






1.实验要求
输入上下文无关文法,对给定的输入串,给出其 LR (0)分析过程及正确与否的 判断
2.完整代码
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#define STACK_CHAR_SIZE 100 //栈的大小
#define N 100
typedef struct //同步状态与符号
{
int state;
char symbol;
}syn;
typedef struct //定义栈的结构体
{
syn* base;
syn* top;
int stacksize;
} SqStack;
char gramOldSet[200][200]; //原始文法的产生式
char terSymbol[N]; //终结符
char nterSymbol[N]; //非终结符
int lenGramStr = 0; //产生式的句数
int lenTerStr = 0; //终结符数组的长度
int lenNTerStr = 0; //非终结符数组的长度
int pjIndex; //项目集个数
typedef struct {
char m[N]; //项目集的产生式
char symbol; //.右部符号,即产生式待移进字符
int nextState; //待移进项目集:nextState>0,为action(状态,字符)对应状态,此时r=0 (归约项目集I1除外,nextState=0,r=0)
int r; //归约项目集:nextState=0, 此时r>0为待归约的文法产生式序号 (归约项目集I1除外)
int point; //‘.’在产生式右部的位置下标,‘.’在下标对应字符前面
int length; //产生式的长度
}sentence;
typedef struct {
int num; //项目集产生式数量
sentence st[20];
}project;
project pj[20];//项目
void InitStack(SqStack* S)//初始化
{
S->base = (syn*)malloc(STACK_CHAR_SIZE * sizeof(syn));
if (!S->base)
{
printf("无法创建堆栈!\n");
exit(0);
}
S->top = S->base;
S->stacksize = STACK_CHAR_SIZE;
}
void Push(SqStack* S, syn e) //将元素压入堆栈
{
S->top->state = e.state;
S->top->symbol = e.symbol;
*S->top++;
}
void Pop(SqStack* S) //将栈顶元素弹出
{
if (S->top == S->base);
else --S->top;
}
int IsTerOrNon(char c) //区分是终结符还是非终结符
{
if (c >= 'A' && c <= 'Z')
return 1; //表示是非终结符
else if (c == '@' || c == '|' || c == ' ' || c == '\n' || c == '\r' || c == '\0' || c == '>')
return 0; //表示一些无关的元素,根据实验需要进行添加
else
return 2; //表示是终结符
}
int HaveChar(char str[], char c) //判断数组中是否含有字符c
{
int i = 0;
while (str[i] != '\0') {
if (c == str[i]) return 1;
i++;
}
return 0;
}
void ReadFile(char s[]) //从文件中读取产生式
{
char temp[N]; //临时数组,用于读文件存放每行产生式
int index ; //产生式数组下标
int index_temp ; //临时数组的下标
FILE* fp;
fp = fopen(s, "r");
