







pytest 生成器、装饰器、迭代器介绍
pytest简单介绍
pytest 是一个功能强大且易于使用的 Python 测试框架。它提供了丰富的功能和灵活的扩展机制,使得编写和运行测试变得简单和高效。
装饰器的介绍
在pytest测试框架中,装饰器是一种用于修改、扩展或定制测试函数行为的机制。本质上是一个函数。pytest提供了多个内置的装饰器,用于标记测试函数、控制测试执行、参数化测试等。
它可以在不改变函数调用方式的前提下,通过在被装饰函数的定义之前使用@符号来应用装饰器。
pytest 中常用的装饰器
@pytest.fixture
在pytest测试框架中,夹具(fixture)是一种用于为测试用例提供预置环境或共享资源的机制。夹具可以用于初始化测试数据、创建对象、连接数据库、模拟网络请求等操作。
夹具在测试用例的执行过程中起到了关键的作用,它们可以在测试用例执行之前或之后执行特定的操作,以确保测试环境的正确设置和清理。夹具的使用可以帮助我们更方便地组织和管理测试代码,提高代码的可重用性和可维护性。
在pytest中,夹具可以通过使用@pytest.fixture装饰器来定义。夹具函数可以具有不同的作用域,包括函数级别、模块级别、类级别和会话级别,根据需要选择适当的作用域。
import pytest
@pytest.fixture
def setup_database():
# 设置数据库连接
db = connect_to_database()
# 返回数据库连接对象
yield db
# 在测试后关闭数据库连接
db.close()
def test_database_operations(setup_database):
# 使用夹具提供的数据库连接对象进行数据库操作
fixture 常用参数
scope
指定 fixture 的作用域,控制其生命周期和适用范围。可选值包括 “function”(函数级别,默认)、“class”(类级别)、“module”(模块级别)、 “session”(会话级别)。
function: 函数级,每个测试函数都会执行一次固件;
class: 类级别,每个测试类执行一次,所有方法都可以使用;
module: 模块级,每个模块()执行一次,模块内函数和方法都可使用
session: 会话级,一次测试只执行一次,所有被找到的函数和方法都可用。
备注:模块是一个包含函数、变量和类等定义的文件。模块可以是一个独立的 .py 文件,也可以是包中的一个 .py 文件。
import pytest
@pytest.fixture(scope="module")
def setup_module():
# ...
@pytest.fixture(scope="class")
def setup_class():
# ...
@pytest.fixture(scope="function")
def setup_function():
# ...
@pytest.fixture(scope="session")
def setup_session():
# ...
autouse
指定是否自动应用 fixture,默认值为 False,需要在测试函数中显式使用 fixture。设置为 True 后,fixture 将自动应用于所有测试函数。
import pytest
@pytest.fixture(autouse=True)
def setup():
# 自动应用 fixture
# ...
params
允许为 fixture 提供不同的参数化值,从而生成多个实例。可以是单个值、列表、元组或参数化装饰器生成的值。
import pytest
@pytest.fixture(params=[1, 2, 3])
def setup(request):
value = request.param
# 使用 value 进行设置操作
# ...
name
指定 fixture 的名称。默认情况下,fixture 的名称是函数名。
import pytest
@pytest.fixture(name="custom_fixture_name")
def setup_function():
# ...
params 和 ids
在参数化 fixture 时,params 参数用于指定参数值,ids 参数用于指定参数值的标识符,以便在测试报告中更好地显示。
import pytest
@pytest.fixture(params=[("apple", 3), ("banana", 5)], ids=["fruit1", "fruit2"])
def setup(request):
fruit, quantity = request.param
yield fruit, quantity
def test_fruit_count(setup):
fruit, quantity = setup
assert quantity > 0
print(f"There are {quantity} {fruit}(s).")
