







全部四个排序函数都遵循类似的语法模式:
排序函数
() OVER(
[PARTITION BY ]
ORDER BY )
该函数只能在查询的两个子句中指定 — 在 SELECT 子句或 ORDER BY 子句中
实验数据:
|
|
USE demo CREATE TABLE SpeakerStats ( --演讲者的名字 speaker VARCHAR(10) NOT NULL PRIMARY KEY, -- 议题 track VARCHAR(10) NOT NULL, -- 平均得分 score INT NOT NULL, -- 填写评价的与会者相对于参加会议的与会者数量的百分比 pctfilledevals INT NOT NULL, --该演讲者发表演讲的次数 numsessions INT NOT NULL )
|
-
ROW_NUMBER() 向查 询的结果行提供连续的整数值
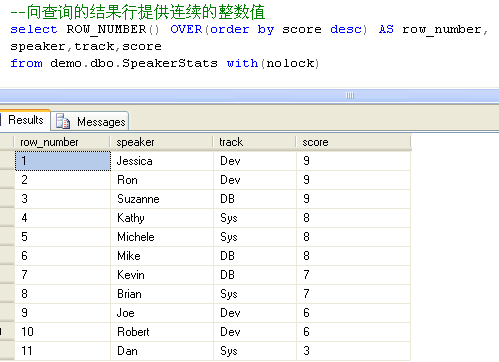
得分最高的演讲者获得行号 1,得分最低的演讲者获得行号 11。ROW_NUMBER 总是按照请求的排序为不同的行生成不同的行号。请注意,如果在 OVER() 选项中指定的 ORDER BY 列表不唯一,则结果是不确定的。这意味着该查询具有一个以上正确的结果;在该查询的不同调用中,可能获得不同的结果。例如,在我们的示例中,有三个不同的演讲者获得相同的最高得分 (9):Jessica、Ron 和 Suzanne。由于 SQL Server 必须为不同的演讲者分配不同的行号,因此您应当假设分别分配给 Jessica、Ron 和 Suzanne 的值 1、2 和 3 是按任意顺序分配给这些演讲者的。如果值 1、2 和 3 被分别分配给 Ron、Suzanne 和 Jessica,则结果应该同样正确。
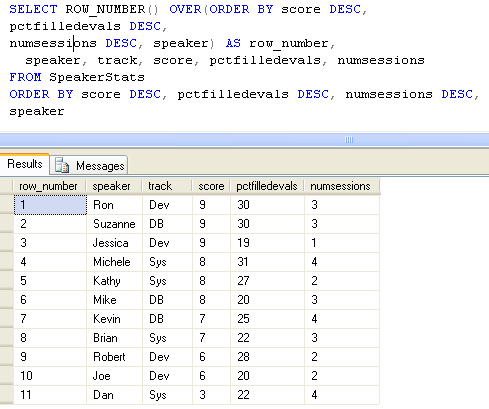
如果您指定一个唯一的 ORDER BY 列表,则结果总是确定的。例如,假设在演讲者之间出现得分相同的情况时,
您希望使用最高的 pctfilledevals 值来分出先后。如果值仍然相同,则使用最高
的 numsessions 值来分出先后。最后,如果值仍然相同,则使用最低词
典顺序 speaker 名字来分出先后。由于 ORDER BY 列表 — score、
pctfilledevals、numsessions 和 speaker — 是唯一的,因此结果是确定的:
新函数的好处:
l 效率
SQL Server 的优化程序只需要扫描数据一次,以便计算值。它完成该工作的方法是:使用在排序列上放置的索引的有序扫描,或者,如果未创建适当的索引,则扫描数据一次并对其进行排序。SQL Server 2005 查询的性能恶化是线性的,而 SQL Server 2000 查询的性能恶化是指数性的。即使是在相当小的表中,性能差异也是显著的
l 简单
SQL Server 2000 查询,它返回与上一个查询相同的结果
SELECT
(SELECT COUNT(*)
FROM SpeakerStats AS S2
WHERE S2.score > S1.score
OR (S2.score = S1.score
AND S2.pctfilledevals > S1.pctfilledevals)
OR (S2.score = S1.score
AND S2.pctfilledevals = S1.pctfilledevals
AND S2.numsessions > S1.numsessions)
OR (S2.score = S1.score
AND S2.pctfilledevals = S1.pctfilledevals
AND S2.numsessions = S1.numsessions
AND S2.speaker < S1.speaker)) + 1 AS rownum,
speaker, track, score, pctfilledevals, numsessions
FROM SpeakerStats AS S1
ORDER BY score DESC, pctfilledevals DESC, numsessions DESC, speaker
- 通过行号来分页
SQL Server2005的row_number比Oracle的更先进。因为它把Order by集成到了一 起, 不用像Oracle那样还要用子查询进行封装
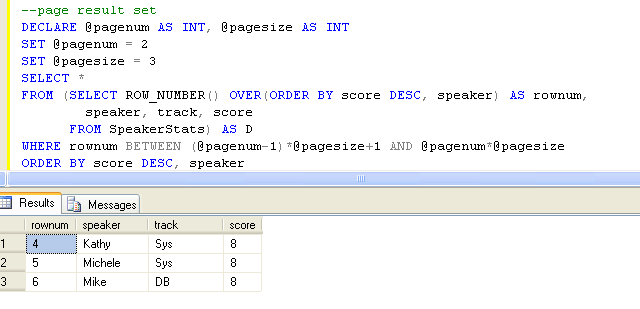
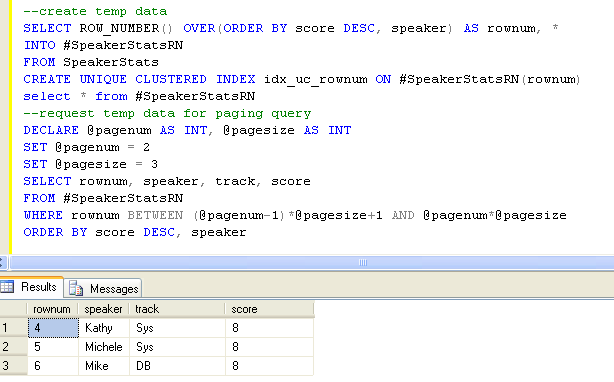
上述方法对于您只对行的一个特定页感兴趣的特定请求而言已经足够了。但是,当用户发出多个请求时,该方法就不能满足需要了,因为该查询的每个调用都需要您对表进行完整扫描,以便计算行号。当用户可能反复请求不同的页时,为了更有效地进行分页,请首先用所有基础表行(包括计算得到的行号)填充一个临时表,并且对包含这些行号的列进行索引:
然后,对于所请求的每个页,发出以下查询,只有属于预期页的行才会被扫描
-
分段
在行组内部独立地计算排序值,而不是为作为一个组的所有表行计算排序值。为此,请使用 PARTITION BY 子句,并且指定一个表达式列
表,以标识应该为其独立计算排序值的行组。
在 PARTITION BY 子句中指定 track 列会使得为具有相同 track 的每个行组单独计算行号。
SELECT track,
ROW_NUMBER() OVER(
PARTITION BY track
ORDER BY score DESC, speaker) AS pos,
speaker, score
FROM SpeakerStats
ORDER BY track, score desc, speaker















 2464
2464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