if (fp != NULL)
{
printf("文件中的产生式为\n");
while (fgets(temp, N, fp) != NULL) //fgets()按行读取每句产生式
{
printf("%s", temp); //temp数组包括换行符
index_temp = 3;
//从产生式右部识别字符,并写入终结符与非终结符数组
while (temp[index_temp] != '\0')
{
if (IsTerOrNon(temp[index_temp]) == 1)
{
if (!HaveChar(nterSymbol, temp[index_temp])) nterSymbol[lenNTerStr++] = temp[index_temp];
}
else if (IsTerOrNon(temp[index_temp]) == 2)
{
if (!HaveChar(terSymbol, temp[index_temp])) terSymbol[lenTerStr++] = temp[index_temp];
}
index_temp++;
}
nterSymbol[lenNTerStr] = '\0';
terSymbol[lenTerStr] = '\0';
//写入产生式数组
index_temp = 3;
index = 3;
gramOldSet[lenGramStr][0] = temp[0];
gramOldSet[lenGramStr][1] = '-';
gramOldSet[lenGramStr][2] = '>';
while (temp[index_temp] != '\0')
{
if (temp[index_temp] == '\n' || temp[index_temp] == '\r')
{
gramOldSet[lenGramStr++][index] = '\0'; //每个产生式都以'\0'结尾,方便后面的遍历
break;
}
else if (temp[index_temp] == '|')
{
index_temp++;
gramOldSet[lenGramStr][index] = '\0';
lenGramStr++;
gramOldSet[lenGramStr][0] = temp[0];
gramOldSet[lenGramStr][1] = '-';
gramOldSet[lenGramStr][2] = '>';
index = 3;
}
gramOldSet[lenGramStr][index++] = temp[index_temp++];
}
}
gramOldSet[lenGramStr++][index] = '\0'; //遍历到最后,那么最后一个产生式还没有加上'\0'
}
else {
printf("文件无法打开!");
}
printf("\n处理过的产生式为\n");
for (int i = 0; i < lenGramStr; i++) {
printf("%s\n", gramOldSet[i]);
}
printf("终结符都有:\n");
for (int i = 0; i < lenTerStr; i++) {
printf("%c ", terSymbol[i]);
}
printf("\n非终结符都有:\n");
for (int i = 0; i < lenNTerStr; i++) {
printf("%c ", nterSymbol[i]);
}
printf("\n");
}
int QueryLen(char str[]) {
int i = 0;
while (str[i] != '\0')i++;
return i;
}
void ExtentSt() //扩大项目集的产生式
{
int flag2 = 1;
int tempNum = 0;
int k = 0;
int stIndex = 1;
int tempMark[10]= {0,0,0,0,0,0,0,0,0,0};