在上面的示例中,我们定义了一个 setup 的 fixture,使用 params 参数为其提供了两组参数值:(“apple”, 3) 和 (“banana”, 5)。同时,我们使用 ids 参数为每组参数值指定了相应的标识符:“fruit1” 和 “fruit2”。
在测试函数 test_fruit_count 中,我们使用 setup 作为参数并解包得到 fruit 和 quantity。然后我们进行断言,确保 quantity 大于 0,并输出对应的水果数量。
当我们运行这个测试时,它会生成两个测试实例,分别对应于每组参数值。在测试报告中,这些参数化的测试实例将以指定的标识符进行标识,让我们更清晰地了解每次测试的上下文和参数值:
test_example.py::test_fruit_count[fruit1] PASSED
test_example.py::test_fruit_count[fruit2] PASSED
@pytest.mark.parametrize
@pytest.mark.parametrize 装饰器用于参数化测试函数,允许为测试函数提供多组输入参数。这样可以重复运行测试,并自动展开所有组合的参数。
可以传递不同的参数类型,以下为常见的参数类型
单个参数值:
@pytest.mark.parametrize("name", ["Alice", "Bob", "Charlie"])
def test_greet(name):
print(f"Hello, {name}!")
上述示例中,name 参数会依次取值为 “Alice”、“Bob” 和 “Charlie”,每个值都会作为参数传递给 test_greet 测试函数。
多个参数值:
@pytest.mark.parametrize("x, y, expected", [
(1, 2, 3),
(10, 20, 30),
(-5, 5, 0),
])
def test_addition(x, y, expected):
assert add(x, y) == expected
在上述示例中,x、y 和 expected 分别表示两个输入参数和预期输出。通过列表中的元组,你可以定义多个测试情况,每个测试情况都会传递相应的参数给 test_addition 测试函数。
参数组合:
@pytest.mark.parametrize("x", [1, 2])
@pytest.mark.parametrize("y", [10, 20])
def test_multiply(x, y):
print(x,y)
在上述示例中,x 和 y 的参数值会进行组合,生成四个测试情况:(1, 10)、(1, 20)、(2, 10) 和 (2, 20)。每个组合都会作为参数传递给 test_multiply 测试函数。
参数化元组或字典:
tuple_1 = [("Alice", 25), ("Bob", 30)]
key_1 = [{"Alice": 25, "Bob": 30}]
@pytest.mark.parametrize("person", tuple_1)
def test_age(person):
name, age = person # 将元组的值,赋值给name,age变量
print(f"name:{name},age:{age}")
# 打印结果
# test_convert.py::test_age[person0] PASSED [ 50%]name:Alice,age:25
# test_convert.py::test_age[person1] PASSED [100%]name:Bob,age:30
在上述示例中,person 参数被定义为一个元组列表,每个元组包含姓名和年龄。test_age 测试函数将分别解包元组中的值,并进行打印。
@pytest.mark.skip
只有在满足某些条件时测试才能通过,否则pytest应该跳过运行测试
-
无条件跳过模块中的所有测试:
pytestmark = pytest.mark.skip(reason=“all tests still WIP”) -
根据某些条件跳过模块中的所有测试:
pytestmark = pytest.mark.skipif(sys.platform == “win32”, reason=“tests for linux only”) -
如果缺少某些导入,则跳过模块中的所有测试:
pexpect = pytest.importorskip(“pexpect”) 此为函数应用
