







GFS阅读笔记
摘要
GFS:google file system,谷歌的分布式文件系统,运行在廉价的PC上,但仍能提供高可靠,高性能的服务。
1.简介
设计目标:
(1)高性能(performance);
(2)可扩展(scalability);
(3)高可靠性(reliability);
(4)高可用(availability);
假设与设计思路:
(1)组件失效是常态(component normal failures),因此持续监控、错误检测、灾难冗余、自动恢复机制必须具备;
(2)大文件是常态(GB files common),因此IO操作,block size都需要重新考虑;
(3)追加写设计(data appending),几乎没有随机写,这样考虑的原因是基于性能优化与操作原子性;
(4)提供API以简化应用程序,例如提供原子性写,而无需应用程序来同步互斥以保证数据一致性;
2.设计概览
2.1设计预期
(1)假设与设计思路中的第一点;
(2)假设与设计思路中的第二点;
(3)应用工作负载有两种读取模式:大量流式顺序读,少量随机读;
(4)应用工作负载写入模式:大量顺序追加写入;
(5)系统必须明确定义多客户端并发追加写的行为;
(6)高速、高性能并行远比低延时重要(意味着吞吐量比响应速度更重要);
2.2接口
支持文件,文件以分层目录形式组织,用路径名称来标识。
(1)支持传统常用文件操作:创建、删除、打开、关闭、读、写;
(2)支持快照(snapshot):低成本创建文件或目录树的拷贝;
(3)支持记录追加(record append):允许多个客户端同时对一个文件进行数据追加,且保证追加操作的原子性;
2.3架构
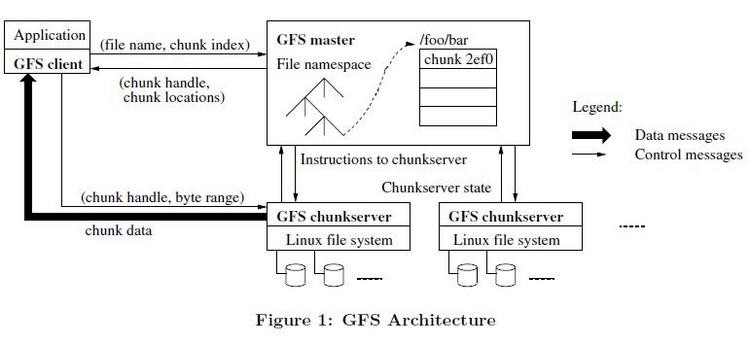
(1)一个GFS集群由单master,多chunkserver,多client组成;
图一:GFS经典图例
(2)文件被切分为多个固定大小(fixed-size)的chunk,每个chunk有一个64bit的唯一标识(handle),每个chunk在多个chunkserver上保存有多副本(默认为3份);
(3)master维护元数据(metadata),元数据包括名字空间(namespace),访问控制信息(acl),文件到chunk的映射(mapping from file to chunk),chunk的位置信息(location of chunks);master还负责chunk的lease管理,孤儿chunk的回收,chunk的自动迁移;master定期向chunkserver发送心跳,维护其状态信息;
(4)client的API以库的形式提供;
(5)client和chunkserver都不缓存文件数据(数据太大了),但会缓存元数据,如chunkserver的信息;
2.4单master策略
此处的单master指逻辑上的master单点。
(1)单master的设计极大的简化了设计;它具有全局视野,可以轻易实施chunk定位与迁移,复制策略。为了避免单master成为系统的瓶颈,必须减少client对master的读写:client向master询问它应该访问的chunkserver,并缓存chunkserver信息,后续都只会通过chunkserver读写数据;
(2)简单解释下读写流程:
首先,客户端把文件名与字节偏移,计算出chunk索引;
然后,将chunk索引发送置master,master将返回chunk表示与副本的位置信息;此时客户端会缓存这些信息;
之后,客户端发送请求至其中一个副本(一般选最近的),请求包含chunk的标识与读写字节范围;之后就不需要再与master交互了(除非过期);
2.5chunk大小
GFS的chunk大小选择为64M,优点如下:
(1)大chunk存储容量大,减少客户端与master的交互;
(2)大chunk存储容量大,尽量使一次写操作只与一个chunkserver交互,保持tcp连接,减少网络负载;