tempMark[0] = -1; //防止出现左递归,造成项目集死循环
while (flag2)
{
flag2 = 0;
for (k = tempNum; k < pj[pjIndex - 1].num; k++)
{
if (k == tempNum) tempNum = pj[pjIndex - 1].num;
if (IsTerOrNon(pj[pjIndex - 1].st[k].symbol) == 1&&tempMark[k]!=k)
{
for (int t = 0; t < lenGramStr; t++)
{
if (pj[pjIndex - 1].st[k].symbol == gramOldSet[t][0])
{
strcpy(pj[pjIndex - 1].st[stIndex].m, gramOldSet[t]);
pj[pjIndex - 1].st[stIndex].point = 3;
pj[pjIndex - 1].st[stIndex].length = QueryLen(gramOldSet[t]);
pj[pjIndex - 1].st[stIndex].symbol = gramOldSet[t][3];
pj[pjIndex - 1].num++;
stIndex++;
flag2 = 1;
}
char temp1 = pj[pjIndex - 1].st[stIndex - 1].m[0];
char temp2 = pj[pjIndex - 1].st[stIndex - 1].m[3];
if (temp1 == temp2) tempMark[stIndex - 1] = stIndex - 1; //产生式可能出现多次左递归的情况,如A->.Ab,A->.Ac......
}
}
}
}
}
int IsRepeat() //判断项目集是否重复
{
for (int t = 0; t < pjIndex - 1; t++)
{
int test = 0;
for (int x = 0; x < pj[t].num; x++)
{
for (int k = 0; k < pj[pjIndex - 1].num; k++)
{
if (strcmp(pj[pjIndex - 1].st[k].m, pj[t].st[x].m) == 0 && pj[pjIndex - 1].st[k].point == pj[t].st[x].point) test++;
}
}
if ( pj[pjIndex - 1].num==test) //项目集t包含项目集pjIndex-1的所有产生式
{
pjIndex--;
return t;
}
}
return pjIndex-1;
}
void CreatProject()
{
strcpy(pj[0].st[0].m, gramOldSet[0]);
pj[0].st[0].point = 3;
pj[0].st[0].symbol = gramOldSet[0][3];
pj[0].st[0].length = QueryLen(gramOldSet[0]);
pj[0].num = 1;
pjIndex = 1;
ExtentSt(); //扩大项目集的产生式
int flag1 = 1; //循环标志
int temp_pjIndex = 0; //当前项目集个数
int temp_num=0; //上一遍循环开始前的项目集个数,不包括新产生的
while (flag1)
{
flag1 = 0;
temp_pjIndex = pjIndex;
for (int i = temp_num; i < temp_pjIndex; i++) //对新产生的项目集进行扩展,从而产生新的项目集
{
if (i == temp_num) temp_num = temp_pjIndex;
int mark[10] = {-1,-1,-1,-1,-1,-1,-1,-1,-1,-1}; //用于判断项目集不同产生式是否有相同待移进符号,如s->a.AbcBe,A->.b,A->.Ab
