







1.图(graph)
1.1图的概念
- 图的构成:
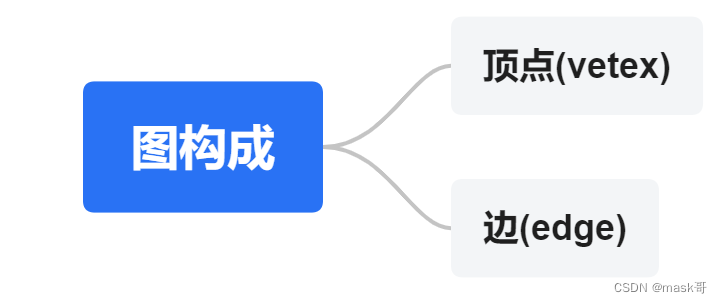
将图G抽象的表示为一组顶点V和一组边E的集合。eg:一个包含5个顶点和7条边的图。
V={1,2,3,4,5}
E={(1,2),(1,3),(1,5),(2,3),(2,4),(4,5)}
G={V,E}
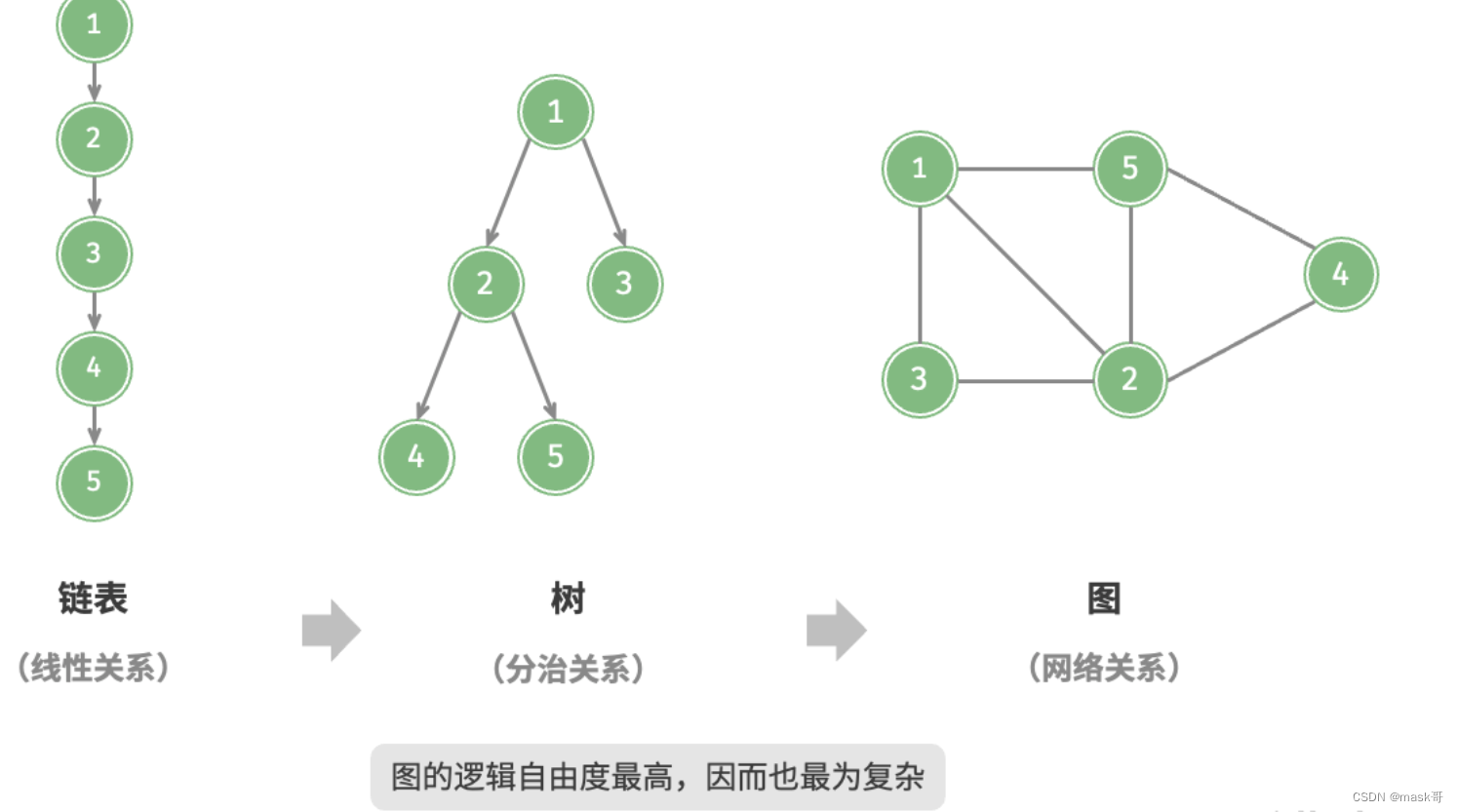
可以将图看作一种从链表拓展而来的数据结构
- 链表、树、图之间的关系:
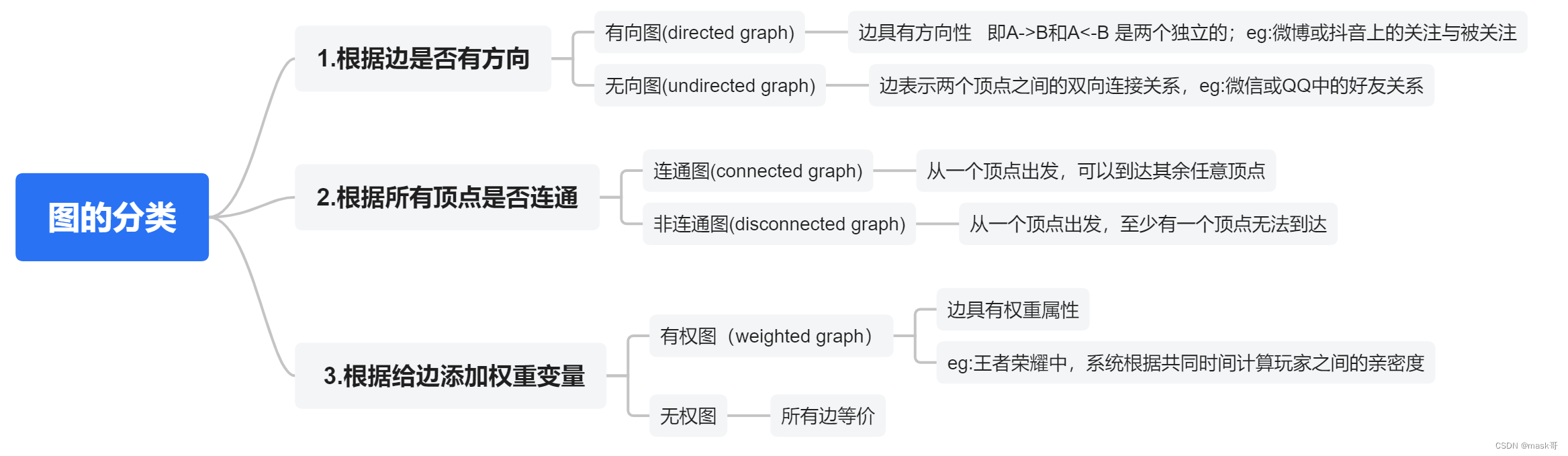
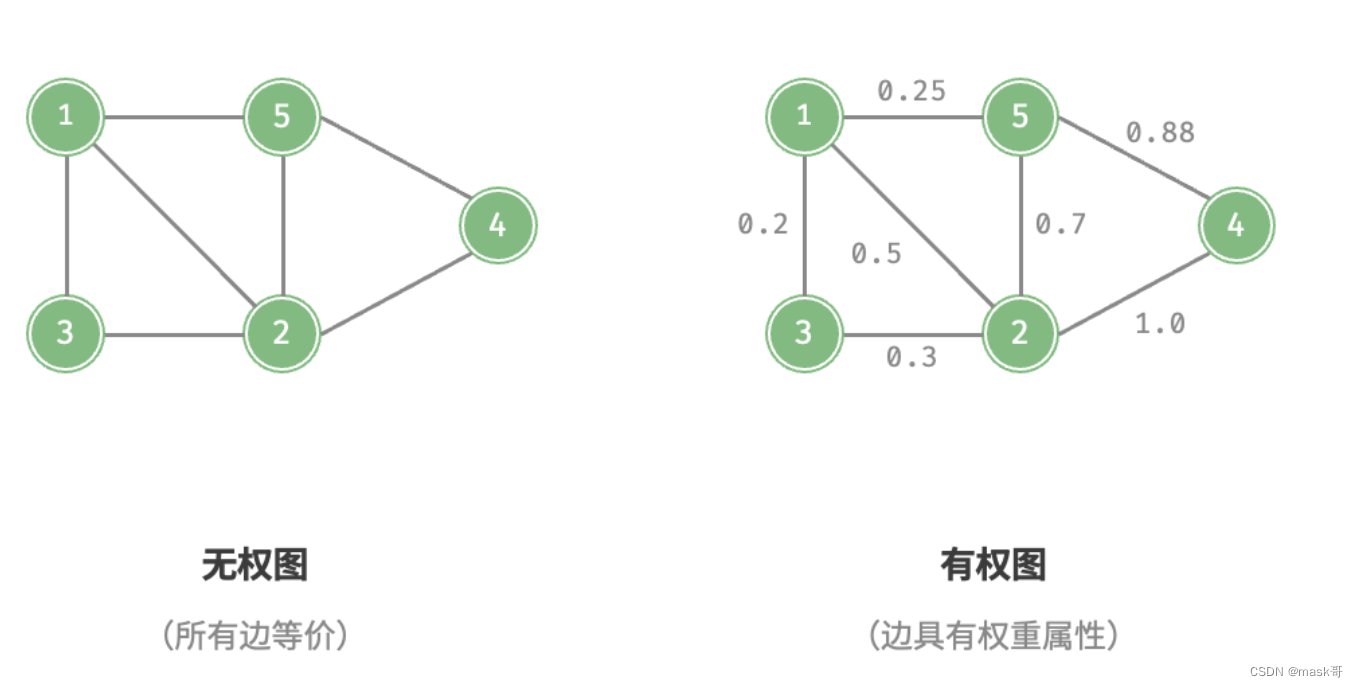
- 图的分类:


-
图常用术语
1.邻接(adjacency):当两顶点之间存在边相连时,称这两顶点“邻接". 如上图顶点 1 的邻接顶点为顶点 2、3、5。
2.路径(path):从顶点 A 到顶点 B 经过的边构成的序列被称为从 A 到 B 的“路径”.如上图:边序列 1-5-2-4 是顶点 1 到顶点 4 的一条路径。3.度(degree):一个顶点拥有的边数.对于有向图,入度 (in-degree)表示有多少条边指向该顶点,出度 (out-degree)表示有多少条边从该顶点指出。
-
图的表示
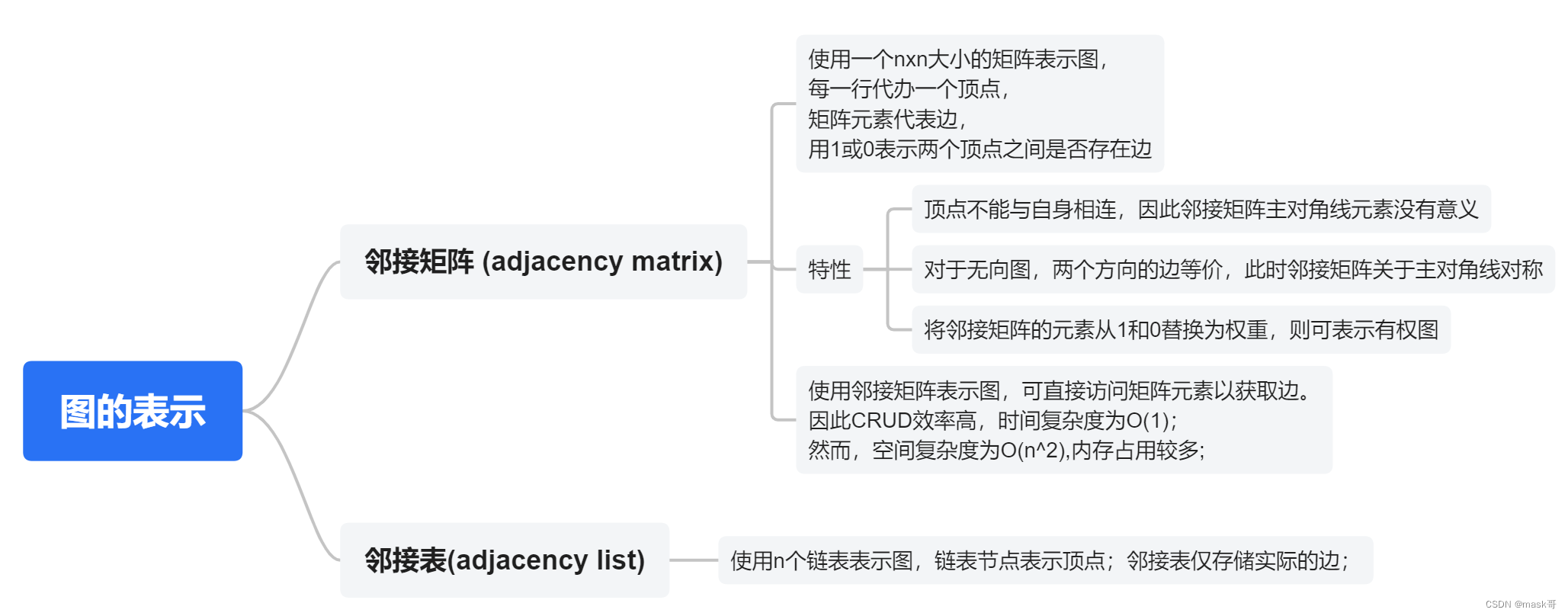
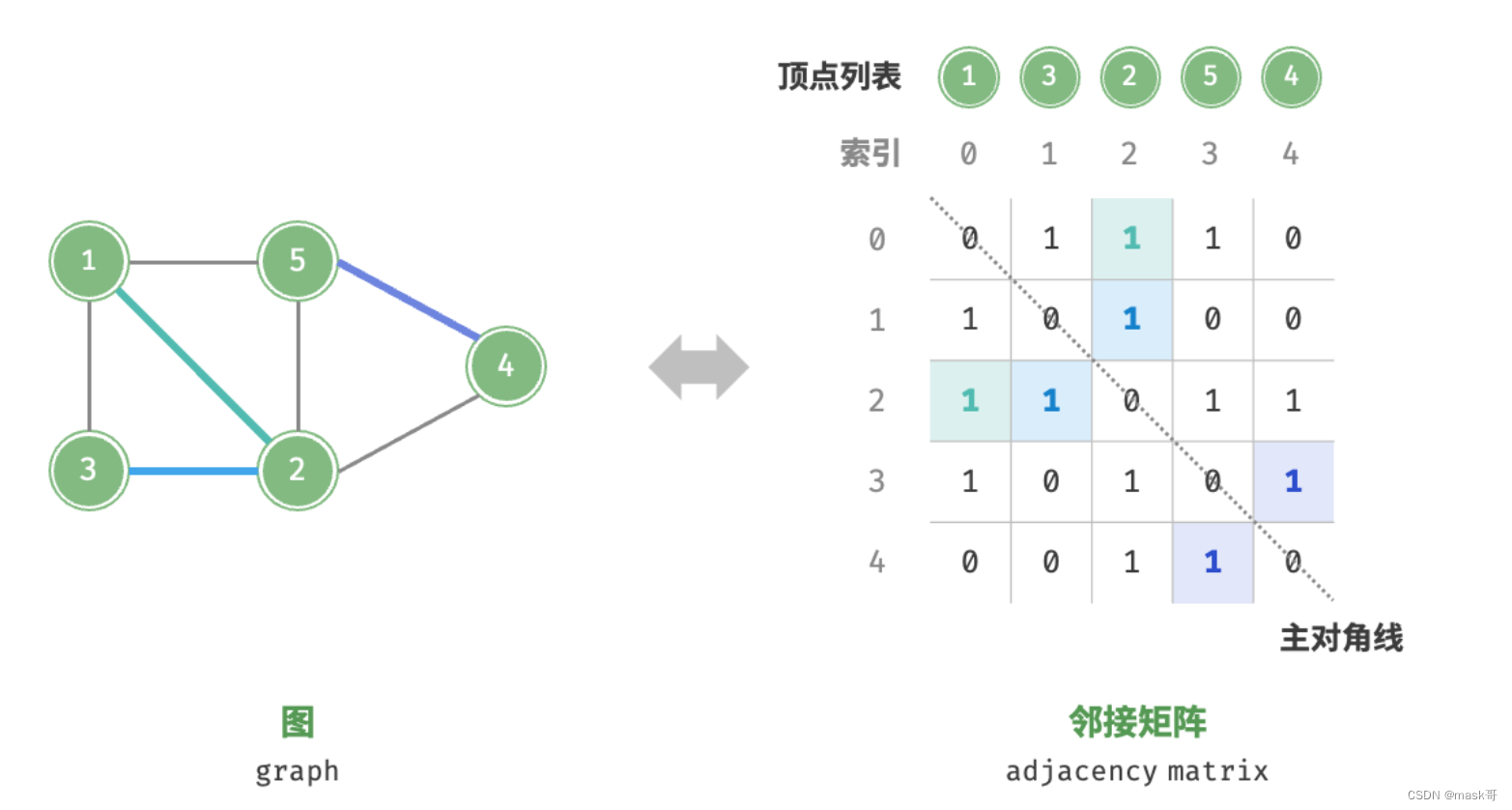

图的操作分为对 "边"的操作和对“顶点”的操作
-
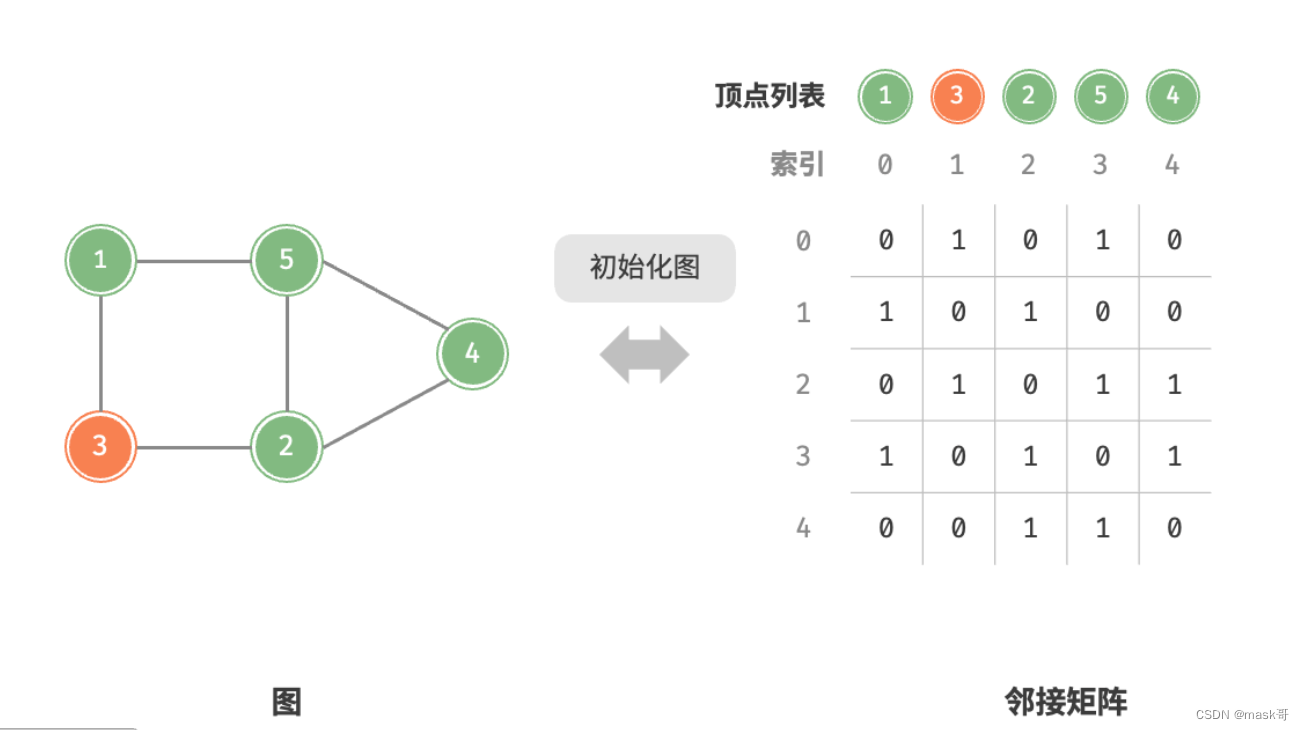
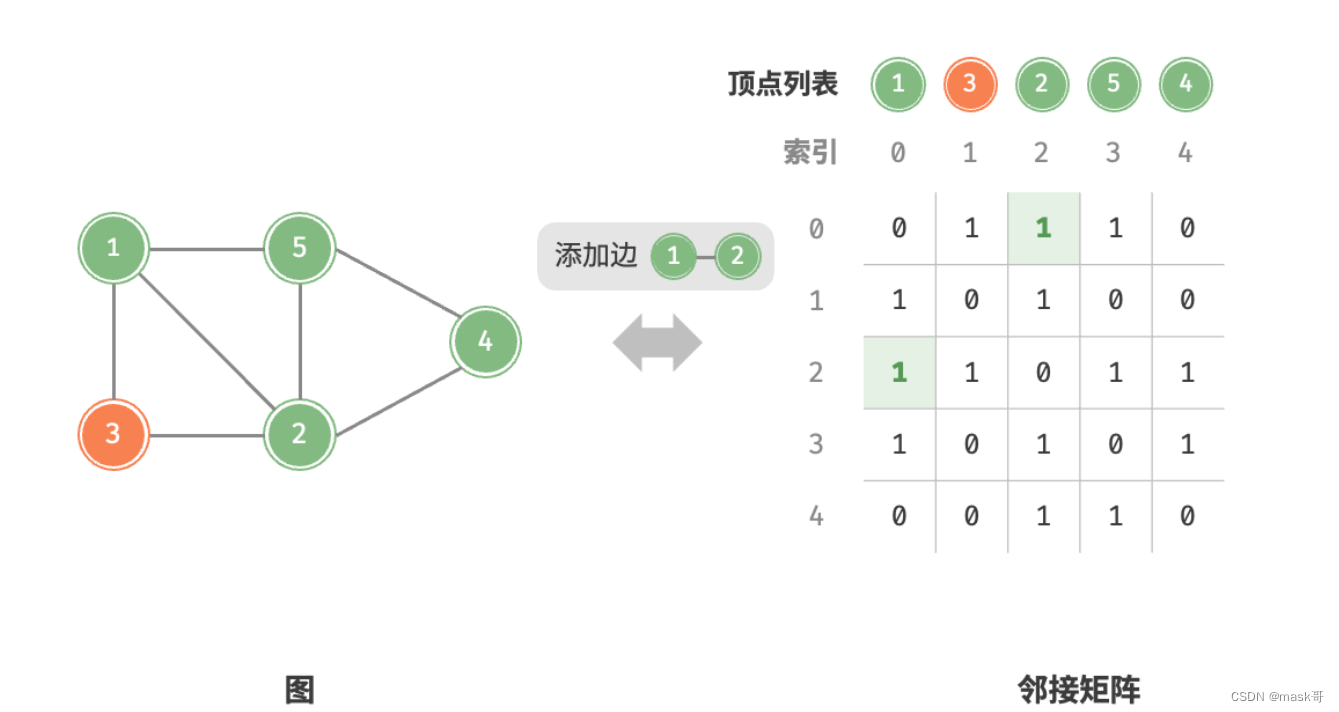
基于邻接矩阵的实现
