







爬虫进阶之爬取图片
前言
这几天的SCTF被队里大佬带飞,属实很顶,题目复现不了。。枯了,于是乎来看看爬虫,想法是先慢慢来,熟悉了之后上框架可能效果好一些,又想暑假的时候玩一玩tensorflow,所以可以整个爬百度图片的爬虫。
正文
首先我是直接在百度图片上搜个玫瑰,但是发现是以json数据返回的,因此无法使用Beautifulsoup来处理html,因此在这里的想法是找到数据包请求参数的规律,得到响应包的json,在通过正则或者其他关键字得到jpg的url,当我下拉数据时,会发现:

acjson不断更新,但是请求参数却没有发生啥变化,这里关键词是可以控制的,即我们搜索的关键词,唯一发生变化的参数:
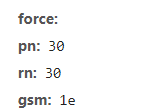

即pn参数,并且是以30的整数倍增加,这里推测应该是正好下一页了,pn代表已经加载的图片数,因此在之后的写爬虫过程中,我们就能通过pn参数来控制图片的数量,并且不会重复
因此在这里思路大概就有了,当我们把可控的关键词设置好,并且设置page
参数是30的整数倍,然后请求包的其他参数都不变化,这样我们就能找到指定关键词的json包了,然后通过提取json包中的thumbURL,这个参数对应的就是图片的url了,最后把这些url请求一遍,res.content就是照片的二进制数据,写入一个指定文件夹中即可。

这里贴下代码(代码参考了其他大佬的):
#coding=utf-8
import requests
import re
import os
def getpages(keyword,pages):
params=[]
for i in range(30,30*pages+30,30):
params.append({
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': 201326592,
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': 2,
'lm': -1,
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': -1,
'z': '',
'ic': 0,
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': 0,
'istype': 2,
'qc': '',
'nc': 1,
'fr': '',
'pn': i,
'rn': 30,
'gsm': '1e',
'1488942260214': ''
})
url = 'https://image.baidu.com/search/acjson'
urls = []
for i in params:
urls.append(requests.get(url,params=i).json().get('data'))
return urls
def downImg(datalist,dirname):
x = 0
for i in datalist:
for url in i:
if(url.get('thumbURL')!=None):
print("----正在下载{}----".format(url.get('thumbURL')))
photo = requests.get(url.get('thumbURL'))
open(dirname + '%d.jpg' % x, 'wb').write(photo.content)
x+=1
else:
print("图片链接不存在!")
if __name__ == '__main__':
datalist = getpages("百合花",3)
downImg(datalist,"C:\\Users\\86189\\Desktop\\baihe\\")
只需要修改关键字和参数还有路径即可
注意路径后还要双写反斜杠,不然对应不上绝对路径
最后附上效果图(可能有一部分路径和照片是无效的,最终只需删去即可)


这是未经过修改的,看起来匹配度还挺高的,可以暑假之后玩玩Tensorflow了















 9068
9068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









