







在本文中,我们将对集群版ZooKeeper服务器的启动过程做详细讲解。集群和单机ZooKeeper服务器的启动过程在很多地方都是一致的,因此本节只会对有差异的地方展开进行讲解。下图所示是集群版ZooKeeper服务器的启动流程图。
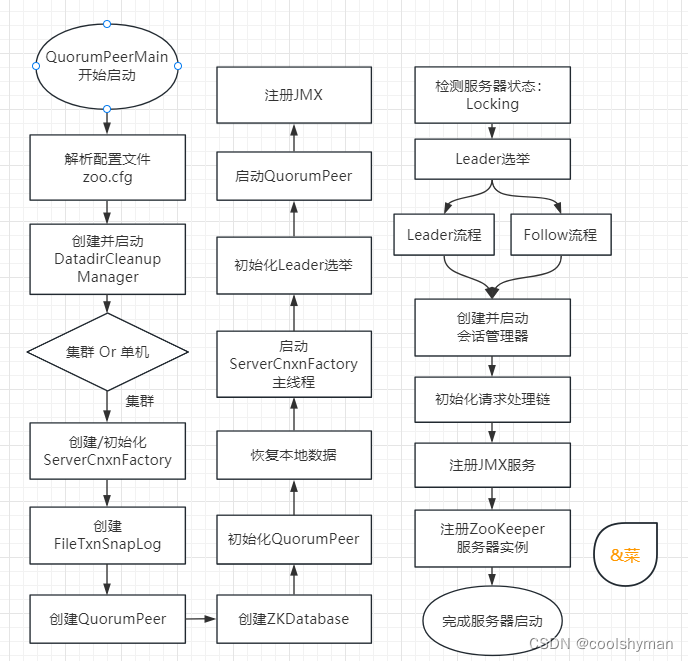
预启动
预启动的步骤如下。
(1)统一由QuorumPeerMain作为启动类。
(2)解析配置文件zoo.cfg。
(3)创建并启动历史文件清理器DatadirCleanupManager。
(4)判断当前是集群模式还是单机模式的启动。
在集群模式中,由于已经在zoo.cfg中配置了多个服务器地址,因此此处选择集群模式启动ZooKeeper。
初始化
初始化的步骤如下。
(1)创建ServerCnxnFactory。
(2)初始化ServerCnxnFactory。
(3)创建ZooKeeper数据管理器FileTxnSnapLog。
(4)创建QuorumPeer实例。
Quorum是集群模式下特有的对象,是ZooKeeper服务器实例(ZooKeeperServer)的托管者,从集群层面看,QuorumPeer代表了ZooKeeper集群中的一台机器。在运行期间,QuorumPeer会不断检测当前服务器实例的运行状态,同时根据情况发起Leader选举。
(5)创建内存数据库ZKDatabase。
ZKDatabase是ZooKeeper的内存数据库,负责管理ZooKeeper的所有会话记录以及DataTree和事务日志的存储。
(6)初始化QuorumPeer。
在步骤5中我们已经提到,QuorumPeer是ZooKeeperServer的托管者,因此需要将一些核心组件注册到QuorumPeer中去,包括FileTxnSnapLog、ServerCnxnFactory和ZKDatabase。同时ZooKeeper还会对QuorumPeer配置一些参数,包括服务器地址列表、Leader选举算法和会话超时时间限制等。
(7)恢复本地数据。
(8)启动ServerCnxnFactory主线程。
Leader选举
Leader选举的步骤如下。
(1)初始化Leader选举。
Leader选举可以说是集群和单机模式启动ZooKeeper最大的不同点。ZooKeeper首先会根据自身的SID (服务器ID)、lastLoggedZxid (最新的ZXID)和当前的服务器epoch(currentEpoch)来生成一个初始化的投票一简单地讲,在初始化过程中,每个服务器都会给自己投票。
然后,ZooKeeper会根据zoo.cfg中的配置,创建相应的Leader选举算法实现。在ZooKeeper中,默认提供了三种Leader选举算法的实现,分别是LeaderElection、AuthFastLeaderElection和FastLeaderElection,可以通过在配置文件(zoo.cfg)中使用electionAlg属性来指定,分别使用数字0~3来表示。从3.4.0版本开始,ZooKeeper废弃了前两种Leader选举算法,只支持FastLeaderElection选举算法了。
在初始化阶段,ZooKeeper会首先创建Leader选举所需的网络I/O层QuorumCnxManager,
同时启动对Leader选举端口的监听,等待集群中其他服务器创建连接。
(2)注册JMX服务。
(3)检测当前服务器状态。
在上文中,我们已经提到QuorumPeer是ZooKeeper服务器实例的托管者,在运行期间,QuorumPeer的核心工作就是不断地检测当前服务器的状态,并做出相应的处理。在正常情况下,ZooKeeper 服务器的状态在LOOKING、LEADING和FOLLOWING/OBSERVING之间进行切换。而在启动阶段,QuorumPeer的初始状态是LOOKING,因此开始进行Leader选举。
(4)Leader选举:
ZooKeeper的Leader选举过程,简单地讲,就是一个集群中所有的机器相互之间进行一系列投票,选举产生最合适的机器成为Leader,同时其余机器成为Follower或是Observer的集群机器角色初始化过程。关于Leader选举算法,简而言之,就是集群中哪个机器处理的数据越新(通常我们根据每个服务器处理过的最大ZXID来比较确定其数据是否更新),其越有可能成为Leader。当然,如果集群中的所有机器处理的ZXID一致的话,那么SID最大的服务器成为Leader。
