







 本文详细介绍了DOM(文档对象模型)的核心概念,包括节点类型、节点属性(如nodeType、nodeName、nodeValue)以及节点关系(如childNodes、parentNode等)。重点讲解了如何操作节点,如appendChild、insertBefore、replaceChild、removeChild,以及节点的其他方法如cloneNode和normalize。此外,文章还涵盖了Document类型,包括访问文档子节点、文档信息(如title、URL、domain、referrer)以及查找元素的方法(如getElementById、getElementsByTagName、getElementsByName)。Element类型和Text类型的相关操作,如设置和获取特性、创建元素、文本节点的处理,也被详细阐述。通过本文,读者将对DOM节点操作有全面深入的理解。
本文详细介绍了DOM(文档对象模型)的核心概念,包括节点类型、节点属性(如nodeType、nodeName、nodeValue)以及节点关系(如childNodes、parentNode等)。重点讲解了如何操作节点,如appendChild、insertBefore、replaceChild、removeChild,以及节点的其他方法如cloneNode和normalize。此外,文章还涵盖了Document类型,包括访问文档子节点、文档信息(如title、URL、domain、referrer)以及查找元素的方法(如getElementById、getElementsByTagName、getElementsByName)。Element类型和Text类型的相关操作,如设置和获取特性、创建元素、文本节点的处理,也被详细阐述。通过本文,读者将对DOM节点操作有全面深入的理解。
DOM(文档对象模型)是针对HTML和XML文档的一个API,描绘了一个层次化的节点树。
DOM可以将任何HTML或XML文档描绘成一个由多层节点构成的结构。
节点分为几种不同的类型。
文档节点是每个文档的根节点。html元素为文档元素。
- 文档元素是文档的最外层元素
- 文档中的其他所有元素都包含在文档元素中。
- 每个文档都只能有一个文档元素。
在html页面中,文档元素始终都是html元素。

在这里用脑图总结了一下各个节点类型,清晰版
Node类型
DOM1定义了一个Node接口,该接口将由DOM中的所有节点类型实现。
这个Node接口在js中是作为Node类型实现的。js中所有节点类型都继承自Node类型,因此所有节点类型都共享着相同的基本属性和方法。
nodeType属性
每一个节点都有一个nodeType属性,用于表明节点的类型。
节点类型由在Node类型中定义的下列12个数值常量来表示:
- Node.ELEMENT_NODE(1)
- Node.ARRIBUTE_NODE(2)
- Node.TEXT_NODE(3)
- Node.CDATA_ SECTION_NODE(4)
- Node.ENTITY_REFERENCE _NODE(5)
- Node.ENTITY_NODE(6)
- Node.PROCESSING_INSTRUCTION_NODE(7)
- Node.COMMENT_NODE(8)
- Node.DOCUMENT_NODE(9)
- Node.DOCUMENT_TYPE_NODE(10)
- Node.DOCUMENT_FRAGMENT_NODE(11)
- Node.NOTATION_NODE(12)
通过比较节点的nodeType与上面这些常量,可以很容易地确定节点的类型。
if(someNode.nodeType == Node.ELEMENT_NODE){
alert("node is an element");