int synPjIndex[10] = { 0,0,0,0,0,0,0,0,0,0 }; //记录不同产生式对应的项目集
for (int j = 0; j < pj[i].num-1; j++)
{
for (int k = j+1; k < pj[i].num; k++)
{
if (pj[i].st[j].symbol == pj[i].st[k].symbol)
{
if(mark[k] == -1) mark[k] = j; //若有多个产生式有相同移进符号,只记录第一个产生式
}
}
}
for (int j = 0; j < pj[i].num; j++) //对每个新产生项目集的产生式进行扩展,转移到下一个项目集
{
int temp = pj[i].st[j].point;
temp +=1;
//扩展后的产生式为归约项目,则下一个项目集是归约项目集
if (temp == pj[i].st[j].length)
{
strcpy(pj[pjIndex].st[0].m, pj[i].st[j].m);
pj[pjIndex].st[0].point = temp;
pj[pjIndex].st[0].length = temp;
pj[pjIndex].st[0].nextState = 0;
pj[pjIndex].num = 1;
pj[pjIndex].st[0].symbol = '@';
pj[i].st[j].nextState = pjIndex; //即action(i,pj[i].st[j].symbol)=pj[i].st[j].nextState
for (int k = 0; k < lenGramStr; k++)
{
if (strcmp(pj[pjIndex].st[0].m,gramOldSet[k])==0) pj[pjIndex].st[0].r = k;
}
if (pjIndex == 1) pj[pjIndex].st[0].symbol = '#'; //I1为最终规约项目
pjIndex++;
synPjIndex[j] = pjIndex - 1;
//判断产生的项目集是否与之前的重复
pj[i].st[j].nextState = IsRepeat();
}
else if(temp< pj[i].st[j].length) //扩展后的产生式为待约项目,则下一个项目集是待约项目集
{
flag1 = 1;
strcpy(pj[pjIndex].st[0].m, pj[i].st[j].m);
pj[pjIndex].st[0].point = temp;
pj[pjIndex].st[0].length = pj[i].st[j].length;
pj[pjIndex].st[0].symbol = pj[pjIndex].st[0].m[temp];
pj[pjIndex].num=1;
pj[i].st[j].nextState = pjIndex;
pjIndex++;
ExtentSt(); //扩大项目集的产生式
synPjIndex[j] = pjIndex - 1;
//判断产生的项目集是否与之前的重复
pj[i].st[j].nextState = IsRepeat();
//与前面的产生式有相同移进符号,且产生的项目集与之前所有的项目集不重复
//若有不同产生式有相同移进符号,把相同移进符号的后续项目集合并到为一个
if (mark[j] >= 0&& pj[i].st[j].nextState == synPjIndex[j])
{
int tempPjIndex = synPjIndex[mark[j]];
int tempStIndex = pj[tempPjIndex].num;
for (int k = 0; k < pj[pjIndex - 1].num; k++)
{
strcpy(pj[tempPjIndex].st[tempStIndex + k].m, pj[pjIndex-1].st[k].m);