(3)减少master中元数据的存储量(全部保存至内存);
缺点如下:
(1)小文件往往只存储在一个chunk中,使存储这些chunk的chunkserver容易成为热点;
解决办法:
(1)对于读热点,增加冗余份数;
(2)应用层可以增加如“从其他客户端读取数据”等类似策略;
2.6元数据
master存储3种主要元数据,且都放在内存中:
(1)文件和chunk的名字空间;
(2)文件和chunk的对应关系;
(3)每个chunk副本的位置。
前两种元数据的任何变更同时也会记录到日志中(当然刷到磁盘上),日志会进行冗余复制。
原因:
(1)master挂掉不会导致数据不一致;
(2)chunk副本位置不记录日志,master启动、有chunkserver加入时,会向各个chunkserver轮询其存储的chunk信息。
2.6.1内存中的数据结构
潜在问题:
(1)元数据放在内存中,内存是否够用:64字节的struct管理64MB的chunk信息,不是问题;
(2)名字空间使用前缀压缩算法压缩,也在64字节以下;
2.6.2chunk位置信息
(1)定时向各个chunkserver轮询chunk位置信息;
(2)轮询避免了chunkserver加入、离开、更名、失效、重启时出现的数据不一致情况;
2.6.3日志
日志记录元数据的历史变更记录,它是元数据唯一的持久化存储,同时它还保存操作时间线;
chunk、文件连同它们的版本,都由它们创建的时间永久标识;
日志写成功后,才会响应客户端;
日志必须足够小;
容灾恢复需要最近一次checkpoint以及其后的日志;
2.7一致性模型
2.7.1机制
(1)名字空间的修改是原子性的,它们由master节点控制;
(2)master节点的日志保证了元数据操作的顺序性;
(3)读写顺序可能引发的不一致:
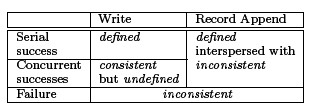
数据库经典图二
2.7.2实现
(1)只追加写,不覆盖写;
(2)checkpoint,checkpoint包含程序级别的校验和;
(3)写操作自验证;
(4)记录自标识;
3.系统交互
原则:最小化与master节点的交互
3.1lease与写操作顺序
写操作会改变chunk内容,或者元数据内容,如果进行写操作,会改变chunk的所有副本;
(1)使用lease保证多副本间写入顺序的一致性:
master为chunk的一个副本创建一个lease,使之成为主chunk;
主chunk对所有写入操作进行序列化;
所有其他副本遵从主副本的序列化操作;
lease机制是为了最小化master的负担,主chunk对lease的持有有超时设置;
在chunk被修改时,主chunk可以申请延长lease持有时间;
master可以取消lease,例如master要取消文件上的修改;
(2)写操作的流程
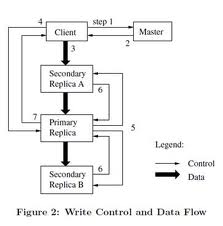
图二:写操作控制流与数据流
step1.客户端向master询问,哪个chunkserver持有lease,以及chunk的位置;如果没有chunk持有lease,则指定一个;
step2.master将主chunk,其他chunk的位置反馈给客户端,客户端会缓存这些元信息;
step3.客户端将数据传给chunkserver,数据流一定要推送给主chunk;
step4.数据传递给所有chunkserver后,控制流发往主chunk,主chunk对操作进行序列化;
step5.将序列化后的“操作序列”发往其他chunkserver;
step6.其他chunkserver执行完后返回主chunkserver;
step7.所有chunkserver执行完后返回客户端;
3.2数据流
(1)为了提高网络消息,数据流与控制流分离;
(2)为了避免延时,每台机器会选择一台“最近”的机器作为数据推送目标,“最近”可简单的由IP地址计算出;
(3)服务器间数据传递使用TCP长连接;
经验结论是,1M的数据约80ms就能分发完毕。
3.3原子性记录追加操作
