






本文 的 原文 地址
尼恩:LLM大模型学习圣经PDF的起源
在40岁老架构师 尼恩的读者交流群(50+)中,经常性的指导小伙伴们改造简历。
经过尼恩的改造之后,很多小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试机会,拿到了大厂机会。
然而,其中一个成功案例,是一个9年经验 网易的小伙伴,当时拿到了一个年薪近80W的大模型架构offer,逆涨50%,那是在去年2023年的 5月。
不到1年,小伙伴也在团队站稳了脚跟,成为了名副其实的大模型 应用 架构师。接下来,尼恩架构团队,通过 梳理一个《LLM大模型学习圣经》 帮助更多的人做LLM架构,拿到年薪100W, 这个内容体系包括下面的内容:
-
《LLM大模型学习圣经:从0到1精通RAG架构,基于LLM+RAG构建生产级企业知识库》
-
《LLM大模型学习圣经:从0到1吃透大模型的顶级架构》
-
《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的架构 与实操》
-
《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的 中台 架构 与实操》
-
《Spring AI 学习圣经 和配套视频 》
-
《AI部署架构:A100、H100、A800、H800、H20的差异以及如何选型?开发、测试、生产环境如何进行部署架构?》
以上学习圣经 的 配套视频, 2025年 5月份之前发布。
一、vllm 基础知识:
(一)、核心功能与技术特性
vLLM 是专为大型语言模型(LLM)推理和部署设计的高性能开源框架,由社区维护并广泛应用于生成式 AI 的优化场景。
vllm 核心功能与技术特性
1 高效推理与内存管理
vllm 采用 PagedAttention 技术优化注意力键值的内存分配,减少资源浪费,支持长上下文窗口处理。
结合连续批处理(Continuous Batching)和 CUDA/HIP 图加速,显著提升吞吐量 。
2 分布式与量化支持
- 支持 张量并行 和流水线并行,实现多 GPU/TPU 分布式推理 。
- 提供多种量化方案(如 GPTQ、INT4、FP8),降低计算资源需求 。
3 兼容性与扩展性
无缝集成 Hugging Face 模型生态,支持流式输出和 OpenAI API 兼容的服务器部署,适配 NVIDIA、AMD、Intel 等多种硬件 。
vllm 的性能优势
-
吞吐量对比:
在相同延迟下,vLLM 的吞吐量较 HuggingFace Transformers 高 8.5–15 倍,较文本生成推理框架(TGI)高 3.3–3.5 倍 。
-
资源利用率:
通过动态内存管理和分页技术,提升 GPU 利用率,降低中小型服务器或边缘设备的部署门槛 。
(二)、vllm 安装和启动
github
https://github.com/vllm-project/vllm
接下来,看看 vLLM在线文档。
vLLM在线文档
https://vllm.hyper.ai/docs/
接下来,看看vLLM安装。
vLLM安装
vLLM 是一个 Python 库,包含预编译的 C++ 和 CUDA (12.1) 二进制文件。
环境
- 操作系统:Linux
- Python:3.8 - 3.12
- GPU:计算能力 7.0 或更高(例如 V100、T4、RTX20xx、A100、L4、H100 等)
pip安装
//(推荐)创建一个新的 conda 环境。
conda create -n myenv python=3.10 -y
conda activate myenv
// 安装带有 CUDA 12.1 的 vLLM。
pip install vllm
建议使用全新的 conda 环境安装 vLLM。
如果您有不同的 CUDA 版本或者想要使用现有的 PyTorch 安装,则需要从源代码构建 vLLM。
vLLM启动
使用python 启动
python3 -m vllm.entrypoints.openai.api_server --model /root/autodl-tmp/models/Qwen-7b-instruct --host 0.0.0.0 --port 8000 --dtype auto --max-num-seqs 32 --max-model-len 4096 --tensor-parallel-size 1 --trust-remote-code
参数说明
–model #指定要加载的模型路径
–dtyp #指定模型权重的数据类型,auto 表示框架会根据硬件自动选择合适的数据类型(例如 FP16 或 BF16)
–max-num-seqs #设置最大并发序列数,服务器同时处理的最大请求数
–max-model-len #设置模型支持的最大上下文长度(token 数量)
–tensor-parallel-size #1表示不使用张量并行,模型将在单个 GPU 上运行
–trust-remote-code #允许加载远程代码或自定义模型代码
使用vllm命令启动
vllm serve /root/autodl-tmp/models/Qwen-7b-instruct --max-model-len 4096 --tensor-parallel-size 1
启动命令参考在线文档
https://vllm.hyper.ai/docs/getting-started/quickstart
(三)、使用openAI调用示例
第一个示例:vllm离线推理
import os
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
// 模型路径
model_dir = '/root/autodl-tmp/models/Qwen-7b-instruct'
// 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(
model_dir,
local_files_only=True,
)
// Prompt
messages = [
{'role':'system','content':'You are a medical assistant'},
{'role':'user','content':'最近经常熬夜,与之前生物钟颠倒,而且最近还肠胃发炎了不过已经好多了最近色斑越长越多'}
]
// 将messages转换为text
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
// 初始化LLM
llm = LLM(
model = model_dir,
tensor_parallel_size=1,
gpu_memory_utilization=0.9,
max_model_len=4096
)
// 设置采样参数
sampling_params = SamplingParams(temperature=1,top_p=0.8,max_tokens=512)
// 生成输出
outputs = llm.generate([text],sampling_params)
// 打印输出
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, LLM output:{generated_text!r}")
接下来,看看第二个示例。
第二个示例:OpenAI单一对话
// 注意:请先安装 openai
// pip install openai
from openai import OpenAI
// 设置 OpenAI API 密钥和 API 基础地址
openai_api_key = "EMPTY" # 请替换为您的 API 密钥
openai_api_base = "http://localhost:8000/v1" # 本地服务地址
client = OpenAI(base_url=openai_api_base,api_key=openai_api_key)
// Completion API 调用
completion = client.chat.completions.create(
model="/root/autodl-tmp/models/Qwen-7b-instruct",
messages=[{"role":"user","content":"最近经常熬夜,与之前生物钟颠倒,而且最近还肠胃发炎了不过已经好多了最近色斑越长越多"}])
print(completion.choices[0].message.content)
接下来,看看第3个示例。
第三个示例:OpenAI多轮对话
from openai import OpenAI
import os
from dotenv import load_dotenv
import logging
// 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class ChatSession:
def __init__(self):
# 加载环境变量
load_dotenv()
self.api_key = os.getenv("OPENAI_API_KEY", "EMPTY")
self.api_base = os.getenv("OPENAI_API_BASE", "http://localhost:8000/v1")
self.model = os.getenv("MODEL_PATH", "/root/autodl-tmp/models/Qwen-7b-instruct")
self.client = OpenAI(base_url=self.api_base, api_key=self.api_key)
self.chat_history = []
def add_message(self, role, content):
"""添加消息到历史记录"""
self.chat_history.append({"role": role, "content": content})
def get_assistant_response(self, temperature=0.7):
"""获取助手响应"""
try:
response = self.client.chat.completions.create(
model=self.model,
messages=self.chat_history,
temperature=temperature
)
return response.choices[0].message.content
except Exception as e:
logger.error(f"获取响应时发生错误: {str(e)}")
return f"抱歉,发生了错误: {str(e)}"
def run(self):
"""运行聊天会话"""
logger.info("开始聊天会话")
print("欢迎使用聊天助手!输入 'quit' 退出。")
while True:
try:
user_input = input("n用户: ").strip()
if user_input.lower() == "quit":
print("再见!")