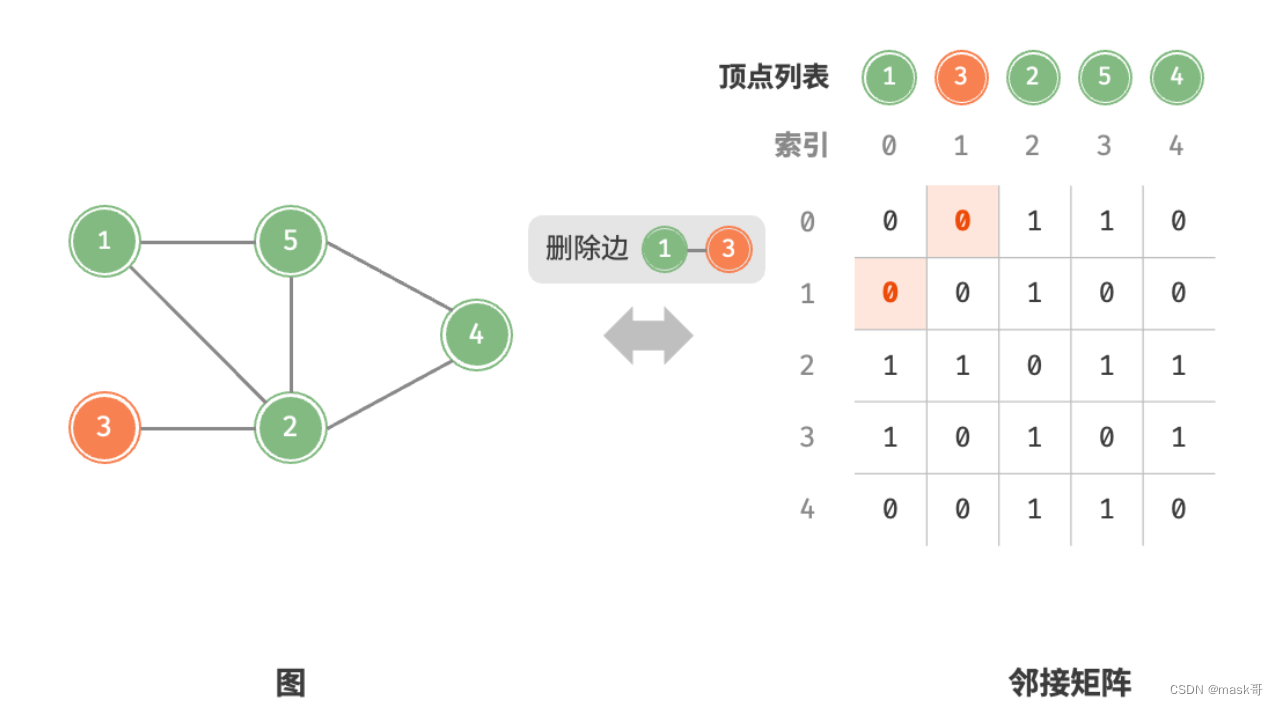
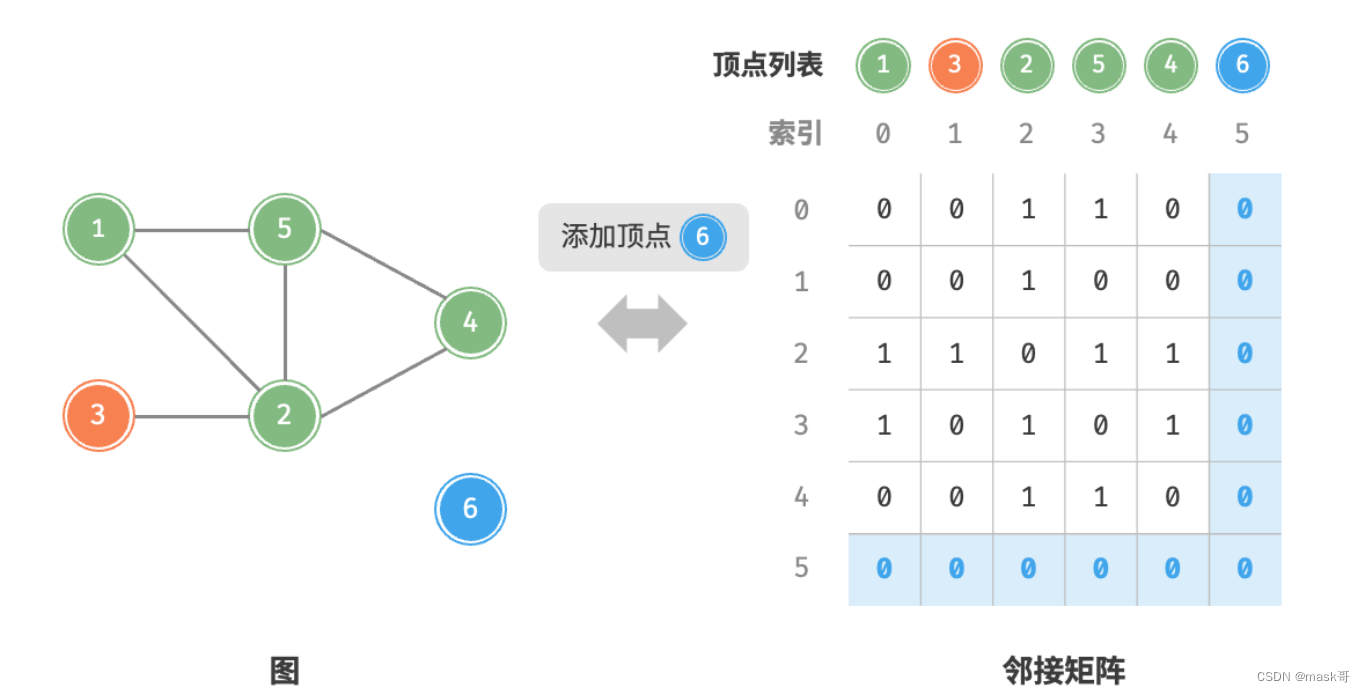
- 基于邻接表的实现
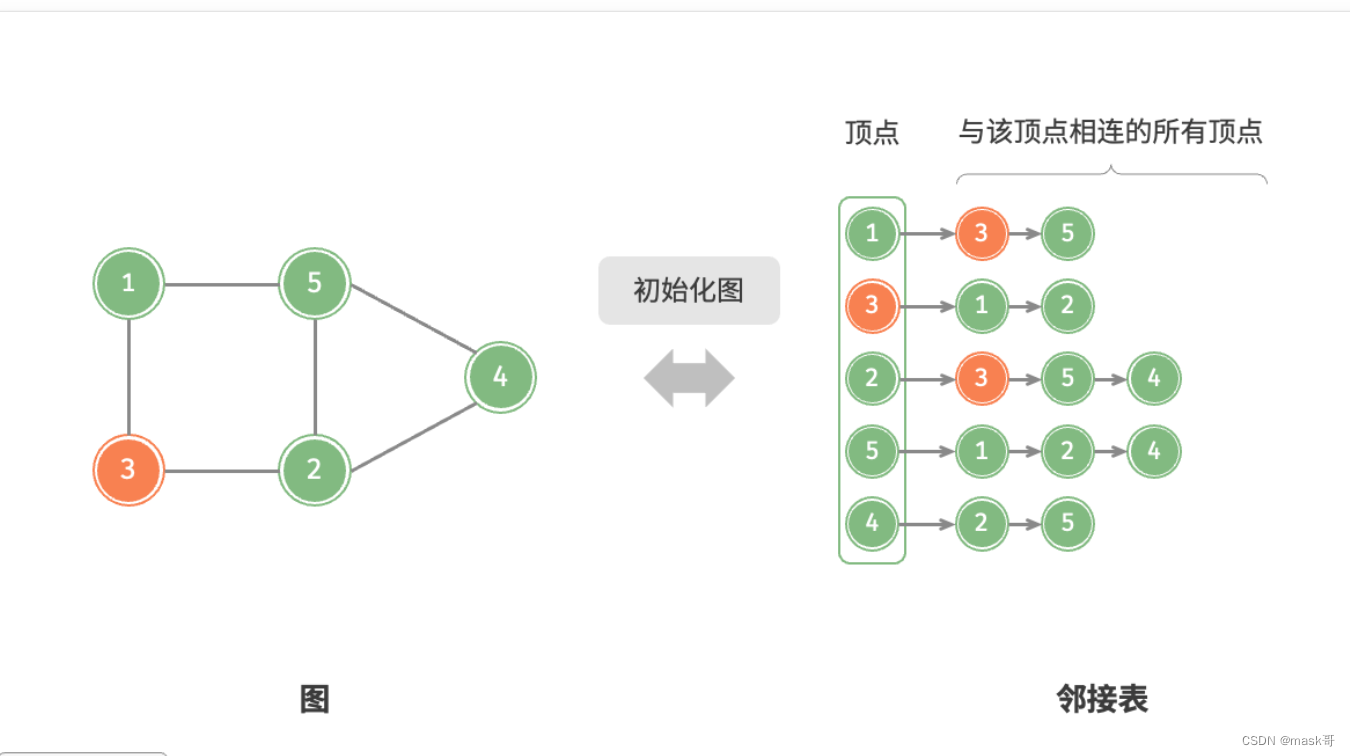

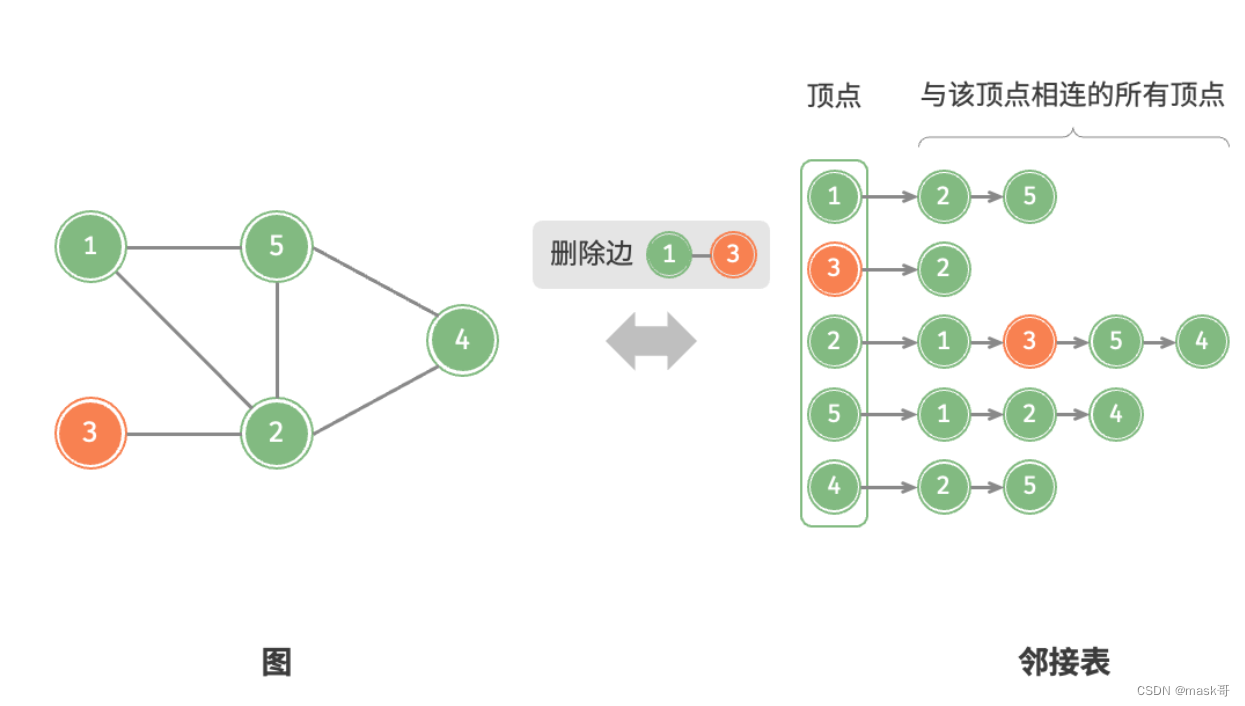
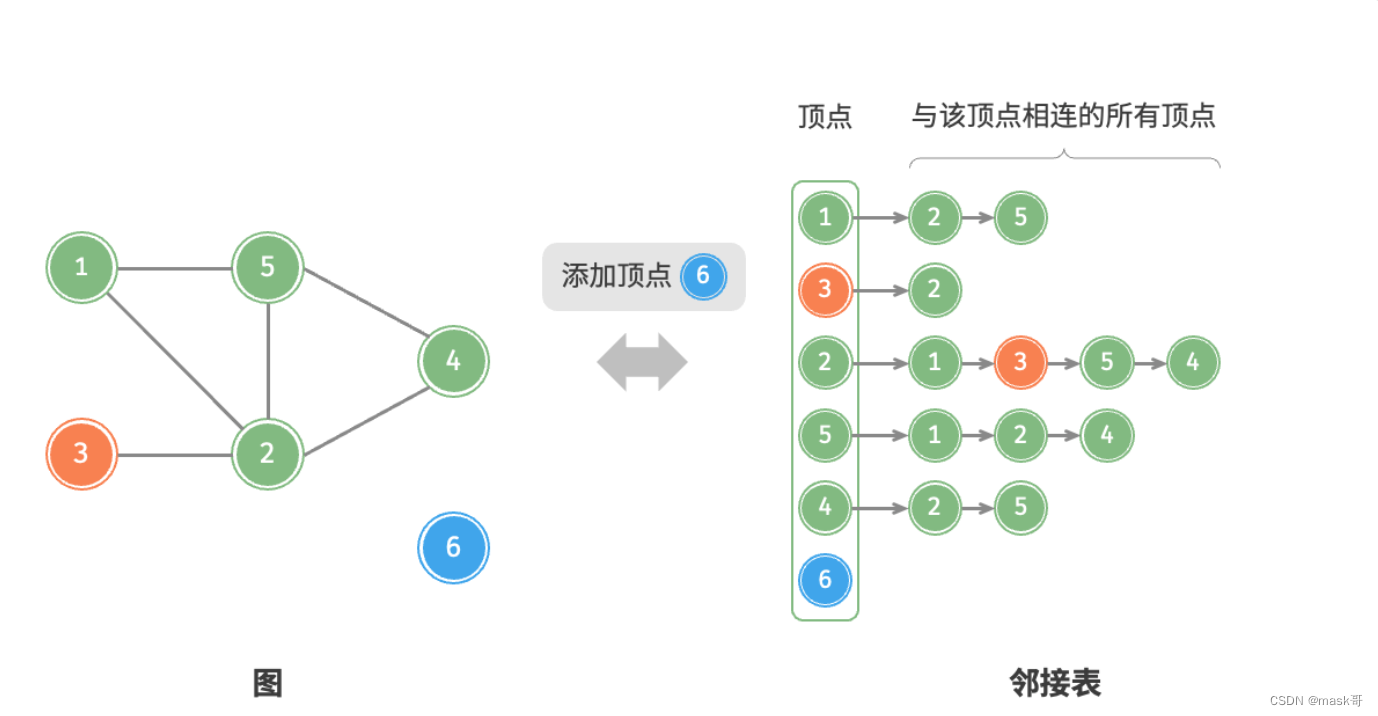
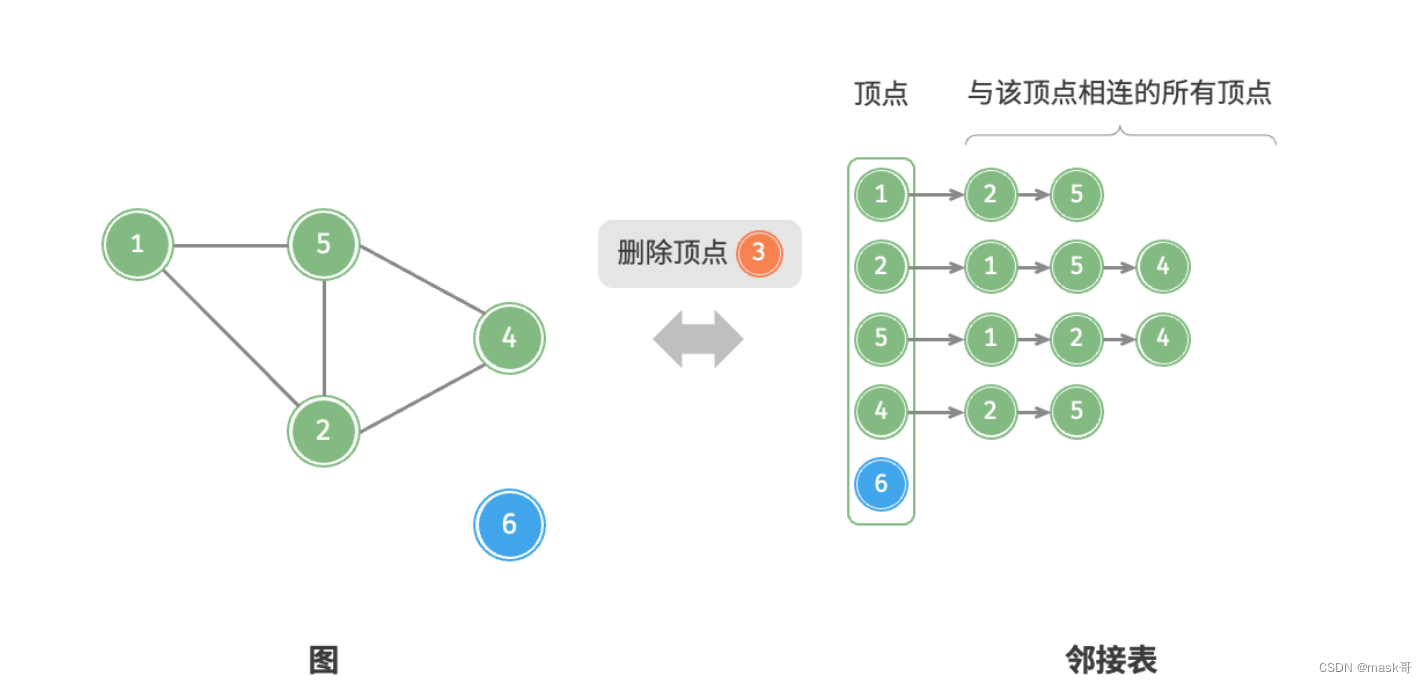
代码实现:
package com.datastructure;
import java.util.ArrayList;
import java.util.List;
/**
* 顶点类
*/
public class Vertex {
public int val;
public Vertex(int val){
this.val=val;
}
/**
* 输入值列表vals,返回顶点列表vets
*/
public static Vertex[] valsToVets(int[] vals){
Vertex[] vets=new Vertex[vals.length];
for(int i=0;i<vals.length;i++){
vets[i]=new Vertex(vals[i]);
}
return vets;
}
/**
* 输入顶点列表vets,返回值列表vals
*/
public static List<Integer> vetsToVals(List<Vertex> vets){
List<Integer> vals=new ArrayList<>();
for(Vertex vet:vets){
vals.add(vet.val);
}
return vals;
