









一 Map/Reduce简介
MapReduce 是目前最流行和被普遍研究的海量数据处理方法。它是Google公司的核心模型,用于大规模数据集(大于1TB)的并行计算。“映射(Map)”与“化简(Reduce)”的概念是它们的主要思想,都是从函数式编程语言借来的。MapReduce将负责的运行于大规模集群上的并行计算过程高度地抽象为两个函数(Map和Reduce),利用一个输入<key,value>集合来产生一个输出地<key,value>对集合,极大地方便了编程地人员,在不了解分布式并行编程地情况下,它们也能将自己地程序运行在分布式系统上。
MapReduce在执行时先指定一个Map(映射)函数,把输入<key,value>对映射成一组新的<key,value>对,经过一定处理后交给 Reduce,Reduce对相同key下的所有value处理后再输出<key,value>对作为最终的结果。
MapReduce计算模型非常适合在大量计算机组成的大规模集群上并行运行。在采用Map/Reduce模式的分布式系统上,每一个Map任务和每一个Reduce任务均可以同时运行于一个单独的计算节点上,可想而知其处理效率是很高的。
二 Map/Reduce过程
MongoDB中的Map/Reduce对于批量处理数据进行聚合操作是非常有用的。在思想上它跟Hadoop一样,从一个单一集合中输入数据,然后将结果输出到一个集合中。通常在使用类似SQL中Group By操作时,Map/Reduce会是一个好的工具。
看下面一个实例:
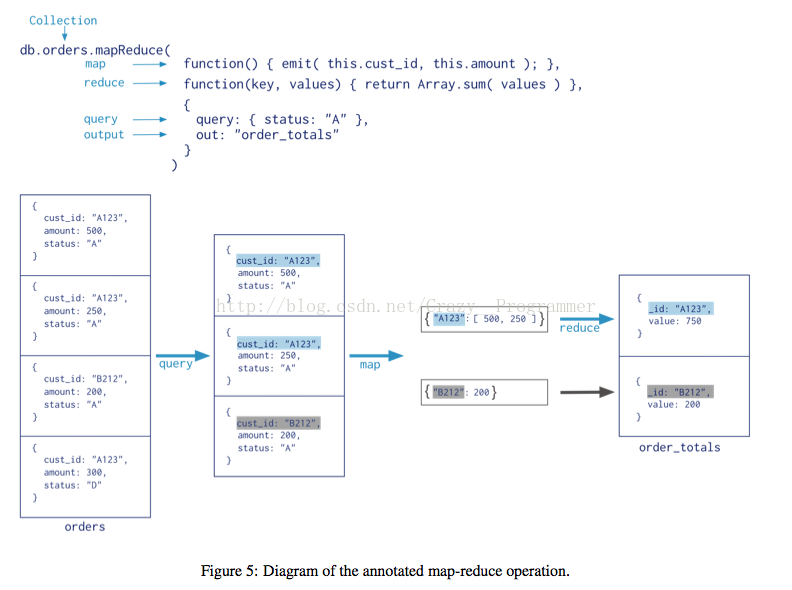
a.在orders集合上进行MapReduce操作,首先使用query进行“过滤”操作,选择出 status为’A’的所有文档。
b.在选择后的每个文档上执行map操作,在map操作的时候将当前文档的this.cust_id,this.amount分别作为键值发射出去,经过map操作后,相同键的文档的值被放到一起组成一个数组。
c.如果一个键有多个值的话,进行reduce的操作,在进行reduce 操作的时候将所有的值进行累加
如果一个健只有一个值的话就直接输出到结果集合
d.Reduce完后将结果输出到预先定义好的结果集合中,即order_totals集合。
三 Map/Reduce 指令
Map/Rudece是通过数据库指令调用的,指令原型如下:
db.runCommand(
{
mapReduce: <collection]]
>
,
map: <function]]
>
,
reduce: <function]]
>
,
out: <output]]
>
,
query: <document]]
>
,
sort: <document]]
>
,
limit: <number]]
>
,
finalize: <function]]
>
,
scope: <document]]
>
,
jsMode: <boolean]]
>
,
verbose: <boolean]]
>
} )
参数说明:
mapReduce:要执行Map/Reduce集合的名字
map:map 函数 (下面会详细介绍)
reduce:reduce函数(下面会详细介绍)
out:存放结果的集合 (下面会详细介绍)
query:设置查询条件 <可选>
sort: 按某个键来排序 <可选>
limit:指明从集合检索文档个数的最大值 <可选>
finalize:对reduce结果做进一步处理 <可选>
scope:指明通过map/reduce/finalize可以访问到的变量 <可选>
jsMode:指明Map/Reduce执行过程中文档保持JSON状态 <可选>
verbose:提供关于任务执行的统计数据 <可选>
例如:
var mapFunction = function() { ... };
var reduceFunction = function(key, values) { ... };
db.runCommand(
{
mapReduce: 'orders',
map: mapFunction,
reduce: reduceFunction,
out: { merge: 'map_reduce_results', db: 'test' },