多个客户端同时写入一个文件,原子性实现有以下两种方法:
(1)分布式锁;
(2)使用多个生产者,单个消费者的队列系统,合并多个客户端的写入;
GFS使用了方法(2)。
3.4快照
如同AFS(Andrew File System)一样,使用标准的copy-on-write技术实现快照:
(1)收到快照请求时,master会取消所有文件的chunk租约;
(2)master将操作日志刷到硬盘上(元数据的写操作日志,量是很小的);
(3)master备份多份操作日志,完成快照;
4.master的操作
master的职能:
(1)所有名字空间操作;
(2)管理chunk副本元信息,包括决定chunk位置,创建chunk等;
(3)实现chunk负载均衡,回收垃圾chunk;
4.1名字空间管理和锁
(1)GFS不支持文件或目录的链接,逻辑上,名字空间就是目录树;
(2)每个目录是一个节点,对应一个读写锁;
(3)操作某个文件,必须递归获取各上级目录的锁;
例如:要操作文件/d1/d2/d3/file1,就必须先获取/d1/d2/d3,/d1/d2,/d1三把锁。
(4)读写锁的冲突方式,与普通数据库读写锁,文件读写锁的冲突方式一致;
优点:
(1)支持同一目录下多个文件的并行操作;
(2)使用全局锁视野避免死锁;
4.2副本的位置
副本放置的三大目标:
(1)最大化数据可靠性;
(2)最大化数据可用性;
(3)最大化网络带宽利用率;
副本放置方式:
(1)一个副本多份;
(2)每份副本在不同机器上;
(3)机器尽量分布在不同机架上;
4.3副本的创建、复制与均衡
master创建副本将考虑的因素:
(1)均衡chunkserver磁盘使用率;
(2)均衡chunkserver写操作频率;
(3)均衡各机架的chunkserver;
副本的复制:
(1)某chunkserver不可用了,master会复制其上的chunk到其他机器;
(2)增加了副本数配置也会引起副本的复制;
(3)复制策略与创建策略相同;
4.4垃圾回收
(1)文件被删除时,master会将删除日志记录下来,但并不马上回收资源;
(2)被删除的chunk会记录时间戳,并置删除标记(所以删除是高效的,删除后chunk未被写入前,恢复是可行的);
(3)独立任务扫描chunk,孤儿chunk将被删除,同时向master发消息以删除元数据;
5.容错与诊断
挑战:
(1)集群中有机器挂掉怎么办;
(2)产生不完整的数据怎么办;
5.1高可用性
(1)快速恢复技术:不管master和chunkserver如何关闭,可以在秒级时间恢复并重启,这可以用重试加心跳机制检测可用性,用重试来避免少量颠簸引起的丢包或延时;
(2)chunk复制技术:chksum校验能轻易发现损坏或者不完整的数据,并复制损坏的chunk;
(3)master的复制:master的日志、checkpoint文件都会有冗余;
(4)master冗余:多个影子master存在,一旦master挂掉,影子master可以马上恢复;
5.2数据完整性
(1)chunk分块:chunk分为64KB的小块,每块对应32bit的checksum;
(2)checksum独立保存:checksum与数据分开存储,永久保存,独立日志;
(3)独立检测单元:chunkserver会定时检测chunk各个分块的checksum,发现错误,立刻复制;
5.3诊断工具
(1)一些辅助手段判断系统是否正常运行,如显示当前系统运行状况等;
(2)线下日志挖掘、监控手段等;
n.结束语
GFS展示了一个使用普通硬件支持大规模数据处理的系统特性,虽然有一些定制化,但还是有很多类似规模和成本的处理任务:
(1)可预见的特性:失效是常态、追加写、顺序读、简易接口等;
(2)监控、冗余、快速自动恢复来容灾;
(3)分离控制流与数据量,提高吞吐量。















 2918
2918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