break
if not user_input:
print("请输入有效内容")
continue
self.add_message("user", user_input)
assistant_response = self.get_assistant_response()
print(f"助手: {assistant_response}")
self.add_message("assistant", assistant_response)
except KeyboardInterrupt:
print("n程序被用户中断")
break
except Exception as e:
logger.error(f"运行时发生错误: {str(e)}")
print("发生了错误,请重试")
def main():
try:
chat_session = ChatSession()
chat_session.run()
except Exception as e:
logger.error(f"程序启动失败: {str(e)}")
if __name__ == "__main__":
main()
接下来,看看k8s+ vllm 安装 Deepseek大模型 和 容器调度。
二、k8s+ vllm 安装 Deepseek大模型 和 容器调度
(一)、vLLM 在 Kubernetes 中的安装部署
1 Helm Chart 部署
添加 vLLM Production Stack 的 Helm 仓库并安装:
helm repo add vllm-prod https://vllm-prod.github.io/charts
helm install vllm vllm-prod/vllm --namespace vllm --create-namespace
支持通过values.yaml 自定义模型路径、GPU 驱动版本等参数 。
2 Kubernetes 基础环境配置
确保集群节点已安装 NVIDIA GPU 驱动及 nvidia-docker 运行时,并配置 device-plugin 插件以支持 GPU 资源调度。
私有镜像仓库配置(如 Harbor),需同步证书至 /etc/docker/certs.d/ 目录并完成登录验证。
3 分布式 KV 缓存配置
启用 vLLM 的分布式 KV 缓存共享功能,通过 LMCache 技术减少内存冗余,需在部署时 指定共享存储后端(如 Redis 或 Alluxio)。
(二)、Kubernetes GPU 环境配置指南
1:NVIDIA GPU 驱动安装
环境检查与驱动安装
执行以下命令确认系统内核版本和 GPU 型号:
uname -r # 查看内核版本
lspci | grep -i nvidia # 识别 GPU 型号
禁用系统默认的 Nouveau 驱动,避免与 NVIDIA 官方驱动冲突:
echo "blacklist nouveau" | sudo tee /etc/modprobe.d/blacklist-nouveau.conf
sudo update-initramfs -u # 更新 initramfs
安装 NVIDIA 官方驱动(建议选择与 H20 GPU 兼容的版本):
sudo apt-get install -y nvidia-driver-535 # 示例版本号需按实际调整
sudo reboot # 重启生效
验证驱动安装:
nvidia-smi
输出 GPU 状态信息。
2、nvidia-docker 运行时配置
安装 NVIDIA Container Toolkit.