query: { ord_date: { $gt: new Date('01/01/2012') } }
} )
四 参数详细说明
对Map/Reduce指令中的几个重要参数做一下详细的说明,以便我们能够写出正确的Map/Reduce程序。主要介绍一下Map、Reduce和Out三个参数使用,它们也是必选的参数。
1.Map函数
Map函数通过变量this来检验当前考察的对象。一个Map函数会通过任意多次函数调用emit(key,value)来将数据送入reducer中。大多数情况下,对于每个文档都只会发送一次,但是在有些情况下需要发送多次,例如下面这个Map程序,整个文档被调用的次数取决于items数组中元素的个数.
function() {
this.items.forEach(function(item){ emit(item.sku, 1); }); }
有些情况下也会发送0次,例如:
function() {
if (this.status == 'A')
emit(this.cust_id, 1);
}
每一次发送的数据都被限制到最大文档大小的50%(比如MongoDB1.6.x中是4MB, MngoDB1.8.x中是8MB)。
2.Reduce函数
当运行Map/Reduce时,Reduce函数将收到一个发送值构成的数组并且要把它们简化到单个值。因为针对一个键值的Reduce函数可能会被调用到好多次,Reduce函数返回的对象结构要与Map函数发送的值的结构必须时完全相同。我们可以用一个简单的例子来说明这一情况。
假设对一个代表用户评价的文档构成的集合进行迭代,典型的文档内容如下:
{
name:”jones”,
likes:20,
text:”hello world!”
}
我们想利用Map/Reduce来统计每个用户的评论数,并且计算全部用户评价中“like”的总数。为了达到这个目的,首先写一个如下的Map函数:
func () {
emit( this.username, {count:1,likes:this.likes});
}
这个函数实际上指明了要以username来分组,并且针对count和likes字段进行聚合运算。当Map/Reduce实际运行的时候,一个由用户构成的数组将发送给Reduce函数,这个就是为什么Reduce函数总是用来处理数组。下面就是一个Reduce函数的例子。
func(key,values) {
var result = {count:0, likes:0}
values.forEach(function(value)) {
result.count += value.count;
result.likes += value.likes;
});
return result;
}
注意:
a.结果文档和Map函数所传送的数据拥有相同的结构。
即:reduce(key, [ C, reduce(key, [ A, B ]) ] ) == reduce( key, [ C, A, B ] )
这是非常重要的,因为当Reduce函数作用于某个key值时,它并不保证会对这个key值(这里是username)的每一个value进行操作。事实上,Reduce函数不得不运行多次。比如,当处理评论集合时,Map函数可能遇到来自”jones”的10条评论,它会把这些评论传送给Reduce函数,得到如下聚集结果:
{count:10,likes:247}
然后,Map函数又遇到一个来自”jones”的评论,此时,这值必须被重新考虑来修改聚合结果。如果遇到新的评论为:{count:1,likes:5}
那么reduce函数将被这样调用:
reduce{“jones”,[{count:10,likes:247},{count:1,likes:5}]}
最后的结果将会是上面两个值的结合:{count:11,likes:252}
只有你理解对一个key值Reduce函数可能被多次调用,就容易理解为什么这个函数必须饭后一个和Map函数发送的值具有相同的结构了。
b.数组中元素的顺序不能影响结果的输出
reduce( key, [ A, B ] ) == reduce( key, [ B, A ] )
3.Out函数
在MongoDB1.8之前的版本,如果你没有指定out的值,那么结果将会被放到一个临时集合中,集合的名字在输出指令中指定,否则,你可以指定一个集合的名字作为out的选项,而结果将会被存储到你指定的集合中。