}
}
package com.datastructure;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 1.基于邻接矩阵实现无向图:
* 添加或删除边:直接在邻接矩阵中修改指定的边,使用O(1)时间。由于是无向图,需要同时修改两个方向的边。
* 添加顶点:在邻接矩阵的尾部添加一行一列,并全部填0,使用O(n)时间。
* 删除顶点:在邻接矩阵中删除一行一列.当删除首行首列时达到最差情况,需要将(n-1)^2个元素“向左上移动”,使用O(n^2)时间
* 初始化:传入n个顶点,初始化长度为n的顶点列表vertices,使用O(n)时间;初始化nxn大小的邻接矩阵adjMat,使用O(n^2)时间
*
*
*/
public class GraphAdjacencyMatrix {
List<Integer> vertices;//顶点列表,元素代表"顶点值",索引代表"顶点索引"
List<List<Integer>> adjMat;//邻接矩阵,行列索引对应“顶点索引"
public GraphAdjacencyMatrix(int[] vertices,int[][]edges){
this.vertices=new ArrayList<>();
this.adjMat=new ArrayList<>();
//添加顶点
for(int val:vertices){
addVertex(val);
}
//添加边,edges元素代表顶点索引,即对应vertices元素索引
for(int[] e:edges){
addEdge(e[0],e[1]);
}
}
/**
* 获取顶点数量
*/
public int size(){
return vertices.size();
}
/**
* 添加顶点
*/