NVIDIA Container Toolkit 是 NVIDIA 官方提供的容器运行时扩展工具集,
核心作用是将宿主机的 GPU 驱动能力注入容器,使得容器内应用可直接调用 GPU 计算资源(如 CUDA 库、cuDNN 等),实现容器化环境中 GPU 资源的透明化调用。
添加 NVIDIA 容器工具包仓库并安装:
distribution=$(. /etc/os-release; echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
3、配置 Docker 默认运行时:
sudo tee /etc/docker/daemon.json <<EOF
{
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
},
"default-runtime": "nvidia"
}
EOF
sudo systemctl restart docker # 重启 Docker
验证运行时:
docker run --rm nvidia/cuda:12.2.0-base-ubuntu22.04 nvidia-smi
应显示 GPU 信息。
(三)、NVIDIA Device Plugin 部署
1 NVIDIA Device Plugin 背景知识
NVIDIA Device Plugin 是 Kubernetes 生态中专用于管理 GPU 资源的官方插件,其核心功能包括:
- GPU 资源发现与注册:自动检测节点上的 GPU 设备数量及状态,通过 Kubernetes API 将 GPU 注册为可调度资源(如
nvidia.com/gpu) 。 - 资源动态分配:在 Pod 调度过程中,根据声明需求(如
resources.limits.nvidia.com/gpu: 1)为容器分配指定数量的 GPU 卡 。 - 环境变量注入:在容器启动时自动注入
NVIDIA_VISIBLE_DEVICES等环境变量,指导容器运行时(如 Docker/containerd)挂载 GPU 设备 。
2 安装 NVIDIA Device Plugin
部署官方设备插件以支持 Kubernetes 识别 GPU 资源:
kubectl apply -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.14.1/nvidia-device-plugin.yml
插件将以 DaemonSet 形式运行在所有 GPU 节点。
3: NVIDIA Device Plugin 工作原理
- DaemonSet 部署:以 DaemonSet 形式运行在集群所有 GPU 节点上,持续监控 GPU 资源状态 。
- 与 Kubelet 通信:通过 gRPC 协议与节点上的 Kubelet 交互,上报 GPU 资源信息并响应资源分配请求 。
- 设备健康检查:周期性检测 GPU 驱动状态和硬件健康度,异常时触发资源回收或节点标记 。
4 验证 GPU 资源可见性
检查节点资源分配状态:
kubectl describe node <node-name> | grep nvidia.com/gpu
输出应显示nvidia.com/gpu: <数量>,表示 GPU 资源已被集群识别。
(四)、K8S 常见问题与验证
1 故障排查
- GPU 驱动未生效:检查
/var/log/nvidia-installer.log日志,确认无 Nouveau 驱动残留 。 - Device Plugin 未运行:检查 Pod 日志
kubectl logs -n kube-system <nvidia-device-plugin-pod>,确保插件无报错 。 - 调度失败:确认 Pod 中声明了
resources.limits.nvidia.com/gpu: <数量>,并与节点资源匹配 。
2 功能验证
运行 GPU 测试 Pod:
apiVersion: v1
kind: Pod
metadata:
name: gpu-test
spec:
containers:
- name: cuda-container
image: nvidia/cuda:12.2.0-base-ubuntu22.04
command: ["sleep", "infinity"]
resources:
limits:
nvidia.com/gpu: 1
进入容器执行nvidia-smi,确认 GPU 可用。
2 关键配置总结
| 组件 | 配置要点 | 验证命令 |
|---|---|---|
| NVIDIA 驱动 | 禁用 Nouveau,安装兼容版本驱动 | nvidia-smi 16 |
| nvidia-docker | 配置默认运行时为 nvidia,重启 Docker | docker run nvidia/cuda... |
| Device Plugin | 部署 DaemonSet 并验证节点资源可见性 | kubectl describe node |
以上配置整合了 NVIDIA 官方指南与生产环境实践,确保 Kubernetes 集群可稳定调度 GPU 资源。
(五)、K8S 容器调度优化策略
1、资源分配与限制
- 资源声明:Pod 需在
resources.limits中显式声明nvidia.com/gpu需求,调度器据此匹配 GPU 节点。 - 调度约束:支持通过
nodeAffinity或nodeSelector绑定特定 GPU 型号节点(如 H20/A100)。 - 扩展性:兼容 CDI(Container Device Interface)和 NFD(Node Feature Discovery),支持异构硬件(如 FPGA、InfiniBand)的统一管理。
在 Pod 定义中明确声明 GPU 和内存资源请求(如 nvidia.com/gpu: 1 及 memory: 16Gi),避免资源争用导致调度失败。
使用 requests 和 limits 控制资源超卖比例,平衡性能与资源利用率。
2、自动扩缩容配置
基于 HPA(Horizontal Pod Autoscaler)实现动态扩缩容,监控指标包括请求延迟(如 P99 < 200ms)和 GPU 利用率(阈值建议 70%)。
结合 Cluster Autoscaler 自动调整节点数量,优化跨节点负载均衡 。
3、调度策略定制
节点亲和性:通过 nodeAffinity 将 vLLM Pod 调度至含特定 GPU 型号(如 A100)的节点 。
污点容忍:为 GPU 节点添加污点(如 gpu: true),并在 Pod 配置中声明容忍以独占资源 。
拓扑感知调度:利用 topologySpreadConstraints 分散 Pod 分布,提升跨可用区容灾能力 。
4、模型与存储准备
模型下载与量化
// 下载 DeepSeek-14B 的 INT4 量化版本(显存需求降至 12GB/卡)
git lfs install
git clone https://huggingface.co/deepseek-ai/DeepSeek-14B-4bit /mnt/nvme/deepseek-14b-4bit
存储卷配置
//PVC 配置文件 (deepseek-pvc.yaml)
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: deepseek-pvc
spec:
storageClassName: ssd
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 200Gi # 推荐 NVMe SSD 存储卷:ml-citation{ref="4,5" data="citationList"}
5、deepseek 容器镜像构建
// Dockerfile(基于 vLLM 官方镜像)
FROM vllm/vllm-openai:latest
COPY --from=deepseek-ai/DeepSeek-14B-4bit /model /app/model
RUN pip install --no-cache-dir deepseek-ai==0.4.2 # 安装模型依赖库
构建并推送镜像:
docker build -t registry.example.com/deepseek-14b:v1 .
