






S1 服务器上安装kaggle cli工具
pip install --user kaggle
S2 服务器上创建kaggle目录
mkdir ~/.kaggle
S3 进入kaggle账户创建token
生成token
点击右上角头像,选择setting
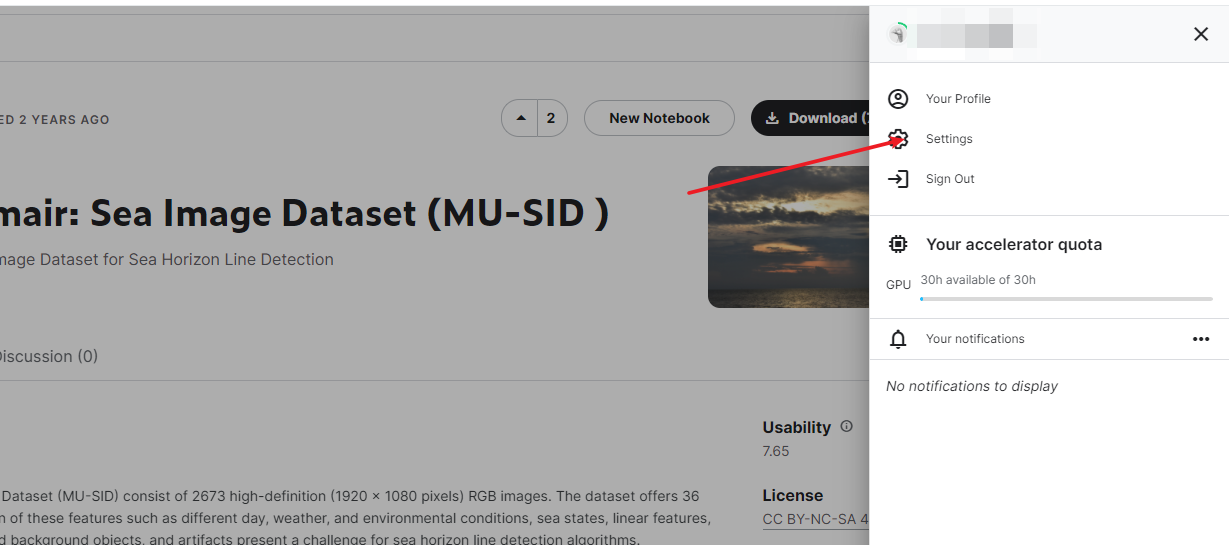
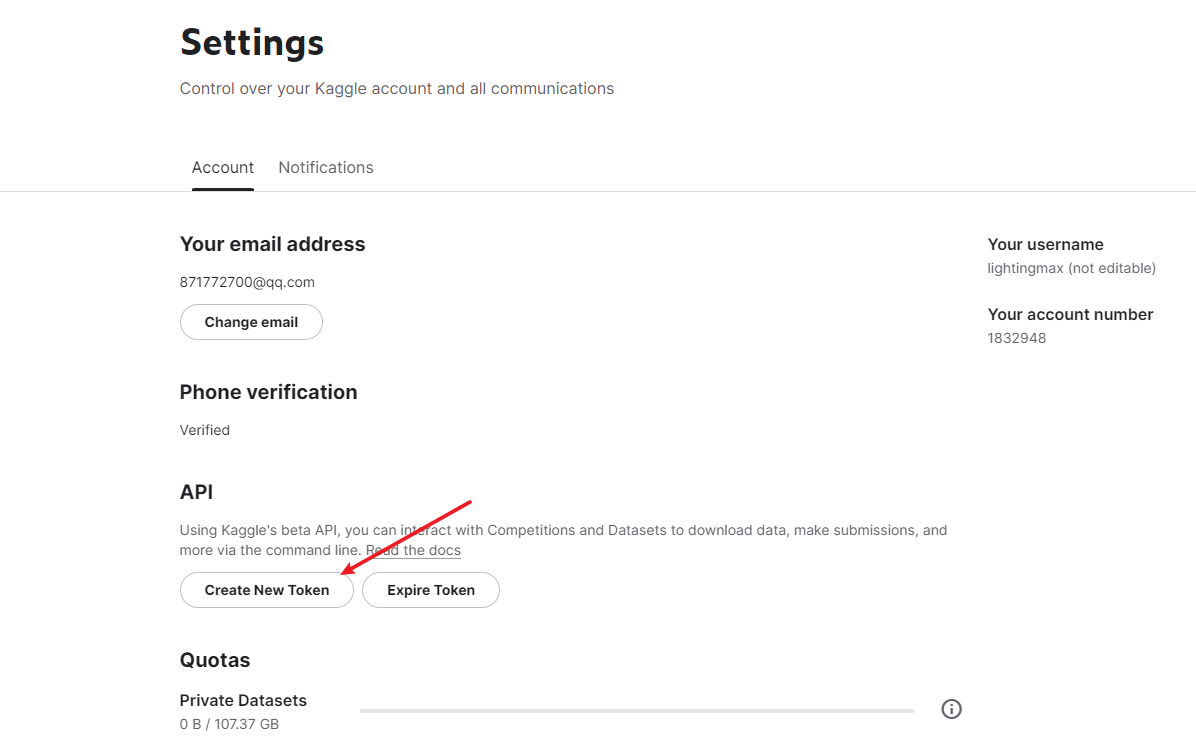
点击create new token
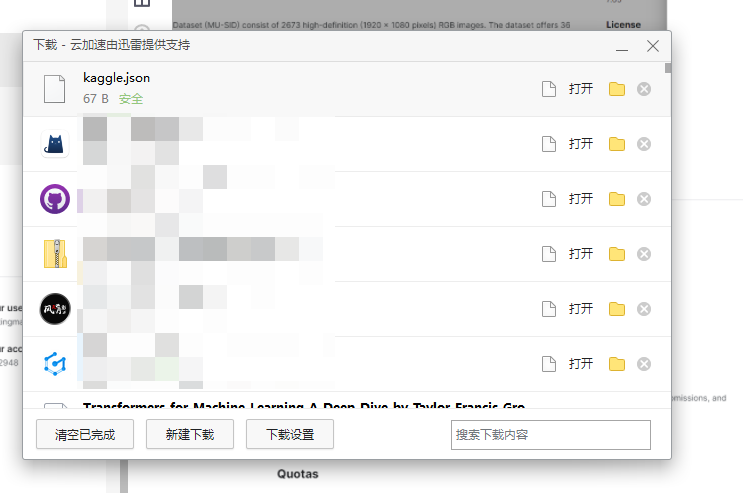
进入你的浏览器下载页,可以看到有了一个kaggle.json
将kaggle.json文件复制到~/.kaggle目录下
使用scp指令,rz指令,ftp等一万种方式将将kaggle.json文件复制到~/.kaggle目录下,正常执行ls ~/.kaggle你应该可以看到下面这种结果:

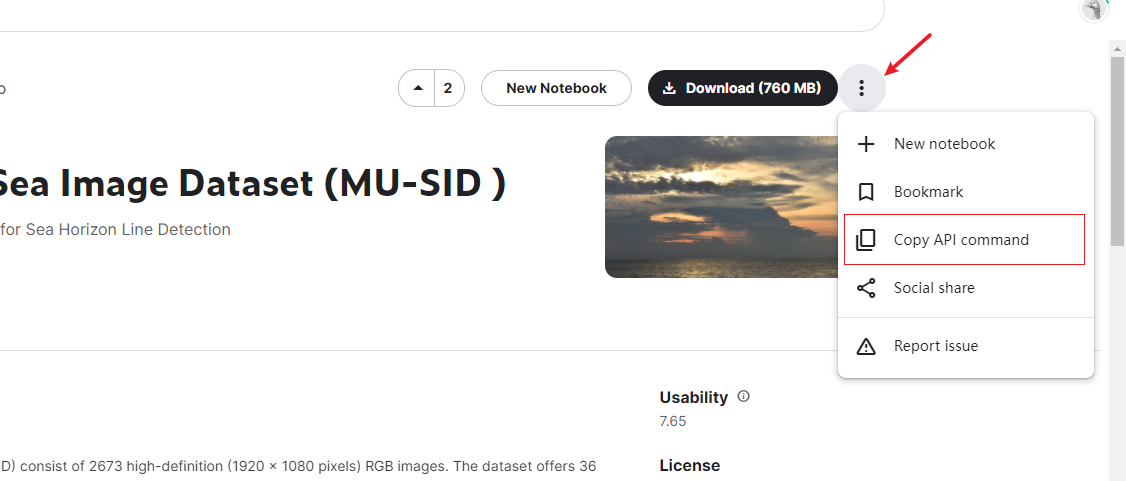
进入数据集网页复制下载指令
点击 Copy API command ,即复制了下载指令
S4 粘贴指令进行下载

可以看到,速度很快~
后记:可能的问题
显示kaggle没有这个指令
1.查看自己的kaggle执行路径
echo ~/.local/bin

将这个地址写入~/.bash_file
2.编辑~/.bash_profile
vim ~/.bash_profile
3.用下面的格式写入:
export PATH="《刚才你得到的地址》:$PATH"
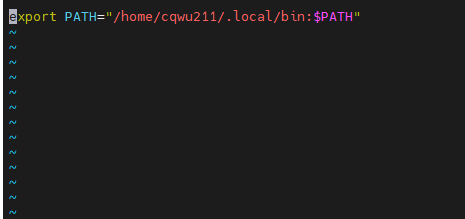
保存退出
4.更新~/.bash_profile
执行
source ~/.bash_profile
5.这个时候执行kaggle,可以看到已经有指令了


















 3325
3325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