public void addVertex(int val){
int n=size();
//向顶点列表中添加新顶点的值
vertices.add(val);
//在邻接矩阵中添加一行
List<Integer> newRow=new ArrayList<>(n);
for(int j=0;j<n;j++){
newRow.add(0);
}
adjMat.add(newRow);
//在邻接矩阵中添加一列
for(List<Integer> row:adjMat){
row.add(0);
}
}
/**
* 删除顶点
*/
public void removeVertex(int index){
if(index>=size())
throw new IndexOutOfBoundsException();
//在顶点列表中移除索引index的顶点
vertices.remove(index);
//在邻接矩阵中删除索引index的行
adjMat.remove(index);
//在邻接矩阵中删除索引index的列
for(List<Integer> row:adjMat){
row.remove(index);
}
}
/**
* 添加边
* 参数 i, j 对应 vertices元素索引
* @param i
* @param j
*/
public void addEdge(int i, int j) {
//索引越界与相等处理
if(i<0||j<0||i>=size()||j>=size()||i==j)
throw new IndexOutOfBoundsException();
//在无向图中,邻接矩阵关于主对角线对称,即满足(i,j)==(j,i)
adjMat.get(i).set(j,1);
adjMat.get(j).set(i,1);
}
/**
* 删除边
* 参数 i, j 对应 vertices元素索引
* @param i
* @param j
*/
public void removeEdge(int i, int j) {
//索引越界与相等处理
if(i<0||j<0||i>=size()||j>=size()||i==j)
throw new IndexOutOfBoundsException();
adjMat.get(i).set(j,0);
adjMat.get(j).set(i,0);
}
/**
* 打印邻接矩阵
*/
public void print(){
System.out.println("顶点列表="+vertices);
System.out.println("邻接矩阵="+adjMat);
}
}
/**
* 2.图基于基于邻接表的实现:
* 设无向图的顶点总数为n,边总数为m
* 1.操作实现:
* 添加边:在顶点对应链表的末尾添加边即可,使用O(1)时间复杂度,因为是无向图,需要同时添加两个方向的边。
* 删除边:在顶点对应的链表中查找并删除指定边,使用O(m)时间。因为无向图,需要同时删除两个方向的边
* 添加顶点:在邻接表中添加一个链表,并将新增顶点作为链表头节点,使用O(1)时间复杂度
* 删除顶点:需遍历整个邻接表,删除包含指定顶点的所有边,使用O(n+m)时间
* 初始化:在邻接表中创建n个顶点和2m条边,使用O(n+m)时间复杂度
*/
class GraphAdjacencyList{
//邻接表,key:顶点,value:该顶点的所有邻接顶点
Map<Vertex,List<Vertex>> adjList;
public GraphAdjacencyList(Vertex[][] edges){
this.adjList=new HashMap<>();