docker push registry.example.com/deepseek-14b:v1
6、Kubernetes 资源配置
Deployment 配置
// deepseek-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deepseek-14b
spec:
replicas: 1
selector:
matchLabels:
app: deepseek
template:
metadata:
labels:
app: deepseek
spec:
containers:
- name: vllm-server
image: registry.example.com/deepseek-14b:v1
resources:
limits:
nvidia.com/gpu: "4" # 独占 4 卡
ports:
- containerPort: 8000
volumeMounts:
- name: model-storage
mountPath: /app/model
volumes:
- name: model-storage
persistentVolumeClaim:
claimName: deepseek-pvc
服务暴露
// deepseek-service.yaml
apiVersion: v1
kind: Service
metadata:
name: deepseek-svc
spec:
type: NodePort
ports:
- port: 8000
targetPort: 8000
nodePort: 30080
selector:
app: deepseek
7、vLLM 性能调优参数
vLLM 启动参数优化
// 容器启动命令(追加到 Deployment 的 command 字段)
command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
args:
- "--model=/app/model"
- "--tensor-parallel-size=4" # 4 卡张量并行
- "--gpu-memory-utilization=0.95" # 显存利用率上限
- "--max-num-batched-tokens=8192" # 批处理 Token 上限
- "--quantization=awq" # 启用 AWQ 量化加速
NUMA 绑定(提升 CPU-GPU 协作效率)
// 在容器 spec 中添加
env:
- name: CUDA_VISIBLE_DEVICES
value: "0,1,2,3"
- name: OMP_NUM_THREADS
value: "16"
8、deepseek 验证与测试
服务状态检查
kubectl get pods -l app=deepseek # 状态应为 Running
kubectl logs <pod名称> | grep "Uvicorn running on" # 确认服务端口启动
性能压测
// 使用 vLLM 基准测试工具
python3 -m vllm.entrypoints.benchmark \
--model /app/model \
--input-len 2048 \
--output-len 512 \
--num-prompts 1000 \
--tensor-parallel-size 4 # 预期吞吐量 > 200 tokens/s
9、deepseek 监控与维护
GPU 指标监控
// 部署 Prometheus GPU Exporter
helm install gpu-monitor prometheus-community/prometheus-node-exporter \
--set nvidia.enabled=true \
--set nvidia.rtx4090.metrics=["utilization","memory_used"]
滚动更新策略
// 镜像更新时触发滚动升级
kubectl set image deployment/deepseek-14b vllm-server=registry.example.com/deepseek-14b:v2
10、 关键参数说明
| 参数/配置 | 推荐值 | 作用说明 |
|---|---|---|
--tensor-parallel-size | 4 | 匹配 GPU 数量实现并行计算加速 |
--gpu-memory-utilization | 0.95 | 防止显存溢出,最大化资源利用率 |
| PVC 存储类型 | NVMe SSD | 减少模型加载延迟(比 HDD 快 5-10 倍) |
| 网络带宽保障 | ≥10Gbps RDMA | 降低多卡通信延迟 |
通过以上步骤,可实现 4×RTX 4090 显卡的高效利用,结合量化技术与分布式推理优化,使 DeepSeek-14B 的推理延迟稳定在 **<500ms**(输入 2048 tokens) 。
11、关键运维实践
- 日志与监控:集成 Prometheus 采集 GPU 使用率和推理延迟指标,通过 Grafana 可视化实时状态 。
- LoRA 动态加载:通过 CRD 管理 LoRA 适配器,支持运行时动态加载不同微调模型版本 。
- 跨集群调度:配置多集群 联邦(如 KubeFed),实现跨集群资源池化调度,需预先定义
CustomResourceDefinition描述跨集群资源 。
12、故障排查要点
- Pod 启动失败:检查 GPU 驱动兼容性及设备插件日志(
kubectl logs -n kube-system <nvidia-device-plugin-pod>) 。 - 性能瓶颈:通过
nvtop或dcgm-exporter分析 GPU 利用率,优化批处理大小(max_batch_size)及注意力分页参数 。
三、基于 Kubernetes + vLLM + Ray 多机多卡集群 部署与容器调度方案
(一)DeepSeek版本 与 GPU 算力 的 适配
根据DeepSeek不同版本特性及消费级GPU部署条件,选型建议如下:
1、模型版本核心差异
| 版本特性 | 满血版(DeepSeek-R1) | 量化版 |
|---|---|---|
| 参数量 | 6710亿参数(671B) | 通过量化技术压缩参数规模 |
| 推理能力 | 支持复杂逻辑推理、长文本生成等高精度任务 | 牺牲部分精度换取速度,适合基础任务 |
| 硬件需求 | 需专业级GPU集群(如A100/H100) | 支持消费级GPU单卡/多卡部署 |
| 适用场景 | 科研机构/企业级复杂任务 | 个人开发者/轻量级应用 |
2、消费级GPU部署方案
量化版选型优先
推荐参数范围:DeepSeek 14B/32B等中等规模模型,通过INT4量化后显存需求可降低至单卡24GB以内 。
典型配置:
- 单卡方案:RTX 4090(24GB显存)可支持14B量化版推理 。
- 多卡方案:2张RTX 4090通过NVLink连接,可部署32B量化版 。
满血版可行性限制
- 显存瓶颈:即使使用INT4量化,671B满血版仍需约380GB显存,远超单卡能力 。
- 分布式部署:需多机多卡组合(如8张RTX 4090),但性价比低于专业级GPU方案 。
3、 选型决策树
**(1) 任务复杂度高 → 选择专业级GPU部署满血版 **
**(2) 资源有限且需快速响应 → 14B/32B量化版 + RTX 4090单卡 **
**(3) 平衡性能与成本 → 多卡RTX 4090部署32B量化版 **
4、注意事项
- 精度验证:第三方量化版可能存在精度损失,需测试生成质量是否符合需求 。
- 网络要求:多卡部署需NVLink或200Gbps以上带宽,避免通信瓶颈 。
- 合规性:若需企业级合规,建议选择L20等专业显卡替代消费级GPU 。
(二)、vLLM 与 Ray 整合方案详解
1 角色分工
vLLM:负责模型推理加速,通过张量并行(Tensor Parallelism)优化单节点多卡性能。
Ray:管理多节点资源调度,实现跨机器的分布式任务编排与通信26。
协作模式:
- 单机多卡:vLLM 独立完成 GPU 并行,无需 Ray 。
- 多机多卡:vLLM 通过
--distributed-executor-backend=ray调用 Ray 协调多节点 。
核心优势
- 弹性扩展:Ray 动态调度资源,支持按需扩缩容 GPU 节点 。
- 混合并行:vLLM 处理张量并行,Ray 管理流水线并行或模型并行 。
(三)、环境准备与组件安装
1 GPU 驱动与容器运行时
为 H20 GPU 节点安装 NVIDIA 驱动 v535+,并配置 nvidia-docker 运行时,启用 nvidia-device-plugin 插件以支持 Kubernetes 识别 GPU 资源。
