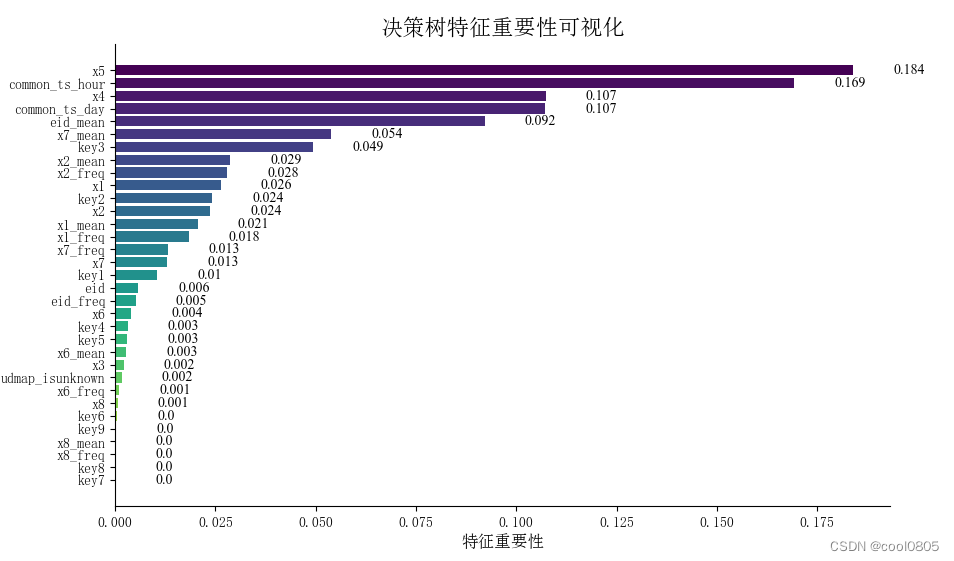
问题:再加入3个模型训练,对比模型精度;
答: 决策树——0.891 随机森林——0.891
















 84
84











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