对于MongoDB1.8以及以后的版本,输出选项改变了。Map/Reduce 不再产生临时集合,你必须为out指定一个值,设置out指令如下:
默认输出第一个集合中,如果该集合不存在的话,会自动的创建
out: <collectionName]]
>
除此之外,也可以加一些选项,这只适用于集合已经存在的情况
out: { <action>: <collectionName]]
>
[, db: <dbName]]
>
]
[, sharded: <boolean]]
>
]
[, nonAtomic: <boolean]]
>
] }
a.参数Action说明:
Action可以为 replace(默认)、merge、reduce
{replace:”collectionName"}:输出结果将被插入到一个集合中,并且会自动替换掉现有的同名集合。该选项为默认的。
{merge:”collectionName"}:这个选项将会把新的数据连接到旧的输出结合中。换句话说,如果在结果集和旧集合中存在相同键值,那么新的键将会被覆盖掉。
{reduce:”collectionName"}:如果具有某个键值的文档同时存在于结果集和旧集合中,那么一个Reduce操作(利用特定的reduce函数)将作用于这个两个值,并且结果将会被写到输出集合中。如果指定了finalize函数,那么当Reduce结束后它将被执行。
b. 参数db: 指明接收输出结果的数据库名称
out:{replace:”collectionName",db:”otherDB"}
c. 参数shard: {shared:true}:适用于MongoDB1.9及以上的版本。如果设置为true,并且将输出模式设置为输出得到集合中,那么输出的结合的每个文档就将用_id字符进行切分。
d. 参数 inlne: {inline:1}借助于该选项,将不会创建集合,并且整个Map/Reduce的操作将会在内存中进行。同样,Map/Reduce的结果将会被返回到结果对象中。注意,这个选项只有在结果集的单个文档大小在16MB限制范围内时才有效。
db.users.mapReduce(map,reduce,{out:{inline:1}});
4 Finalize函数
finalize函数可能会在Reduce函数结束之后运行,这个函数是可选的,对于很多Map/Reduce任务来说不是必需的。finalize函数接收一个key和一个value,返回一个最终的value.
function finalize(key,value) -> final_value
针对一个对象你的Reduce函数可能被调用了多次。当最后只需针对一个对象进行一次操作时可以使用finalize函数,比如计算平均值。
5.jsMode标识
对于MongoDB2.0及以上的版本,通常Map/Reduce的执行遵循下面两个步骤:
a.从BSON转化为JSON,执行Map过程,将JSON转化为BOSN
b.从BSON转化为JSON,执行Reduce过程,将JSON转化为BSON
因此,需要多次转化格式,但是可以利用临时集合在Map阶段处理很大的数据集。为了节省时间,可以利用{jsMode:ture}使Map/Reduce的执行保持在JSON状态。遵循如下两个步骤:
a.从BSON转化为JSON,执行Map过程
b.执行Reduce过程,从 JSON转化为BSON
这样,执行时间可以大大减小,但需要注意,jsMode 受到JSON堆大小和独立主键最大500KB的限制。因此,对于较大的任务jsMode并不适用,在这种情况下会转变为通常的模式。
四 总结
Map-Reduce操作将一个单一集合内文档作为输入,在进行map函数所定义的操作的时候,可以进行任意的排序或者limit文档个数的操作。mapReduce操作 返回的结果可以是一条文档,也可以将其结果写到一个集合里面。
也可以以inline方式返回(结果文档必须要小于BSON文档的大小限制,当前是16M) 如果写到一个集合中,我们就可以在整个集合上进行进一步的聚合操作。
下一节,将详细介绍MapReduce的使用。














 351
351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