验证 GPU 资源可见性:
kubectl describe node <node-name> | grep nvidia.com/gpu
2 vLLM 部署
使用 Docker 原生部署 vllm(适用于调试):
使用官方镜像 vllm/vllm:0.7.2,启动参数包含 --tensor-parallel-size 2 --max-model-len 32768 以支持多卡并行 。
通过 Helm 快速部署 vLLM (适用于生产环境):
helm repo add vllm-prod https://vllm-prod.github.io/charts
helm install vllm vllm-prod/vllm -n vllm --set model=deepseek-ai/DeepSeek-R1 --set tensorParallelism=2
通过values.yaml自定义模型路径、显存分配(如gpu_memory_utilization: 0.9)。
3 Ray 集群集成
部署 Ray Operator 至 Kubernetes,通过 Helm Chart 配置多节点集群:
helm install ray-cluster ray/ray -n ray-system --set worker.replicas=2 --set worker.resources.limits.nvidia.com/gpu=8
Worker 节点需声明 GPU 资源请求,确保与 H20 节点调度匹配。
(四)、满血版 DeepSeek 模型部署
模型下载与存储
从魔搭社区或 HuggingFace 下载 DeepSeek-R1 671B 非量化版本(约 1.2TB),挂载至共享存储(如 NFS 或 Alluxio)。
配置 PersistentVolumeClaim 绑定模型存储卷,避免重复下载:
volumes:
- name: model-storage
persistentVolumeClaim:
claimName: deepseek-pvc
多机多卡启动参数
使用 vLLM + Ray 实现跨节点分布式推理:
vllm serve --model=deepseek-ai/DeepSeek-R1 \
--tensor-parallel-size=4 \
--pipeline-parallel-size=2 \
--distributed-executor-backend=ray \
--gpu-memory-utilization=0.9
关键参数说明
| 参数 | 作用 |
|---|---|
--tensor-parallel-size=4 | 单节点内 4 卡张量并行 |
--pipeline-parallel-size=2 | 跨 2 节点流水线并行(需 Ray 协调) |
--distributed-executor-backend=ray | 指定 Ray 为分布式后端 |
(四)、容器调度策略优化
1 资源声明与调度约束
- GPU 资源声明:在 Pod 中明确指定
nvidia.com/gpu: 8,确保独占整机 GPU 资源。 - 节点亲和性:通过
nodeSelector或nodeAffinity绑定 H20 节点标签(如gpu-type: h20)。 - 拓扑分布约束:使用
topologySpreadConstraints分散 Pod 至不同物理机,提升容灾能力。
2 动态扩缩容
HPA 配置:基于请求延迟(http_request_duration_seconds)和 GPU 利用率(DCGM_FI_DEV_GPU_UTIL
)触发扩缩容:
metrics:
- type: Resource
resource:
name: nvidia.com/gpu
target:
type: Utilization
averageUtilization: 70
Cluster Autoscaler:配置 GPU 节点池自动扩容策略,响应突发流量。
3 故障隔离与恢复
为 GPU 节点添加污点(如gpu-reserved: true),Pod 需声明容忍策略:
tolerations:
- key: gpu-reserved
operator: Exists
effect: NoSchedule
启用 Pod 反亲和性,避免单节点部署多个推理实例。
(五)、运维与性能调优
1 监控与日志
指标聚合:集成 Prometheus 采集 GPU 指标(使用 dcgm-exporter)和 vLLM 请求延迟,通过 Grafana 展示实时性能看板。
日志聚合:使用 Fluentd 或 Loki 收集容器日志,关键字段包括 batch_size、prefill_tokens 和 decode_latency。
2 性能调优参数
批处理优化:调整 max_batch_size(建议 32-64)和 max_num_seqs,平衡吞吐与显存占用。
KV 缓存压缩:启用 paged_attention_v2 和 block_size=16,减少显存碎片。
3 跨集群联邦
使用 KubeFed 实现多集群调度,通过 ClusterResourceBinding 定义跨集群 GPU 资源池,支持异地容灾。
(七)、部署验证
1 服务连通性测试
curl -X POST "http://<service-ip>:2023/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{"model": "deepseek-r1:671b", "messages": [{"role": "user", "content": "请解释量子计算原理"}]}'
预期返回 JSON 包含完整推理结果7。
2 性能基准测试
使用 vllm.entrypoints.benchmark 工具测试吞吐量(tokens/sec)和显存占用,对比单机与多机性能差异。
四、生产环境 使用 vLLM 实现大模型 多机多卡的部署
(一)背景
生产环境中,使用vLLM多机多卡集群部署Qwen-72B模型,QPS≥600
(二)评估模型和硬件的规格
- 模型参数:72B(FP16下约144GB显存,通过量化可降低显存占用)。
- 显卡型号:NVIDIA H20 96GB,H20是专为数据中心和企业级应用设计的GPU,拥有针对AI、机器学习和高性能计算(HPC)工作负载优化的功能。H20配备了96GB的HBM3显存,显存带宽高达4TB/s,至少是RTX4090的三倍。
- 框架:使用vLLM,企业级应用中,支持高效并行策略,如张量并行、流水线并行、动态批处理。
- QPS:600(需考虑峰值流量,“二八定律”预留30%冗余)。
(三)性能假设
单卡QPS:根据vLLM官方基准测试,H20在72B模型(4bit量化)下,单卡QPS可达 40-50,若采用 8卡张量并行,单节点QPS可提升至 300-400,但是需要结合实际场景验证。
显存分配:72B模型使用 4bit量化,显存需求降至约 36GB/卡(每个张量并行组需预留冗余,如H20 96GB可支持更灵活配置)。
(四)资源测算步骤
单节点配置(张量并行)
目标:通过多卡协作降低显存压力,提升单节点QPS。
配置方案:
-
张量并行度:8卡/节点,总GPU=(H20 96GB ×8)。
-
显存分配:
每卡显存:96GB,因为72B模型通过4bit量化后,36G左右,需要考虑到冗余和token长度。
总显存利用率:8×96GB=768GB,远超模型需求,支持动态批处理。
-
单节点QPS:vLLM的动态批处理可提升吞吐,通过实时调整批次大小,减少GPU空闲时间,单节点QPS至少可达40。
多节点配置(流水线并行)
目标:通过流水线并行扩展吞吐,达到目标QPS。
配置方案:
-
流水线阶段数:分2阶段处理,每个阶段为一个节点。
-
节点数:
总目标QPS:600 × 1.3(峰值冗余)= 780 QPS。
每节点QPS:400 → 需 2节点,总QPS=2x400,理论上>600
-
网络要求:
节点间需 100Gbps InfiniBand,确保低延迟通信,因为vLLM的流水线并行需高效通信。
(五)、张量并行和管道并行
张量并行

概念:是将模型单层内的参数,比如全连接层的权重矩阵或注意力层的参数,按维度分割到多个GPU上,每个GPU处理参数的一部分。
图解:
- 权重矩阵 A 被切分为 A1 和 A2,分别存储在GPU 1和GPU 2。
- 输入 X 张量复制到所有GPU,每个GPU计算部分结果,那么GPU1和GPU2分别为X·A1 和 X·A2。
- 通过AllReduce通信操作将结果汇总,得到完整的输出 Y=X⋅A
核心目标:降低单卡显存占用,同时保持计算效率.