//添加所有顶点和边
for(Vertex[] edge:edges){
addVertex(edge[0]);
addVertex(edge[1]);
addEdge(edge[0],edge[1]);
}
}
/**
* 获取顶点数量
*/
public int size(){
return adjList.size();
}
/**
* 添加边
* @param vet1
* @param vet2
*/
public void addEdge(Vertex vet1, Vertex vet2) {
if(!adjList.containsKey(vet1)||!adjList.containsKey(vet2)||vet1==vet2){
throw new IllegalArgumentException();
}
//添加边vet1-vet2
adjList.get(vet1).add(vet2);
adjList.get(vet2).add(vet1);
}
/**
* 删除边
* @param vet1
* @param vet2
*/
public void removeEdge(Vertex vet1, Vertex vet2) {
if(!adjList.containsKey(vet1)||!adjList.containsKey(vet2)||vet1==vet2){
throw new IllegalArgumentException();
}
//删除边vet1-vet2
adjList.get(vet1).remove(vet2);
adjList.get(vet2).remove(vet1);
}
/**
* 添加顶点
* @param vet
*/
public void addVertex(Vertex vet) {
if(adjList.containsKey(vet))
return;
//在邻接表中添加一个新链表
adjList.put(vet,new ArrayList<>());
}
/**
*删除顶点
*/
public void removeVertex(Vertex vet){
if(!adjList.containsKey(vet))
throw new IllegalArgumentException();
//在邻接表中删除顶点vet对应的链表
adjList.remove(vet);
//遍历其他顶点的链表,删除所有包含vet的边
for(List<Vertex> list:adjList.values()){
list.remove(vet);
}
}
/**
* 打印邻接表
*/
public void print(){
System.out.println("邻接表 ");
for(Map.Entry<Vertex,List<Vertex>> pair:adjList.entrySet()){
List<Integer> tmp=new ArrayList<>();
for(Vertex vertex:pair.getValue()){
tmp.add(vertex.val);
}
System.out.println(pair.getKey().val+":"+tmp+",");
}
}
}
- 邻接矩阵与邻接表效率对比
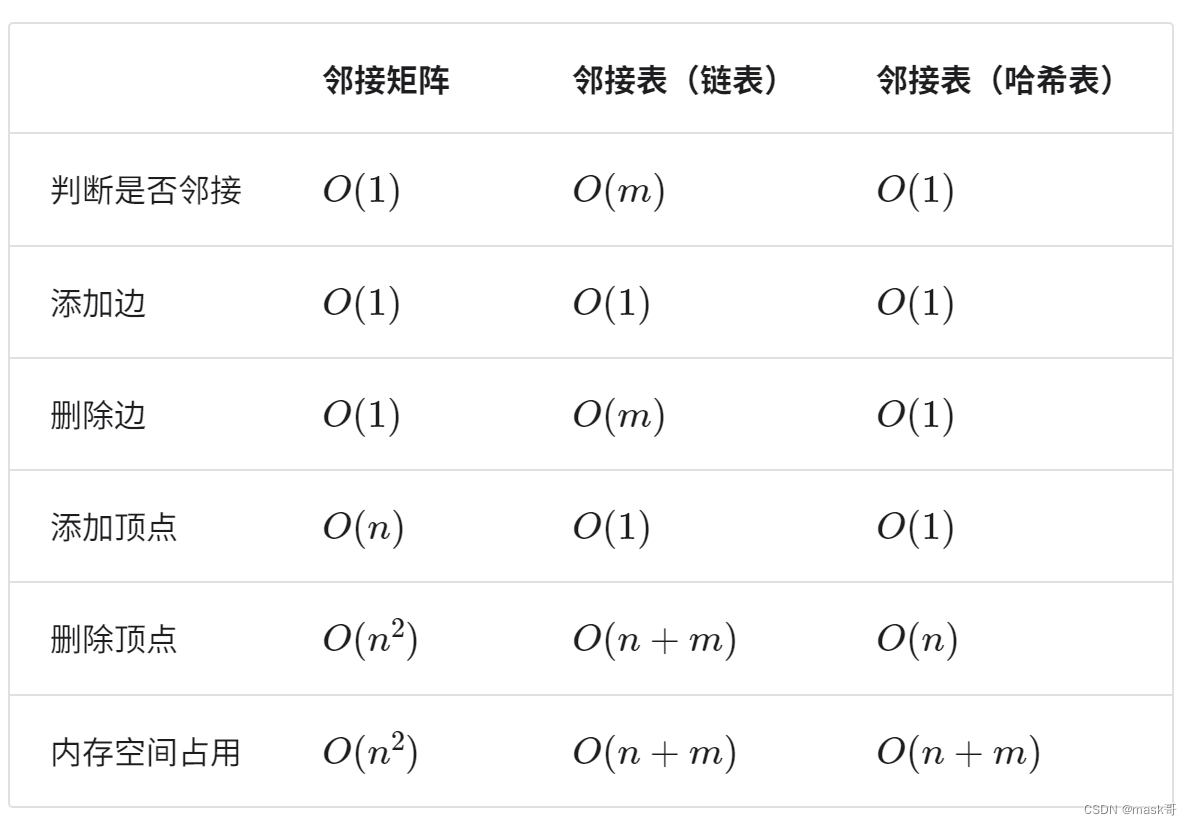
邻接矩阵体现了“以空间换时间”的原则,而邻接表体现了“以时间换空间”的原则。
1.3 图的遍历
图的遍历需使用搜索算法实现。图的遍历方式分为:广度优先遍历和深度优先遍历
- 广度优先遍历(BFS):是一种由近及远的遍历方式,从一个节点出发,始终优先访问距离最近的顶点,并一层层向外扩张.

