






导读
在当今数字化时代,信息的爆炸式增长给人们获取知识带来了前所未有的挑战。如何从海量复杂格式的文档中快速准确地提取有价值的信息,成为众多企业和个人面临的难题。RAGFlow 作为一款开源的 RAG(Retrieval-Augmented Generation)引擎,凭借其强大的深度文档理解能力,为企业和个人提供了一种高效的解决方案。本文将深入探讨 RAGFlow 的核心概念、功能特点、应用场景以及使用方法,帮助读者全面了解这一创新工具。
目录
什么是 RAG(Retrieval-Augmented Generation)?
摘要
RAGFlow 是由 Infiniflow 团队开发的开源 RAG 引擎,专注于深度文档理解。它通过结合大型语言模型(LLM)和检索增强生成技术,实现了从复杂格式文档中提取知识并提供准确回答的能力。RAGFlow 支持多种数据源、提供可视化文本切分、减少幻觉引用等功能,适用于文档问答、知识管理、智能客服等多种场景。本文将详细介绍 RAGFlow 的架构设计、功能特点、部署方法以及应用场景,并探讨其在实际应用中的注意事项和未来发展方向。
概念讲解
什么是 RAG(Retrieval-Augmented Generation)?
RAG 是一种结合了检索(Retrieval)和生成(Generation)的技术范式。传统生成模型仅依赖于输入提示进行内容创作,而 RAG 则通过从大规模文档中检索相关信息,为生成模型提供上下文支持,从而提高回答的准确性和可靠性。这种技术特别适用于需要精确信息引用的场景,例如文档问答和知识库查询。
什么是 RAGFlow?
RAGFlow 是一个基于深度文档理解的开源 RAG 引擎。它专注于从复杂格式的文档中提取知识,并结合大型语言模型(LLM)生成准确、可靠的问答内容。RAGFlow 提供了自动化的 RAG 工作流,支持多种数据源(如 Word、Excel、PDF、网页等),并具备以下核心特点:
-
深度文档理解:能够解析复杂格式文档,提取高质量知识。
-
减少幻觉引用:通过可视化文本切分和引用追踪,降低模型产生幻觉信息的可能性。
-
多数据源兼容:支持多种文件格式和数据类型。
-
灵活的部署选项:支持 Docker 部署和本地开发环境。
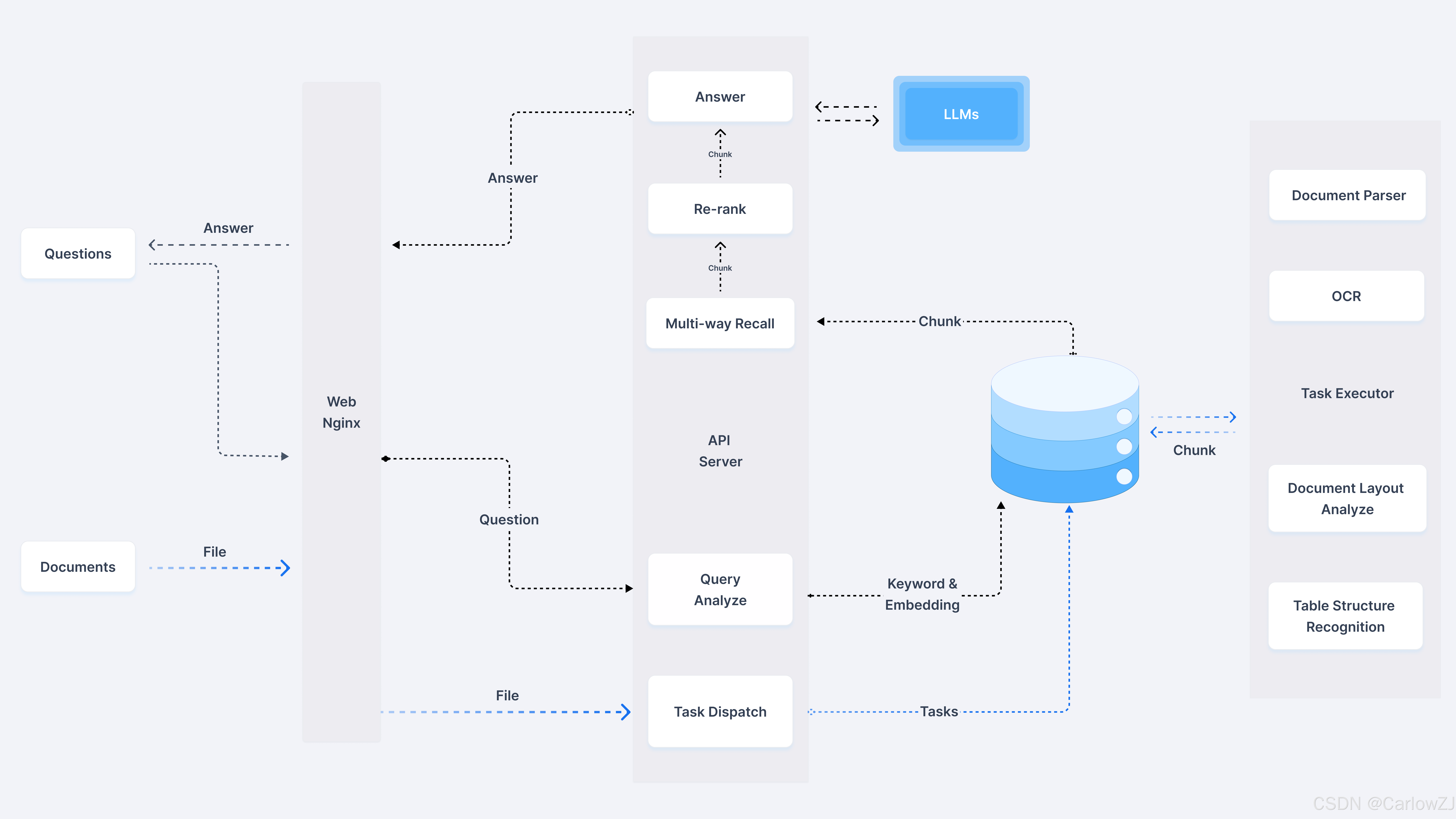
系统架构
架构图
RAGFlow 的架构主要由以下几个模块组成:
-
文档处理模块:
-
负责解析和处理各种格式的文档(如 Word、PDF、Excel 等)。
-
使用深度文档理解技术提取文本内容和结构信息。
-
-
检索模块:
-
基于向量数据库(如 Elasticsearch 或 Infinity)存储和检索文档片段。