@pytest.mark.xfail
将功能标记为预期失败
reason参数:用于说明预期失败的原因。
strict:用于指定是否严格检查预期失败
run:用于指定在哪些条件下运行测试。
"always":无论测试结果如何,始终运行测试(默认值)。
"passed":只有当测试通过时才运行测试。
"failed":只有当测试失败时才运行测试。(如果测试成功,那就会跳过此用例)
"skipped":只有当测试被跳过时才运行测试。
raises:用于指定预期的异常类型。(如果返回的错误非预期异常,用例结果为failed)
strict举例
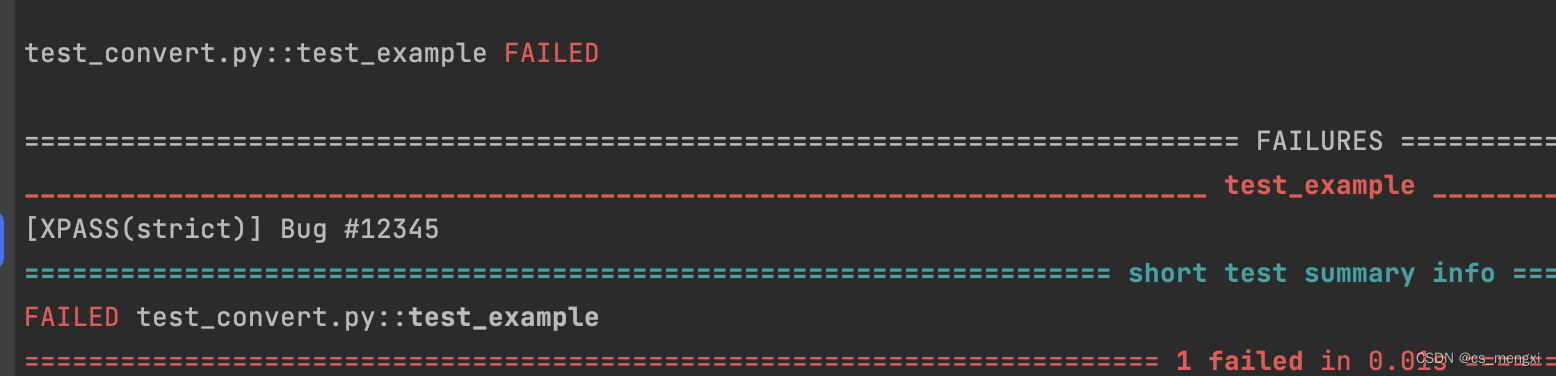
# strict=False, 如果测试预期失败,实际测试通过,结果依旧为XPASS
# strict=True, 如果测试预期失败,实际测试通过,结果依旧为FAILD
# strict=True或False, 如果测试预期失败,实际测试也失败,结果为 XFAIL
# 如不给strict参数,strict=False(默认值)
import pytest
@pytest.mark.xfail(strict=True, reason="Bug #12345")
def test_example():
assert 1 + 1 == 3


自定义装饰器
在 Pytest 中,除了使用内置的装饰器,也可以使用自定义装饰器来扩展测试框架的功能。
import pytest
def my_custom_decorator(func):
def wrapper(*args, **kwargs):
# 在测试函数之前执行的代码
print("Before test")
# 调用原始的测试函数
result = func(*args, **kwargs)
# 在测试函数之后执行的代码
print("After test")
return result
return wrapper
# 使用自定义装饰器标记测试函数
@my_custom_decorator
def test_example():
assert 1 + 1 == 2
# 运行测试
pytest.main()
在上面的示例中,my_custom_decorator 是一个自定义装饰器函数。它接受一个函数作为参数,并返回一个内部函数 wrapper。在 wrapper 函数中,你可以执行在测试函数前后需要进行的操作,然后调用原始的测试函数。
将自定义装饰器应用于测试函数时,使用 @ 符号将装饰器应用于目标函数上方。在示例中,@my_custom_decorator 标记了 test_example 函数,使其在运行时被自定义装饰器包装执行。
如何判断一个函数是不是装饰器
-
函数接受一个函数作为参数:装饰器是一个函数,通常会接受另一个函数作为参数。这个参数表示需要被装饰的目标函数。
-
函数内部定义了一个包装函数或返回函数:装饰器通常会在内部定义一个包装函数,用于包裹原始函数,并在包装函数内部执行一些额外的操作。或者,装饰器可以返回一个新的函数,该函数用于替代原始函数。
-
装饰器返回的函数能够被调用:装饰器返回的函数应该可以像原始函数一样被调用,即具有相同的调用方式和参数。
备注:仅仅满足上述特征并不意味着一个函数一定是装饰器。在 Python 中,函数具有很大的灵活性,可以以各种方式组织和使用。因此,对于一个函数是否是装饰器,最终的判断还需要考虑上下文和函数的实际用途。
生成器的介绍
生成器(Generator)是一种特殊类型的函数,它可以通过使用 yield 语句来生成一系列的值,而不是一次性返回所有的值。生成器在每次迭代时生成一个值,并在生成值后暂停执行,保存其内部状态,以便下次迭代时从暂停的地方继续执行。
生成器是一种特定的迭代器。
def fibonacci():
a, b = 0, 1
while True:
yield a
a, b = b, a + b
# 使用生成器生成斐波那契数列的前 10 个数
fib_gen = fibonacci()
for _ in range(10):
print(next(fib_gen))
以上示例中的 fibonacci 函数是一个生成器函数,通过 yield 语句逐个生成斐波那契数列的值。在使用生成器时,通过调用 next() 函数来获取下一个生成的值。
生成器在 Python 中是非常强大和灵活的工具,可以帮助处理各种数据处理和计算任务。它们提供了一种高效、简洁和可扩展的编程模式。
生成器的特点和优势
-