pj[tempPjIndex].st[tempStIndex + k].point = pj[pjIndex - 1].st[k].point;
pj[tempPjIndex].st[tempStIndex + k].length = pj[pjIndex - 1].st[k].length;
pj[tempPjIndex].st[tempStIndex + k].symbol = pj[pjIndex - 1].st[k].symbol;
pj[tempPjIndex].num++;
pj[i].st[j].nextState = tempPjIndex;
}
//pj[tempPjIndex].num = pj[tempPjIndex].num + pj[pjIndex - 1].num;
synPjIndex[j] = tempPjIndex;
pjIndex--;
}
}
}
}
}
for (int i = 0; i < pjIndex; i++)
{
printf("项目I%d:\n",i);
for (int j = 0; j < pj[i].num; j++)
{
for (int k = 0; k < pj[i].st[j].length; k++)
{
if (pj[i].st[j].point == k) printf(".");
printf("%c", pj[i].st[j].m[k]);
}
if (pj[i].st[j].point == pj[i].st[j].length) printf(".");
printf("\n");
}
printf("\n");
}
}
void Display() //输出LR(0)分析表
{
terSymbol[lenTerStr++] = '#';
printf("状态\t");
for (int i = 0; i < lenTerStr; i++) printf("%c\t", terSymbol[i]);
for (int i = 0; i < lenNTerStr; i++) printf("%c\t", nterSymbol[i]);
printf("\n-----------------------------------------------------------------\n");
for (int i = 0; i < pjIndex; i++) //按行遍历每个项目集,找到与文法字符匹配的产生式,并在对应字符下方输出该产生式的下一个状态
{
int temp = 0;
printf("%d\t", i);
if (pj[i].st[0].symbol == '@') //待归约项目集只有一条产生式 ,情况最简单先输出(移进-归约,归约-归约冲突)
{
for (int k = 0; k < lenTerStr; k++)
{
printf("r%d\t", pj[i].st[0].r);
}
temp = 1;
printf("\n-----------------------------------------------------------------\n");
continue; //跳转下一个循环,不再执行下面语句
}
for (int k = 0; k < lenTerStr; k++) //匹配文法字符的为终结符
{
temp = 0;
for (int j = 0; j < pj[i].num; j++)
{
if (terSymbol[k] == pj[i].st[j].symbol)
{
if (i == 1) printf("acc\t");
else printf("s%d\t", pj[i].st[j].nextState);
temp = 1;
break;
}
}
if (temp == 0) printf("\t"); //terSymbol[k]未找到,则输入制表符
}
for (int k = 0; k < lenNTerStr; k++) //匹配文法字符的为非终结符,
{
temp = 0;
for (int j = 0; j < pj[i].num; j++)