算法实现:
BFS通常借助队列来实现。队列的先进先出 与BFS的由近及远 思路一样;
1. 将遍历起始顶点startVet加入队列,并开启循环;
1. 在循环的每轮迭代中,弹出队首顶点并记录访问,然后将该顶点的所有邻接顶点加入到队列尾部;
1. 循环step2,直到所有顶点被访问完毕结束.
为防止重复遍历顶点,借助一个哈希表 visited 来记录哪些节点已被访问
代码实现:
/**
* 广度优先遍历:
* 使用邻接表来表示图,以便获取指定顶点的所有邻接顶点
*/
public List<Vertex> graphBFS(GraphAdjacencyList graph,Vertex startVet){
//顶点遍历序列
List<Vertex> res=new ArrayList<>();
//哈希表,用于记录已被访问过的顶点
Set<Vertex> visited=new HashSet<>();
visited.add(startVet);
//队列用于实现BFS
Queue<Vertex> queue=new LinkedList<>();
queue.offer(startVet);
//以顶点vet为起点,循环直到访问完所有顶点
while (!queue.isEmpty()){
Vertex vet=queue.poll();//队首顶点出队
res.add(vet);
//遍历该顶点的所有邻接顶点
for(Vertex adjVet:graph.adjList.get(vet)){
if(visited.contains(adjVet))
continue;//跳过已经被访问的顶点
queue.offer(adjVet);//只入队未访问的顶点
visited.add(adjVet);//标记该顶点已经被访问
}
}
//返回顶点遍历序列
return res;
}
-
深度优先遍历(DFS):是一种优先走到底,无路可走再回头的遍历方式
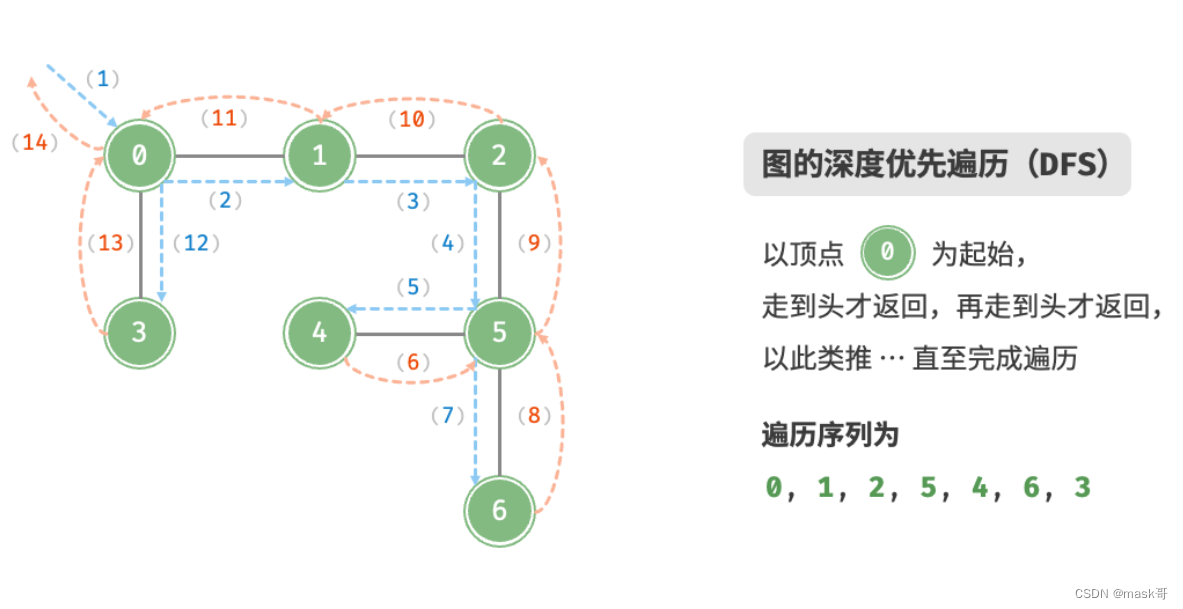
算法实现:这种走到尽头再返回的 算法通常基于递归实现。需借助一个哈希表
visited来记录已被访问的顶点,以避免重复访问顶点
代码实现:
/**
* 深度优先遍历辅助函数
*/
public void dfs(GraphAdjacencyList graph,Set<Vertex> visited,List<Vertex> res,Vertex vet){
res.add(vet);//记录访问顶点
visited.add(vet);//标记该顶点已被访问
//遍历该顶点的所有邻接顶点
for(Vertex adjVet:graph.adjList.get(vet)){
if(visited.contains(adjVet))
continue;//跳过已经被访问的顶点
//递归范围邻接顶点
dfs(graph,visited,res,adjVet);
}
}
/**
* 深度优先遍历
* 使用邻接表来表示图,以便获取指定顶点的所有邻接顶点
*/
public List<Vertex> graphDFS(GraphAdjacencyList graph,Vertex startVet){
//顶点遍历序列
List<Vertex> res=new ArrayList<>();
//哈希表,用于记录已经被访问过的顶点
Set<Vertex> visited=new HashSet<>();
dfs(graph,visited,res,startVet);
return res;
}
- 总结:
- 邻接矩阵利用矩阵来表示图,每一行(列)代表一个顶点,矩阵元素代表边,用 1 或 0 表示两个顶点之间有边或无边
- 从算法思想的角度分析,邻接矩阵体现了“以空间换时间”,邻接表体现了“以时间换空间
- 图的广度优先遍历是一种由近及远、层层扩张的搜索方式,通常借助队列实现。
- 图的深度优先遍历是一种优先走到底、无路可走时再回溯的搜索方式,常基于递归来实现。















 1894
1894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