}为了确保跨浏览器兼容,最好还是将nodeType属性与属性值进行比较:
if(someNode.nodeType == 1){
alert("node is an element");
}nodeName和nodeValue属性
这两个属性值完全取决于节点的类型,因此在使用这两个值以前最好先检测一下节点的类型:
if(someNode.nodeType == 1){
value = someNode.nodeName; //nodeName的值是元素的标签名
}在这个例子中,首先检查节点类型,看它是不是一个元素。
对于一个元素节点,nodeName中保存的始终都是元素的标签名,nodeValue的值则始终为null。
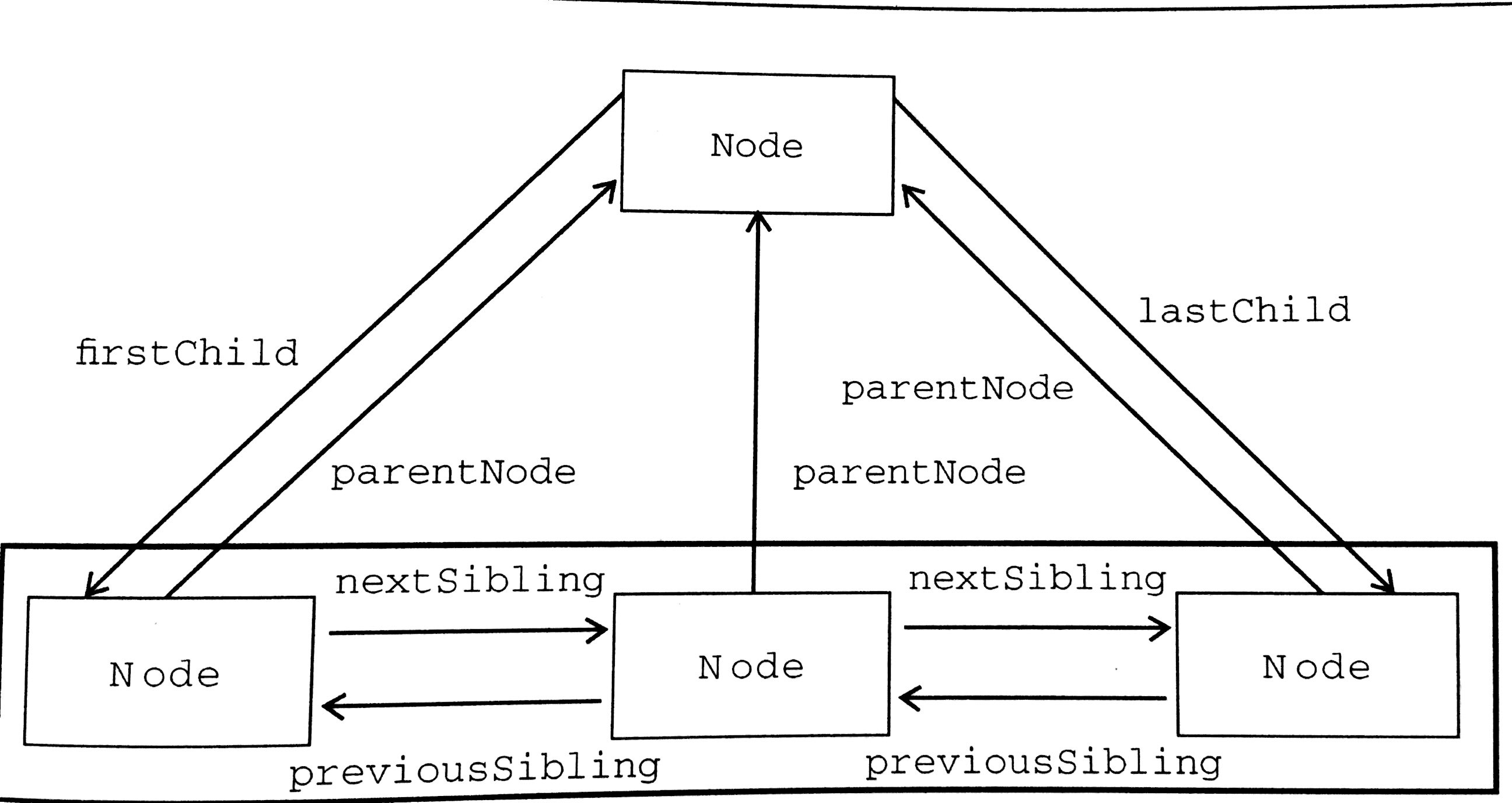
节点关系
childNodes
每个节点都有一个childNodes属性,其中保存着一个NodeList对象。
NodeList是一种类数组对象,用于保存一组有序的节点,可以通过位置来访问这些节点。
虽然可以通过方括号语法来访问NodeList的值,而且这个对象也有length属性,但它并不是Array类型的实例。
NodeList对象的独特之处在于,它实际上是基于DOM结构动态查询的结果,因此DOM结构的变化能够自动反映在NodeList中。
下面的例子展示了如何访问保存在NodeList中的节点:可以通过方括号,也可以使用item()方法。
var firstChild = someNode.childNodes[0];
var secondChild = someNode.childNodes.item(1);
var count = someNode.childNodes.length;其中length属性表示的是访问NodeList的那一刻,其中包含的节点数量。
之前介绍过,对arguments对象使用Array.prototype.slice()方法可以将其转换为数组,我们也可以对NodeList对象采取同样的方法,从而将其转换为数组:
var ArrayNodes = Array.prototype.slice.call(someNode.childNodes,0);parentNode
每个节点都有一个parentNode属性,该属性指向文档树中的父节点。
包含在childNodes列表中的所有节点都具有相同的父节点,因此他们的parentNode属性都指向同一个节点。
previousSibling nextSibling
包含在childNodes列表中的每个节点相互之间都是同胞节点,通过使用每个节点的previousSibling和nextSibling属性,可以访问到同一列表中的其他节点。
- 列表中第一个节点的previousSibling属性为null。
- 列表中最后一个节点的nextSibling属性也为null。
- 如果列表中只有一个节点,那么该节点的previousSibling和nextSibling属性都为null
firstChild lastChild
- 父节点的firstChild属性指向其childNodes列表中的第一个节点。值始终等于childNodes[0]
父节点的lastChild属性指向其childNodes列表中的最后一个节点。值始终等于childNodes[childNodes.length-1]
在只有一个子节点的情况下,firstChild和lastChild指向同一个节点。
- 如果没有子节点,那么firstChild和lastChild都为null。
hasChildNodes()
此方法在节点包含一或多个子节点的情况下返回true。
比查询childNodes列表的length属性更简单。
ownerDocument
所有节点都有这个属性,该属性指向标是整个文档的文档节点。