{
if (nterSymbol[k] == pj[i].st[j].symbol)
{
printf("%d\t", pj[i].st[j].nextState);
temp = 1;
break;
}
}
if (temp == 0) printf("\t");
}
printf("\n-----------------------------------------------------------------\n");
}
}
void Control(char str[])
{
printf("状态栈\t\t符号栈\t\t输入串\t\tACTION\t\tGOTO\n");
SqStack* stack = (SqStack*)malloc(sizeof(SqStack));
InitStack(stack);
syn sn = { 0,'#' };
Push(stack, sn);
int depth = 0; //栈的深度
int pointer = 0; //字符串下标
int flag = 1; //用于退出下面循环
int tempState = 0; //每次操作前的状态序号,初始为0
while (flag)
{
for (int i = 0; i <= depth; i++) //每次移位或归约前顺序输出状态栈
{
syn* temp = stack->base + i;
printf("%d", temp->state);
}
printf("\t\t");
for (int i = 0; i <= depth; i++) //顺序输出符号栈
{
syn* temp = stack->base + i;
printf("%c", temp->symbol);
}
printf("\t\t");
int n = pointer;
while (str[n] != '\0') //输出未入栈的字符串
{
printf("%c", str[n++]);
}
printf("\t\t");
int mark = 0; //用于出错处理标志
for (int i = 0; i < pj[tempState].num; i++) //遍历tempState的项目集,寻找待入栈字符对应的产生式
{
// 如果action(状态,字符)=S类型,则执行入栈操作
if (str[pointer] == pj[tempState].st[i].symbol&& pj[tempState].st[i].nextState>0)
{
tempState = pj[tempState].st[i].nextState; //tempState为项目集pj[tempState]面对待入栈字符的下一个项目集,也就是下一个操作对应的状态
sn.state = tempState;
sn.symbol = str[pointer];
Push(stack, sn);
depth++;
pointer++;
printf("S%d\t\t", tempState);
mark = 1;
break;
}
//如果action(状态,字符) = r类型,则执行归约操作
else if (pj[tempState].st[0].symbol == '@' && pj[tempState].st[i].nextState == 0)
{ //待归约项目集只有一条产生式,直接判断是否为待归约状态 (移进-归约,归约-归约冲突)
int tempR = pj[tempState].st[i].r;
printf("r%d\t\t", tempR);
int len = QueryLen(gramOldSet[tempR]) - 3; //出栈个数与归约所用产生式右部字符串长度相同
for (int j = 0; j < len; j++)
{
Pop(stack);
depth--;
} //goto(状态,非终结符),在归约出栈后的栈顶状态符号对应项目集中,查找与归约产生式右部非终结符号