管道并行
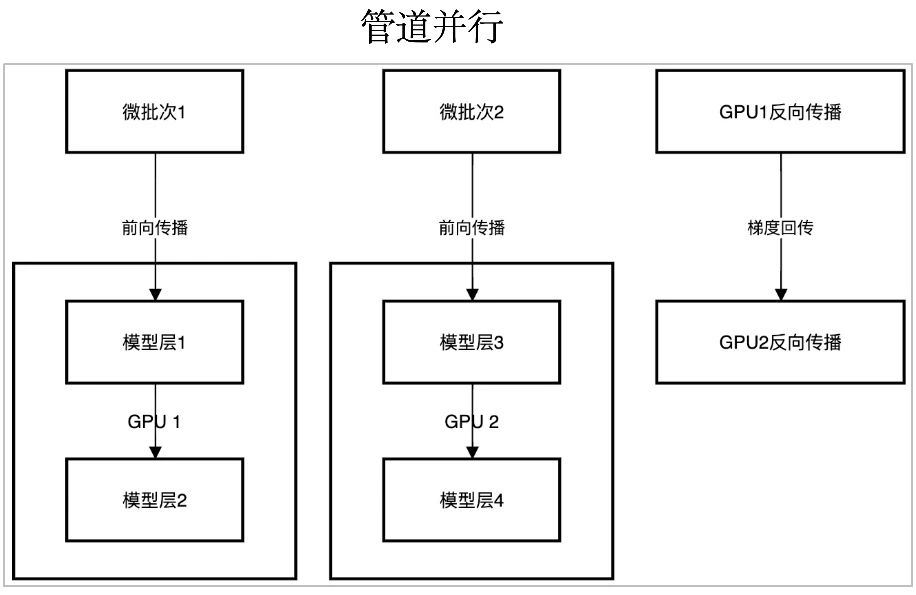
是将模型分层分配到不同GPU上,形成流水线阶段,每个GPU负责连续的若干层。
图解:
- 模型被分为两阶段:GPU 1负责层1和层2,GPU 2负责层3和层4。
- 数据以微批次(micro-batch)形式流动:微批次1在GPU1完成前向后,GPU1立即开始反向传播,同时微批次2进入GPU2进行前向传播。
核心目标:通过重叠计算和通信的方式提升吞度量,适用于模型层数多、单卡无法容纳全部层的场景。
流程:
微批次1的处理:
- 数据输入模型层1(位于GPU 1),完成计算后,结果传递给模型层2(仍位于GPU 1)。
- GPU 1连续处理层1和层2,完成微批次1的前向计算。
微批次2的处理:
- 当微批次1进入GPU 1的层2时,微批次2被输入到模型层3(位于GPU 2)。
- GPU 2处理层3后,结果传递给模型层4(仍位于GPU 2),完成微批次2的前向计算。
关键点:
- 流水线并行:GPU 1和GPU 2同时处理不同微批次的不同层,减少GPU空闲时间。
- 数据流:微批次1和微批次2在不同GPU上并行推进,形成流水线。
反向传播阶段
目标:根据前向传播的输出计算梯度,并更新模型参数。
流程:
GPU 1的反向传播:
- 微批次1的前向完成后,从层2开始反向计算梯度
- 计算层2的梯度后,梯度传递到层1,完成层1的反向计算。
GPU 2的反向传播:
- 微批次2的前向完成后,从层4开始反向计算梯度。
- 计算层4的梯度后,梯度传递到层3,完成层3的反向计算。
使用场景
- 模型层数过多或参数量过大,单GPU无法容纳。
- 具备多GPU集群,需平衡显存和计算资源。
- 需要快速完成多个微批次的迭代,比如在线学习或实时推理
(六)、 网络分层架构
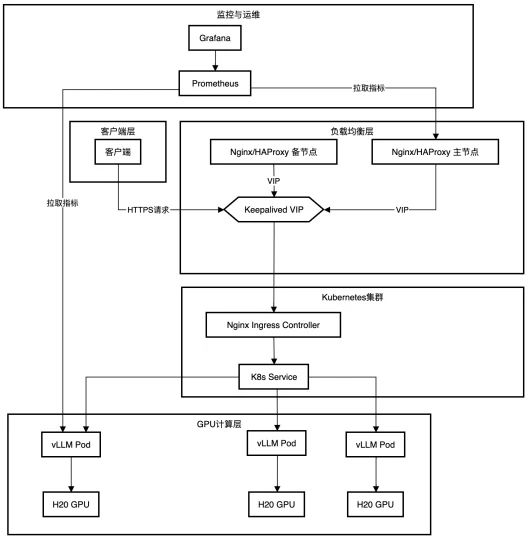
分层架构解析
该架构分为五个层级,各层功能如下:
(1) 客户端层
- 功能:用户与系统的交互入口。
- 客户端:通过HTTPS协议发送请求,触发计算任务或获取结果。
- Prometheus指标拉取:客户端可直接向Prometheus发送查询请求,获取系统监控数据,比如GPU利用率、任务队列长度等。
(2) 负载均衡层
- 功能:确保请求分发的高可用性和负载均衡。
- Nginx/HAPProxy 主备节点:主节点负责接收并分发请求,备节点处于热 standby 状态。
- 通过 VIP(虚拟IP) 对外暴露统一入口,屏蔽主备节点的真实IP。
- Keepalived:监控主节点状态,若主节点故障,自动将VIP切换到备节点,实现无缝故障切换。
(3) Kubernetes集群
- 功能:容器编排与服务管理。
- Nginx Ingress Controller:作为集群的入口网关,将外部流量(来自负载均衡层)路由到集群内部服务。
- 支持基于域名或路径的路由规则配置。
- K8s Service:
- 定义服务访问方式,通过 Service IP 和端口暴露Pod服务。
- 内部负载均衡:自动将流量分发到后端多个Pod,支持轮询、加权等策略。
(4) GPU计算层
- 功能:执行核心的GPU加速计算任务。
- vLLM Pod:每个Pod包含一个或多个容器,运行 vLLM(可能是大模型推理框架,如vLLM是专为Llama系列优化的推理引擎)。
- GPU绑定:每个Pod独占一块H20 GPU,通过Kubernetes的GPU资源请求(如 nvidia.com/gpu: 1)实现资源分配。
- H20 GPU:提供高性能计算能力,加速模型推理或训练任务比如72B大模型的并行计算。
(5) 监控与运维层
- 功能:系统状态监控与可视化。
- Prometheus:持续收集系统指标(如Pod CPU/内存使用率、GPU温度、任务响应时间等)。
- 支持自定义指标(通过Exporter暴露数据)。
- Grafana:将Prometheus数据可视化为仪表盘,展示集群健康状态、资源利用率等。
- 提供报警功能(如通过Alertmanager触发阈值告警)。
优势
高可用性:
- 负载均衡层的主备节点切换机制确保单点故障不影响服务连续性。
- Kubernetes集群自动管理Pod的健康检查和故障重启。
可扩展性:
- GPU计算层可通过Kubernetes的HPA(Horizontal Pod Autoscaler)根据负载动态扩缩Pod数量。
- 集群扩容:新增GPU节点后,Kubernetes自动调度任务至新节点。
资源隔离与效率:
- GPU独占分配:每个vLLM Pod绑定一块H20 GPU,避免资源争用。
- Ingress与Service分层:清晰分离外部流量入口与内部服务发现,提升架构灵活性。
可监测性:
- Prometheus+Grafana 提供端到端监控,支持快速定位性能瓶颈(如GPU利用率低、网络延迟高)。