这种关系表示的是任何节点都属于它所在的文档,任何节点都不能同时存在于两个或更多个文档中。
通过这个属性,我们可以不必在节点层次中通过层层回溯到达顶端,而是可以直接访问文档节点。
操作节点
appendChild()
- 用于向childNodes列表的末尾添加一个节点。
- 添加节点后,childNodes的新增节点、父节点、以及以前的最后一个子节点的关系指针都会相应地得到更新。
- 更新完成后,appendChild()返回新增的节点
var returnedNode = someNode.appendChild(newNode);
alert(returnedNode == newNode); //true
alert(someNode.lastChild == returnedNode); //true如果传入到appendChild中的节点已经是文档的一部分了,那结果就是将该节点从原来的位置转移到新位置。
即使可以将DOM树看成是由一系列指针连接起来的,但任何DOM节点也不能同时出现在文档中的多个位置上。
因此,如果在调用appendChild()时传入的是父节点的第一个子节点,那么该节点就会成为父节点的最后一个子节点。
var returnedNode = someNode.appendChild(someNode.firstChild);
alert(someNode.firstChild == returnedNode); //false
alert(someNode.lastChild == returnedNode); //trueinsertBefore()
如果需要把节点放在childNodes列表中某个特定的位置上,而不是放在末尾,那么可以使用insertBefore方法。这个方法接收两个参数:要插入的节点和作为参照的节点。
插入节点后,被插入的节点会变成参照节点的前一个同胞节点, 同时被方法返回。
如果参照节点是null,则insertBefore()与appendChild()执行相同的操作。
//插入后成为最后一个子节点
returnedNode = someNode.insertBefore(newNode,null);
alert(someNode.lastChild == returnedNode); //true
//插入后成为第一个子节点
returnedNode = someNode.insertBefore(newNode,someNode.firstNode);
alert(newNode == returnedNode); //true
alert(someNode.firstChild == returnedNode); //true
//插入到最后一个子节点前面
returnedNode = someNode.insertBefore(newNode,someNode.lastNode);
alert(returnedNode == someNode.childNodes[someNode.childNodes.length-2]); //true到此介绍的appendChild()和insertBefore()都只插入节点,不会移除节点。
replaceChild()
此方法接收两个参数,要插入的节点和要替换的节点。
要替换的节点将由这个方法返回并从文档树中移除,同时由要插入的节点占据其位置。
//替换第一个子节点
var returnedNode = someNode.replaceChild(newNode,someNode.firstChild);
//替换最后一个子节点
var returnedNode = someNode.replaceChild(newNode,someNode 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