syn* temp = stack->base + depth; //相同的pj[].st[j].symbol,其中pj[].st[j].nextState 即为goto(状态,非终结符)对应的下一个状态
for (int j = 0; j < pj[temp->state].num; j++)
{
if (pj[temp->state].st[j].symbol== gramOldSet[tempR][0]) tempState = pj[temp->state].st[j].nextState;
}
sn.state = tempState;
sn.symbol = gramOldSet[tempR][0];
Push(stack, sn);
depth++;
printf("%d", tempState);
mark = 1;
break;
}
//I1->I0,归约结束
else if (str[pointer] == '#' && tempState==1)
{
flag = 0;
printf("归约成功");
mark = 1;
break;
}
}
if (mark == 0)
{
flag = 0;
printf("归约失败");
}
else printf("\n");
}
}
int main() {
ReadFile("C:\\App\\实验4句型.txt");
CreatProject();
Display();
Control("accd#");
return 0;
}
//S->E
//E->aA | bB
//A->cA | d
//B->cB | d
3.测试
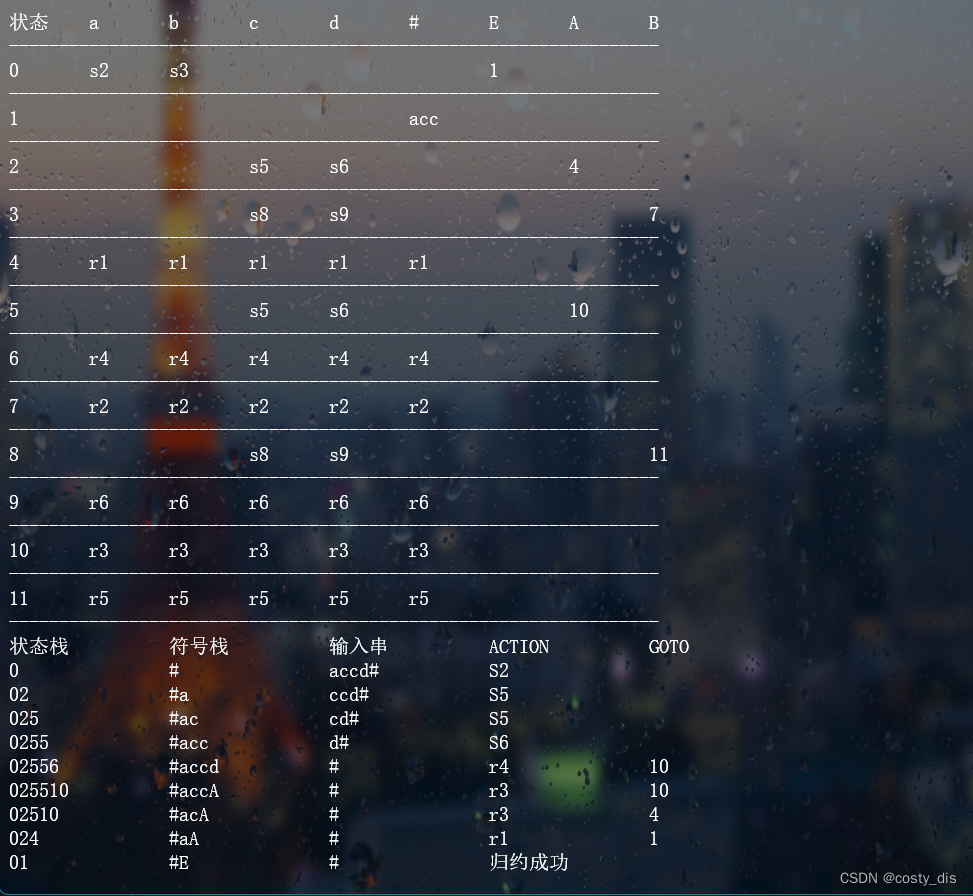
(1)句型:accd
拓广文法:
S->E
E->aA|bB
A->cA|d
B->cB|d
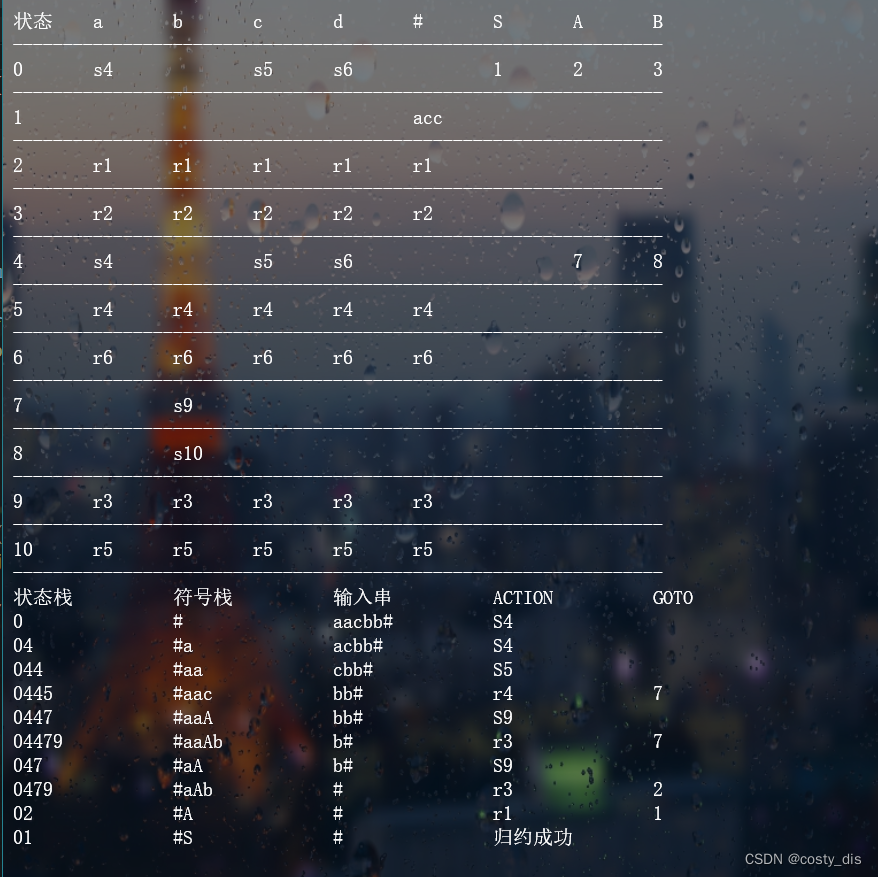
(2)句型:abbcde
拓广文法:
s->S
S->aAcBe
A->b
A->Ab
B->d

(3)句型:aacbb、aadbb
拓广文法:
s->S
S->A
S->B
A->aAb
A->c
B->aBb
B->d
4.问题分析
(1)如何选择数据结构
本次实验选择结构体来实现总控程序的符号与状态同步栈,以及项目集簇,由于总控程序需要实现状态a------->符号------->状态b的状态转换,所以在定义项目集簇的结构体时加入了symbol,nextState,r变量,从而方便实现action(状态,字符),goto(状态,字符)的功能。另外也加入了point变量来体现出活前缀
(2)action与goto
这两个功能主要由项目集簇的结构体来实现,从而省去了这两个函数功能的定义
(3)项目集的扩大

如果项目集新增加的产生式是A->.B/a.B,则说明还会有新的产生式,需要进行循环遍历,直到先增加的产生式不出现该情况,循环结束,项目集才固定下来。
(4)文法出现左递归

在第二个文法测试中,由于有A->Ab的存在,如果不加限制项目集2会无限重复增加A->.b
、A->.Ab。为此在项目集的扩大的过程中,对出现左递归的产生式进行标记,使其不会加入到下面的循环,所以不会进一步增加产生式。
(5)项目集不同产生式有相同待移进符号
同样在第二个文法测试中,项目I2的在接受字符A后,如果不限制,就会生成两个不同的项目集,但是一个项目集在接受一个字符后的下一个状态应该是唯一的,所以需要把接受字符A后生成的两个项目集合并在一个,也就是项目I3。
(6)项目集重复

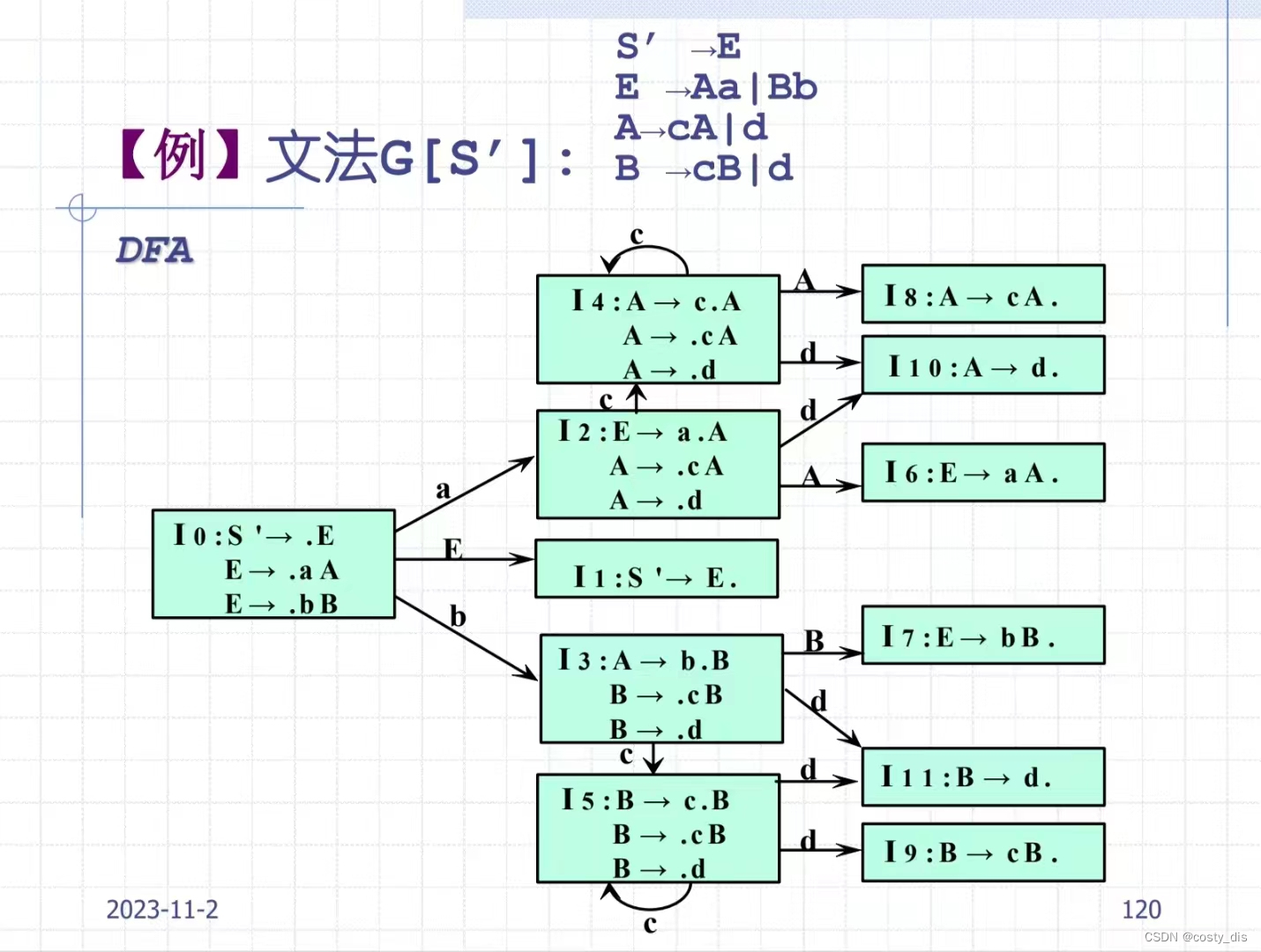
在第3个文法测试中,项目I4的2,5在接受a后生成的项目集的所有产生式已经在原有项目中存在,所以要新把产生的项目集给删除,不然就会重复添加显得很多余
下面是文法1的DNF,对项目集的重复应该更直观些,I4,I10,I5.I11就是例子















 722
722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