数据流示例
以用户发起一个推理请求为例:
(1) 客户端发送HTTPS请求至 VIP,进入负载均衡层。
(2) Nginx/HAPProxy 将请求转发到 Kubernetes Ingress Controller。
(3) Ingress Controller 根据路由规则将流量路由到 vLLM Service。
(4) K8s Service 将请求分发到某个 vLLM Pod绑定的H20 GPU执行计算。
(5) 计算结果通过反向路径返回客户端。
(6) 监控数据:Prometheus持续收集各组件指标,Grafana展示实时状态。
(七)、硬件和网络配置
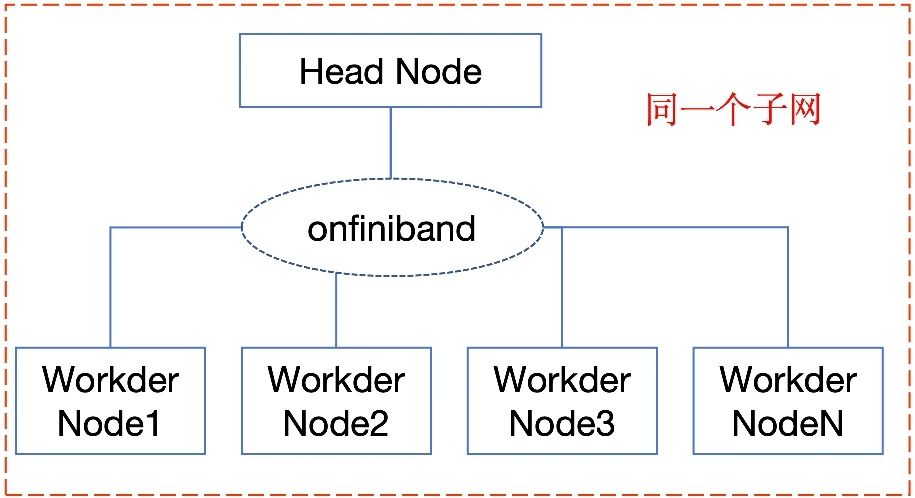
节点配置
| 节点类型 | 规格 |
|---|---|
| 头节点(Head Node) | 2× Intel Xeon Platinum 8380(64核)、512GB 内存、2×100Gbps InfiniBand |
| 工作节点(Worker Node) | 每节点 8× NVIDIA H20(96GB 显存)、Intel Xeon Platinum 8380(64核)、512GB 内存、2×100Gbps InfiniBand |
集群规模
- 节点数量:4 个 工作节点(共 32 张 H20 GPU) + 1 个 头节点。
- 总显存:32×96GB = 3072GB。
- 低延迟网络:使用 InfiniBand EDR/FDR (延迟 < 1μs,带宽 100Gbps)。
- 节点间通信:所有节点处于同一子网,确保无防火墙限制。
- 负载均衡:使用 Nginx 或 HAProxy 分发请求到集群。
环境变量
// 在所有节点设置
export NCCL_SOCKET_IFNAME=mlx5_0
// 指定InfiniBand接口
export NCCL_IB_DISABLE=0
// 启用InfiniBand
export NCCL_DEBUG=INFO # 调试模式(可选)
(八)软件与环境配置
系统环境
| 组件 | 版本/说明 |
|---|---|
| 操作系统 | Ubuntu 22.04 LTS(所有节点) |
| CUDA | CUDA 12.1(所有节点需版本一致) |
| cuDNN | cuDNN 8.9.5(与 CUDA 版本匹配) |
| NCCL | NCCL 2.17(优化多节点通信) |
| PyTorch | PyTorch 2.2.0(支持分布式训练和推理) |
| vLLM | vLLM 0.7.4(最新稳定版) |
| Ray | Ray 2.8.0(分布式集群管理) |
vllM集群配置
vllm给我提供了一个集群部署的脚本,可以用这个脚本
// 启动头节点(Head Node)
bash run_cluster.sh \
vllm/vllm-openai \
ip_of_head_node \
--head \
/path/to/the/huggingface/home/in/this/node
// 启动workder节点
bash run_cluster.sh \
vllm/vllm-openai \
ip_of_head_node \
--worker \
/path/to/the/huggingface/home/in/this/node
可以用ray框架,两个本质上是一样的
// 启动头节点(Head Node)
ray start --head --port=6379 --num-cpus=64 --num-gpus=0 # 头节点不分配GPU
// 在每个工作节点启动(Worker Nodes)
ray start --address="HEAD_NODE_IP:6379" --num-cpus=64 --num-gpus=8
启动命令 如下:
启动命令(在头节点执行)
注意, 在头节点执行
vllm serve Qwen-70B \
--tensor-parallel-size 8 \ # 每节点8卡,模型分片到8个GPU
--pipeline-parallel-size 2 \ # 流水线并行阶段数(跨节点)
--max-batch-size 256 \ # 最大批次大小(支持高并发)
--max-num-batched-tokens 120000 \ # 每批次最大token数
--swap-space 16 \ # CPU交换空间(16GB/节点)
--max-model-len 32768 \ # 最大序列长度
--host 0.0.0.0 --port 8000 \ # 服务地址
--gpu-memory-utilization 0.9 \ # 显存利用率90%
--nodes 4 \ # 调度4个节点
--num-gpus-per-node 8 # 每节点8卡
RDMA优化配置:
// 在所有节点启用RDMA