Leader和Follower启动期交互过程
到这里为止,ZooKeeper已经完成了Leader选举,并且集群中每个服务器都已经确定了自己的角色一通常情况下就分为Leader 和Follower两种角色。下面我们来对Leader和Follower在启动期间的工作原理进行讲解,其大致交互流程如下图所示。
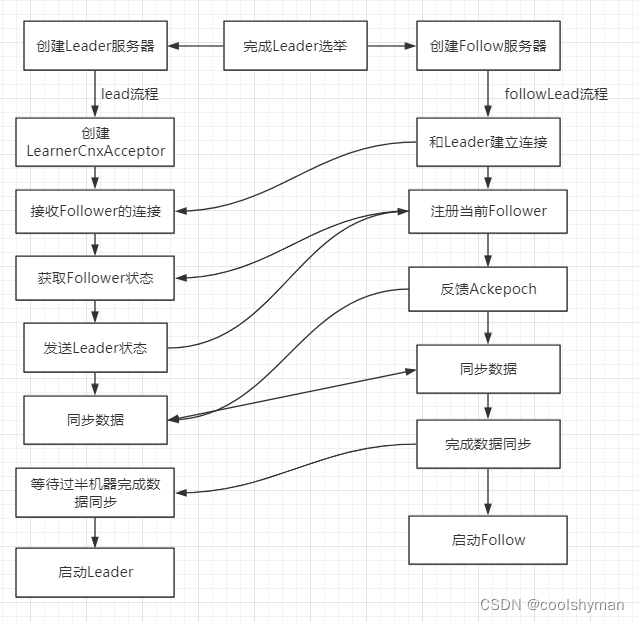
Leader和Follower服务器启动期交互过程包括如下步骤。
(1)创建Leader服务器和Follower服务器。
完成Leader选举之后,每个服务器都会根据自己的服务器角色创建相应的服务器实例,并开始进入各自角色的主流程。
(2)Leader服务器启动Follower接收器LearnerCnxAcceptor。
在ZooKeeper集群运行期间,Leader 服务器需要和所有其余的服务器(本文余下部分,我们使用“Learner”来指代这类机器)保持连接以确定集群的机器存活情况。LearnerCnxAcceptor接收器用于负责接收所有非Leader服务器的连接请求。
(3)Learner服务器开始和Leader建立连接。
所有的Learner服务器在启动完毕后,会从Leader选举的投票结果中找到当前集群中的Leader服务器,然后与其建立连接。
(4)Leader服务器创建LearnerHandler。
Leader接收到来自其他机器的连接创建请求后,会创建一个LearnerHandler实例。每个LearnerHandler实例都对应了一个Leader与Learner服务器之间的连接,其负责Leader和Learner服务器之间几乎所有的消息通信和数据同步。
(5)向Leader注册。
当和Leader建立起连接后,Learner就会开始向Leader进行注册一所谓的注册,其实就是将Learner 服务器自己的基本信息发送给Leader 服务器,我们称之为LearnerInfo,包括当前服务器的SID和服务器处理的最新的ZXID。
(6)Leader解析Learner信息,计算新的epoch。
Leader服务器在接收到Learner的基本信息后,会解析出该Learner的SID和ZXID,然后根据该Learner的ZXID解析出其对应的epoch_of_learner,和当前Leader服务器的epoch_of_leader进行比较,如果该Learner的epoch_of_learner更大的话,那么就更新Leader的epoch:
epoch_of_leader = epoch_of_learner + 1
然后,LearnerHandler会进行等待,直到过半的Learner已经向Leader 进行了注册,同时更新了epoch_of_leader之后,Leader就可以确定当前集群的epoch了。
(7)发送Leader状态。
计算出新的epoch之后,Leader会将该信息以一个LEADERINFO消息的形式发送给Learner,同时等待Learner的响应。
(8)Learner发送ACK消息。
Follower在收到来自Leader的LEADERINFO消息后,会解析出epoch和ZXID,然后向Leader反馈一个ACKEPOCH响应。
(9)数据同步。
Leader服务器接收到Learner的这个ACK消息后,就可以开始与其进行数据同步了。
(10)启动Leader和Learner服务器。
当有过半的Learner已经完成了数据同步,那么Leader和Learner服务器实例就可以开始启动了。
Leader和Follower启动
Leader和Follower启动的步骤如下。
(1)创建并启动会话管理器。
(2)初始化ZooKeeper的请求处理链。
和单机版服务器一样,集群模式下,每个服务器都会在启动阶段串联请求处理链,只是根据服务器角色不同,会有不同的请求处理链路。
(3)注册JMX服务。
至此,集群ZooKeeper服务器启动完毕。















 1419
1419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









