







第一次学习CHM的时候,虽然知道了理论,但是还是不深刻。昨天把HashMap的源码看了下,再来理解CHM,就自然多了。
HashMap的原码分析,请参考我的另一篇文章: https://blog.csdn.net/coolfishbone_joey/article/details/107696701
那CHM和HashMap一比较,印象就深刻多了:
1. 相同点:
两者的数据结构都是数组 + 链表 + 红黑树。
初始化的数组长度都是16, 扩展因子都是0.75。
扩容的条件都是,链表长度> 8, 数组长度< 64.
链表转树和条件是, 链表长度> 8, 数组长度 > 64.
树转回链表的条件是,tree的子节点数 < 6.
扩容后,都要进行数据copy, 后边说搬数据时的不同。
2. 不同点
1).CHM 在1.8中把原来的分段锁,进一步优化成锁住数组一个元素,相当于锁了同一个hash对就的链表/树。 比1.7 的锁一段entries要更细。产发会更佳。 而HashMap 没有锁的机制,是线程不安全的。
添加数据时,HashMap是, 如果在对应数组元素的位置没有节点,直接new一个节点放那里,存数据。而CHM new 节点时还用到到以下函数:casTabAt(),当对应数组元素为空时,会直接用CAS操作放入数据,无锁的原子操作,当元素不为空时才会锁这个节点,然后操作链表或者树,用的 synchronized (f) 来锁住。

可以看到这个函数里边调用 了以下unsafe函数CAS操作,来保证操作的原子性:

CHM中对应的get 操作也用到了volatile的特性,保证并发中数据的可见性:

2). 在数据扩容后搬移时,HashMap是判断如果原为的节点下为LinkList,放到NewMap[i+len]中, 如果为treeNode放到newMap[i]中,len为原来数组的长度。
而CHM在扩容时:
a).会把Linklis, tree 分成高低链表,高低树,低的不动,高的放到newMap[i+len]中。因为len 为16, 16*2, 16*3 ...,他始终是2的n次方,所以只有一个bit为1, 在分高低链表的时候就是用这个bit来决定的。当搬好数据后,下次访问时,如果算出来是低,直接取i的位置,如果算出来为高就直接 i+len就可以找到高位对应的数据了。这样设计比原来的要算两Hash提高了效率。
下图是用len要拆分高低链表/树的代码:
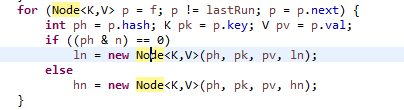
b). CHM 搬移数据也是多个线程同时进行了,其中有一个sizectl的标志指示线程的各种状态,数据中的节点类型可以让线程知道这个节点是不是已经搬移完成。每一个线程是负责16个bucket, 如果map的长度不到16, 那就只会有一个线程来处理。
c). 关于数组的长度计算,在CHM中 当你要获取map的size的时候 ,会有两个数据要读取,baseCount和countCells,
如果只有一个线程,直接取baseCount就可以了,如果在并发的情况下,比如2个线程同时向CHM中添加数据,那当要 +1时,会把要加的数据直接放到countCells[]数组的空间, 具体写到哪个位置也是用hash来计算的,这个数组一开始长度为2, 如果并发的情况 比较严重会扩容,也是*2 来扩容。最终算len时会把 baseCount + sum(countCells[0...len-1]).
3). CHM 在找数据的时候要先算hash, 在算hash时用了2次hash计算,让数据更加均匀分布。
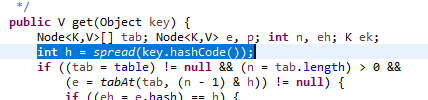
而HashMap 只算了一次Hash
















 225
225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