export NCCL_SOCKET_IFNAME=^docker0
export NCCL_DEBUG=INFO
(九)、 部署步骤
安装依赖
// 在所有节点执行
sudo apt install nvidia-driver-535
wget https://developer.download.nvidia.com/compute/cuda/12.1.1/local_installers/cuda_12.1.1_535.86.07_linux.run
sudo sh cuda_12.1.1_535.86.07_linux.run --silent --override
// 安装cuDNN和NCCL
wget https://developer.download.nvidia.com/compute/redist/cudnn/v8.9.5/cudnn-linux-x86_64-8.9.5.50_cuda12-archive.tar.xz
tar -xvf cudnn-linux-x86_64-8.9.5.50_cuda12-archive.tar.xz -C /usr/local
wget https://github.com/NVIDIA/nccl/releases/download/v2.17.3/nccl_2.17.3-1+cuda12.1_x86_64.txz
sudo tar -xvf nccl_2.17.3-1+cuda12.1_x86_64.txz -C /usr/local
//安装PyTorch和vLLM
conda create -n vllm_env python=3.10
conda activate vllm_env
pip install torch==2.2.0+cu121 vllm[all] ray[tune]
启动 vLLM 服务
// 在头节点执行
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 vllm serve Qwen-70B \
--tensor-parallel-size 8 \
--pipeline-parallel-size 2 \
--max-batch-size 256 \
--max-num-batched-tokens 120000 \
--swap-space 16 \
--max-model-len 32768 \
--host 0.0.0.0 --port 8000 \
--gpu-memory-utilization 0.9 \
--nodes 4 \
--num-gpus-per-node 8
监控工具
- NVIDIA Nsight:监控 GPU 利用率和显存占用。
- Ray Dashboard:查看集群任务分配和资源利用率。
- Prometheus + Grafana:全局监控 QPS、延迟和错误率。
性能测试
// 使用wrk2压测
wrk -t128 -c1000 -d30s -H "Content-Type: application/json" --latency http://<load_balancer_ip>/v1/models/Qwen-72B:predict
参数解释:
-t128 线程数为128
-c100 设置并发连接数为 1000
-d30s 测试将持续 30 秒
--latency 收集并报告延迟统计信息
总结
按照如下步骤逐步的验证
(1) 单卡性能调优 → 2. 单节点扩展 → 3. 多机联合测试 → 4. 全集群压力测试。
遇到问题,找老架构师取经
借助此文,尼恩给解密了一个高薪的 秘诀,大家可以 放手一试。保证 屡试不爽,涨薪 100%-200%。
后面,尼恩java面试宝典回录成视频, 给大家打造一套进大厂的塔尖视频。
通过这个问题的深度回答,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
在面试之前,建议大家系统化的刷一波 5000页《尼恩Java面试宝典PDF》,里边有大量的大厂真题、面试难题、架构难题。
很多小伙伴刷完后, 吊打面试官, 大厂横着走。
在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
另外,如果没有面试机会,可以找尼恩来改简历、做帮扶。
遇到职业难题,找老架构取经, 可以省去太多的折腾,省去太多的弯路。
尼恩指导了大量的小伙伴上岸,前段时间,刚指导一个40岁+被裁小伙伴,拿到了一个年薪100W的offer。
狠狠卷,实现 “offer自由” 很容易的, 前段时间一个武汉的跟着尼恩卷了2年的小伙伴, 在极度严寒/痛苦被裁的环境下, offer拿到手软, 实现真正的 “offer自由” 。

















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