懒加载(Lazy Evaluation):生成器逐个生成值,只在需要时才计算和返回,从而节省内存和计算资源。这对于处理大型数据集或无限序列非常有用。
-
延迟计算(Deferred Computation):生成器可以根据需要延迟计算值,而不是一次性计算所有值。这样可以提高程序的性能和效率。
-
状态保存:生成器在每次生成值后,可以保存其内部状态,包括变量的值和执行位置。这使得生成器能够从上次暂停的地方继续执行,而不需要重新计算或重复操作。
-
简洁性:使用生成器可以以更简洁的方式编写代码,避免显式创建和管理临时列表或迭代器。
迭代器的介绍
迭代器(Iterator)是一种用于遍历集合或序列的对象,它提供了一种逐个访问元素的方式。迭代器实现了迭代协议(Iterator Protocol),即具有 iter() 和 next() 方法。
迭代器的内部都有一个__next__() 方法,来返回下一个元素,当我们调用内置函数next(迭代器)时,本质就是迭代器.next()
备注:迭代器一定是一个可迭代对象,但可迭代对象不一定是一个迭代器
示例
enumerate()
Python 内置函数 enumerate() 返回的是一个迭代器对象,它具有迭代器的方法和行为,包括 iter() 和 next() 方法。
__iter__() 方法:返回迭代器对象自身。在使用 iter(enumerate(iterable)) 创建迭代器时,该方法被隐式调用。
__next__() 方法:返回迭代器的下一个元素。在使用 next(enumerator) 获取迭代器的下一个值时,该方法被调用。
fruits = ['apple', 'banana', 'orange']
enumerator = enumerate(fruits)
# 使用 iter() 方法创建迭代器
iterator = iter(enumerator)
# 使用 next() 方法获取迭代器的下一个元素
print(next(iterator)) # 输出: (0, 'apple')
print(next(iterator)) # 输出: (1, 'banana')
print(next(iterator)) # 输出: (2, 'orange')
在这个示例中,我们首先使用 enumerate(fruits) 创建一个迭代器 enumerator。然后我们使用 iter() 方法将其转换为迭代器对象 iterator。接下来,我们使用 next() 方法连续调用迭代器的 next() 方法来获取迭代器的下一个元素。
自定义迭代器类
class MyIterator:
def __init__(self, data):
self.data = data
self.index = 0
# 迭代器必须实现__iter__() 方法,返回一个迭代器对象(其自身即可)
def __iter__(self):
return self
# 迭代器必须实现__next__() 方法,每调用一次就返回下一个元素
def __next__(self):
if self.index >= len(self.data):
raise StopIteration
value = self.data[self.index]
self.index += 1
return value
# 创建一个自定义序列
my_sequence = [1, 2, 3, 4, 5]
# 创建迭代器对象
my_iterator = MyIterator(my_sequence)
# 使用迭代器遍历序列
for item in my_iterator:
print(item)
在上述示例中,MyIterator 类实现了迭代器协议,具有 iter() 和 next() 方法。iter() 方法返回迭代器对象本身,而 next() 方法根据当前位置返回下一个元素,并更新迭代器的状态。
通过使用自定义的迭代器对象 my_iterator,可以通过简单的 for 循环遍历自定义序列 my_sequence 中的元素。
需要注意的是,当迭代器达到序列的末尾时,它会引发 StopIteration 异常,以通知循环停止迭代。
迭代器在 Python 中广泛应用于各种场景,包括遍历列表、文件读取、数据库查询等。它们提供了一种高效、可定制和统一的方式来处理和访问数据集合。


















 721
721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









