







 本文详细介绍了Trie数据结构,又称字典树或前缀树,用于高效地存储和检索具有公共前缀的字符串。通过一个具体的Trie类实现,包括插入、搜索和检查前缀等方法,展示了其简洁的设计思想。Trie结构减少了查找和前缀匹配的时间复杂度,广泛应用于搜索引擎、自动补全等功能。
本文详细介绍了Trie数据结构,又称字典树或前缀树,用于高效地存储和检索具有公共前缀的字符串。通过一个具体的Trie类实现,包括插入、搜索和检查前缀等方法,展示了其简洁的设计思想。Trie结构减少了查找和前缀匹配的时间复杂度,广泛应用于搜索引擎、自动补全等功能。
Trie数据结构介绍:
具有相同前缀的字符串使用公共前缀。
下图为存储了字符串"app", “apps” , “pe” 的字典树结构图
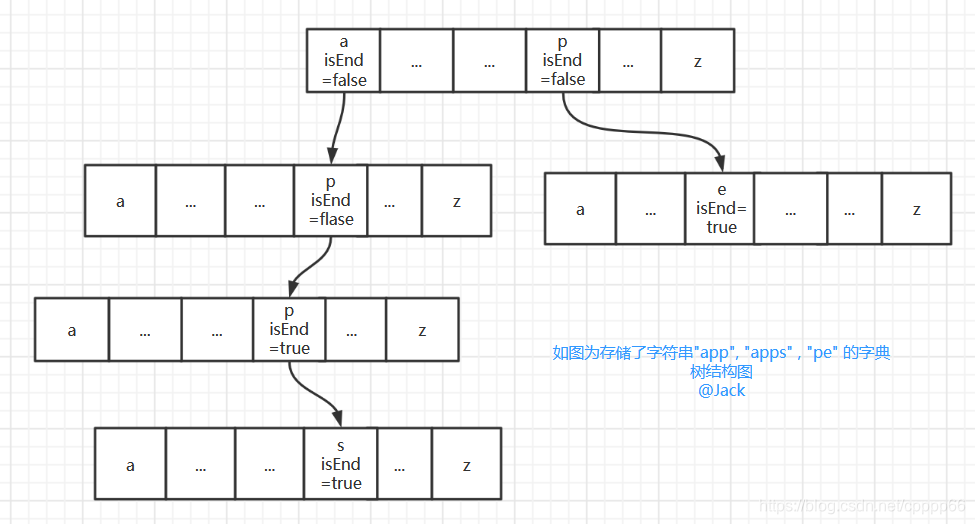
所以设计时,每个Trie类都有个children属性和isEnd属性
- children是个Trie数组(无参构造时初始化大小为26,对应26个字母)
- isEnd属性记录此结点是否是字符串的结尾
Note:
..结点若未被字符串使用,则未被构造,为null
正式实现代码:
class Trie {
private Trie[] children;
private boolean isEnd;
/** Initialize data structure */
public Trie() {
children = new Trie[26]; //每一层需要26个Trie结点(字母)
isEnd = false; //记录此结点是否是字符串的结尾
}
/** Inserts a word into the trie. */
public void insert(String word) {
Trie node = this; //利用反射获取本类Trie来插入
for (int i = 0; i < word.length(); i++) {
char ch = word.charAt(i);
int index = ch - 'a';
if (node.children[index] == null) { //如果这个结点还未成为前缀的一部分,就开通
node.children[index] = new Trie();
}
node = node.children[index]; //不断往下进入
}
node.isEnd = true; //这是结尾
}
/** Returns if the word is in the trie. */
public boolean search(String word) {
Trie node = searchPrefix(word);
return node != null && node.isEnd; // word字符串结尾字符非空 且 是结尾
}
/** Returns if there is any word in the trie that starts with the given prefix. */
public boolean startsWith(String prefix) {
return searchPrefix(prefix) != null;
}
private Trie searchPrefix(String prefix) {
Trie node = this;
for (int i = 0; i < prefix.length(); i++) {
char ch = prefix.charAt(i);
int index = ch - 'a';
if (node.children[index] == null) { //如果有结点未开通说明此前缀不存在
return null;
}
node = node.children[index]; //不断往下
}
return node; //返回一个字符串结尾字符的结点
}
}
由于search(String word)与
boolean startsWith(String prefix)都需要进行寻找前缀的工作,所以将内容抽取出来写成
Trie searchPrefix()
可以减少代码量,这是一种简洁的思想。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