-
支持高效的文本检索和语义搜索。
-
-
生成模块:
-
集成大型语言模型(如 OpenAI 的 GPT 系列、DeepSeek 等)生成问答内容。
-
结合检索到的文档片段提供准确、可靠的回答。
-
-
API 服务模块:
-
提供 RESTful API 接口,方便与其他系统集成。
-
支持用户自定义配置和扩展。
-
-
前端交互模块:
-
提供用户友好的界面,支持文档上传、问答交互和结果可视化。
-
支持多种主题和语言切换。
-
功能特点
深度文档理解
RAGFlow 能够解析复杂格式的文档,提取高质量的知识片段。它支持以下功能:
-
文档布局分析:识别文档中的表格、图片、标题等结构元素。
-
文本提取:从文档中提取纯文本内容,支持多种语言。
-
知识图谱生成:从文档中提取实体和关系,构建知识图谱。
模板化文本切分
RAGFlow 提供了基于模板的文本切分功能,使切分过程更加智能和可解释:
-
多种模板选择:支持按段落、句子或自定义规则进行切分。
-
可视化切分结果:允许用户查看和调整切分结果,确保切分质量。
减少幻觉引用
通过可视化文本切分和引用追踪,RAGFlow 有效降低了模型产生幻觉信息的可能性:
-
引用来源可视化:用户可以查看生成回答所依据的文档片段。
-
幻觉检测:通过对比生成内容与原始文档,检测潜在的幻觉信息。
多数据源兼容
RAGFlow 支持多种数据源和文件格式,包括但不限于:
-
Office 文档:Word、Excel、PowerPoint。
-
文本文件:TXT、PDF、Markdown。
-
图像和表格:支持从图像中提取文字(OCR)和表格数据。
-
网页内容:支持从网页抓取和解析内容。
自动化 RAG 工作流
RAGFlow 提供了自动化的 RAG 工作流,简化了从文档处理到问答生成的全过程:
-
一站式服务:从文档上传到问答生成,全程自动化。
-
灵活配置:支持自定义 LLM 和嵌入模型,适应不同业务需求。
-
高效检索:结合多种召回策略和融合重排序,提高检索精度。
代码示例
部署 RAGFlow
以下是使用 Docker 部署 RAGFlow 的代码示例:
# 克隆 RAGFlow 仓库
git clone https://github.com/infiniflow/ragflow.git
cd ragflow/docker
# 启动服务(CPU 版本)
docker compose -f docker-compose.yml up -d
# 启动服务(GPU 版本)
# docker compose -f docker-compose-gpu.yml up -d配置服务
修改 service_conf.yaml.template 文件以配置后端服务:
user_default_llm: "openai" # 默认 LLM 服务
openai_api_key: "your-api-key" # OpenAI API 密钥启动后端服务
从源代码启动后端服务的示例:
# 安装依赖
uv sync --python 3.10 --all-extras
# 启动后端服务
source .venv/bin/activate
export PYTHONPATH=$(pwd)
bash docker/launch_backend_service.sh应用场景
文档问答系统
RAGFlow 可以用于构建企业级文档问答系统,帮助用户快速从大量文档中找到所需信息。例如:
-
技术支持:帮助技术人员快速查找文档中的解决方案。
-
法律咨询:从法律文件中提取相关条款和案例。
智能客服
结合 RAGFlow 的文档理解和生成能力,企业可以构建智能客服系统,提供 24/7 的自动化服务。
教育辅导
RAGFlow 可以作为教育工具,帮助学生从教材和讲义中提取知识点,生成学习材料和问答内容。
知识管理
企业可以利用 RAGFlow 构建知识库,存储和管理大量文档,并通过问答接口快速检索知识。
注意事项
硬件要求
RAGFlow 对硬件资源有一定要求,建议配置如下:
-
CPU:至少 4 核心
-
内存:至少 16 GB
-
存储:至少 50 GB 空闲空间
-
GPU(可选):用于加速嵌入和文档处理任务
模型选择
RAGFlow 支持多种 LLM 和嵌入模型,用户需要根据实际需求选择合适的模型:
-
OpenAI:适合高质量问答,但需要 API 密钥。
-
DeepSeek:开源模型,适合本地部署。
数据隐私
由于 RAGFlow 会处理大量文档数据,用户需要确保数据的安全性和隐私保护:
-
本地部署:建议在本地服务器上部署,避免数据传输到第三方平台。
-
访问控制:限制对 RAGFlow 服务的访问权限,防止未授权访问。
总结
RAGFlow 作为一款开源的 RAG 引擎,凭借其深度文档理解和灵活的架构设计,为企业和个人提供了一种高效的文档问答解决方案。它不仅支持多种数据源和文件格式,还通过减少幻觉引用和可视化切分结果,提高了问答的准确性和可靠性。通过 Docker 和本地部署的多种选项,RAGFlow 可以适应不同规模和需求的业务场景。未来,随着 AI 技术的不断发展,RAGFlow 有望在更多领域发挥其潜力,推动知识管理和文档处理的创新。



















 2617
2617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











